By: John Miner | Updated: 2023-08-30 | Comments (1) | Related: > Azure Synapse Analytics
Problem
Many organizations are consolidating all their informational assets into a data lake. This is a great idea since all the structured and unstructured data can be stored in one location, and many types of users can access the data.
Traditionally, a SPARK cluster is used to manipulate the data stored in the lake via quality zones. This data engineering batch process can be scheduled at night. The more powerful the SPARK cluster is, the more costly the Azure bill. Since most data is written once and read many times, how can we reduce the cost of our company's reading activities?
Solution
Azure Synapse Analytics, Serverless SQL pools allow the architect to replace the interactive SPARK cluster with a lower cost service. The OPENROWSET and EXTERNAL TABLE commands have traditionally used POLYBASE to read schema on demand. However, this syntax can be time-consuming to set up. Microsoft recently released the Lake Database that abstracts this underlying mechanism via the Azure Portal and/or SPARK engine. Shown below is a high-level architecture diagram of Synapse Serverless Pools.

Business Problem
Our manager has asked us to investigate how to read data stored in an Azure Data Lake using Azure Synapse Analytics to reduce our overall cost. Because most staff are familiar with Microsoft SQL Server, focusing the investigation on Serverless SQL Pools and Databases makes sense.
Here is a list of tasks that we need to investigate and solve.
| Task Id | Description |
|---|---|
| 1 | Create test environment |
| 2 | Explore the data lake |
| 3 | Define test database |
| 4 | Secure test database (windows security) |
| 5 | Define complete database |
| 6 | Secure complete database (standard security) |
At the end of the research, we will understand how to manage SQL Serverless Databases using Azure Synapse Analytics.
Create Test Environment
This section will review tasks that must be performed before creating SQL databases in the serverless pool. The image below shows a dashboard that was created for this article. I assume you know how to deploy Azure Services using the Azure Portal. For our experiments, we need a storage account configured for Azure Data Lake Storage and the Azure Synapse Workspace. Additionally, we will want to test access to the database using a virtual machine with SQL Server Management Studio (SSMS) installed as an application.

The following objects have been deployed and configured in our test environment:
- wsn4synapse – the Azure Synapse workspace.
- vm4sql19 – a virtual Windows server that has SSMS installed.
- sa4adls2030 – a storage account that has data lake containers.
- sc4adls2030 – a storage container with hierarchical name spaces enabled.
When deploying Azure Synapse, one is required to create local storage. We will talk about that later in the article.
The image below shows the details for the Azure Synapse Analytics workspace. Here is some important information to retain from this page. First, every deployment requires the data engineer to create a SQL administrator account. I chose to pick the name sqladminuser for the account and have the password checked into a private key vault. We will use this information later in the article. Every workspace automatically has a Serverless SQL pool deployed. However, we need to know the endpoint of this pool to check our access via SSMS. Look for the URL under the Serverless SQL endpoint.

It is very easy to deploy services via the Azure Portal. I suggest using a deployment language such as Azure Command Line (ACL) interface for consistent deployments with a known configuration. Now that we have a test environment, we can explore the data lake using the Synapse Analytics Workspace.
Explore the Data Lake
One of the cool things about the Synapse Analytics Workspace is that files in the data lake can be explored visually. That means the interface designers assumed a no-code approach and/or no knowledge. Let's start our exploration now.
Open Synapse Studio. The second icon on the left represents data associated with the workspace. We can see two categories:
- Workspace – which contains both SQL and SPARK databases; and
- Linked – which contains connections to other services.
The hive database in SPARK always has a default database and is created once a PySpark SQL cluster creates the first database.

The linked (services) data pane can be seen below. You are asked to create a storage container when deploying Azure Synapse Analytics. Thus, the object called sa4synapse was created during the deployment of the service. On the other hand, the object named ls_adls_gen2_datalake was created by me to point to an existing data lake.

If we click on the three ellipses, we can edit the connection's properties, if possible. This technology is tied to Azure Data Factory since it shows the Auto Resolve Integration Runtime. After configuring a linked service, we always want to test the connection.

Expand the linked service definition ls_adls_gen2_datalake to explore the data lake storage. We can see that five storage containers are defined within our storage account.

Under the primary storage container (sc4adls2030), we can find a directory called synapse. This has the data files used for the article. Two types of data files are saved in two subdirectories: Apache Parquet and comma separated values (CSV). The CSV file called access-control-file.csv, located at the root of the folder, is used to set up access for a SPARK database. It will be discussed in the next article.

Drill into the csv-files directory. We can see data files representing the SALES LT schema for Adventure Works. Each file represents either a dimension or fact table in the dimensional model.

Right-click on the DimCurrency.csv file, select New SQL script, Select TOP 100 rows, and then click Run. There may be a prompt to supply the file type if the workspace is unable to identify it.
Switch over to the parquet directory. SPARK data files are comprised of multiple files, and each file that represents a table should reside in a folder, as seen in the following screenshot representing the prompt to identify the type of file located in the folder.

At the beginning of the article, I mentioned that the OPENROWSET function can be used for schema on read operations. You might ask why I am not supplying schema details when accessing the Parquet file. The Parquet file format is considered a strong file format since field names are defined, and field sizes are specified as part of the file. Other features include optional compression, optional split files, and files stored as binary, making it harder for the format to be hacked.

As shown above, the T-SQL code reads in the parquet directory for currency data using the OPENROWSET command. Below, the T-SQL code reads in a CSV file, providing information about the header and field separators. The comma separated values (CSV) is considered a weak file format. Most data engineers have experienced firsthand issues with processing a delimited file because the reserved field delimiter occurred within a field of the file. Of course, the unwanted character breaks the parsing of the file by the extract, translate, and load (ETL) program. Another non-optimal feature of the format is that the data type of a given field must be inferred from the file. The Azure Synapse Workspace does not infer the schema of a CSV formatted file and instead requires the column definitions to be supplied.

While the OPENROWSET command is great for ad-hoc data analysis, how can we expose the files in the data lake permanently so that closing and opening a new session in SSMS has no effect on reading the external data?
Define Test Database
The serverless pool, once called Azure SQL Warehouse, accepts the same T-SQL as a dedicated pool. Let's start our exploration by executing two simple tasks using T-SQL. Who am I logged in as, and what are the databases in the pool? Please see the code below for details.
-- -- 0 – Simple environment queries -- -- Switch database USE master; GO -- Who am I logged in as? SELECT CURRENT_USER as CUR_USER, SYSTEM_USER as SYS_USER; GO -- What are the database names? SELECT * FROM sys.databases; GO
The image below shows that I am logged into the Azure Synapse Workspace using Azure Active Directory. The account named [email protected] is considered a database owner (dbo).

The image below shows both the master database known in SQL Server and the default database known in the hive catalog used by SPARK.

In our database design, we will create the database for use with Active Directory Credential pass through to Azure Data Lake Storage. First, we want to remove any existing databases named mssqltips. Then we want to create and use our new database called mssqltips. The code snippet below executes these two actions.
-- -- 1 - Drop existing database -- -- Switch database 2 master USE master; GO -- Remove existing database DROP DATABASE IF EXISTS mssqltips; GO -- -- 2 - Create new database -- -- Create new database CREATE DATABASE mssqltips; GO -- Switch database 2 mssqltips USE mssqltips; GO
Each serverless SQL database can have five different object types: external tables, external resources, views, schemas, and security. See the image below for a visualization of our SQL database from Synapse Workspace.

We want to create an external data source pointing to the storage URL defined in our linked service.
-- -- 2 - Create external data source -- -- Depends on managed identity having access to adls gen2 account/container CREATE EXTERNAL DATA SOURCE [LakeDataSource] WITH ( LOCATION = 'abfss://[email protected]' ) GO
Additionally, we want to create external file formats for both parquet and CSV.
--
-- 3 - Create external file formats
--
-- Delimited files
CREATE EXTERNAL FILE FORMAT [DelimitedFile]
WITH
(
FORMAT_TYPE = DELIMITEDTEXT ,
FORMAT_OPTIONS
(
FIELD_TERMINATOR = '|',
USE_TYPE_DEFAULT = FALSE
)
)
GO
-- Parquet files
CREATE EXTERNAL FILE FORMAT [ParquetFile]
WITH
(
FORMAT_TYPE = PARQUET
)
GO
The image below shows the results of executing the three T-SQL transactions.

The next task is to create an external table definition for our CSV data file. In this example, we will be reading the currency data. Execute the code below to create the table.
--
-- 4 - Create external table
--
-- Drop old table
DROP EXTERNAL TABLE dim_currency;
GO
-- Create new table
CREATE EXTERNAL TABLE dim_currency
(
CurrencyKey int,
CurrencyAlternateKey nvarchar(3),
CurrencyName nvarchar(50)
)
WITH
(
LOCATION = 'synapse/csv-files/DimCurrency.csv',
DATA_SOURCE = [LakeDataSource],
FILE_FORMAT = [DelimitedFile]
)
GO
The second task is to create an external table for our parquet directory that contains internal sales data.
--
-- 5 - Create external table
--
CREATE EXTERNAL TABLE fact_internet_sales
(
[ProductKey] [int],
[OrderDateKey] [int],
[DueDateKey] [int],
[ShipDateKey] [int],
[CustomerKey] [int],
[PromotionKey] [int],
[CurrencyKey] [int],
[SalesTerritoryKey] [int],
[SalesOrderNumber] [nvarchar](20),
[SalesOrderLineNumber] [tinyint],
[RevisionNumber] [tinyint],
[OrderQuantity] [smallint],
[UnitPrice] [money],
[ExtendedAmount] [money],
[UnitPriceDiscountPct] DECIMAL(19, 4),
[DiscountAmount] DECIMAL(19, 4),
[ProductStandardCost] [money],
[TotalProductCost] [money],
[SalesAmount] [money],
[TaxAmt] [money],
[Freight] [money],
[CarrierTrackingNumber] [nvarchar](25),
[CustomerPONumber] [nvarchar](25),
[OrderDate] [datetime],
[DueDate] [datetime],
[ShipDate] [datetime]
)
WITH
(
LOCATION = 'synapse/parquet-files/FactInternetSales/**',
DATA_SOURCE = [LakeDataSource],
FILE_FORMAT = [ParquetFile]
)
GO
We always want to test after executing our code. The image below was taken from the Synapse Workspace. We can see that the two tables are now created.

The POLYBASE engine uses three commands to expose our files as tables: CREATE EXTERNAL DATA SOURCE, CREATE EXTERNAL FILE FORMAT, and CREATE EXTERNAL TABLE. Executing these commands in the correct order will create our SQL Serverless database in Azure Synapse.
Secure Test Database
The first database design will be using Azure Active Directory pass through authentication. I will review what a standard Azure Synapse account can do versus an active directory account. We know that the sqladminuser account was created as a standard account. Let's use SSMS on our virtual machine to test connectivity to our Serverless pool. Ensure you get the end point from the properties page for the serverless pool. The image below shows the typical connection window.

The standard admin account can log into the database and see the tables in the database but can't select any data from the table. This is because the standard account does not have access to the storage location.
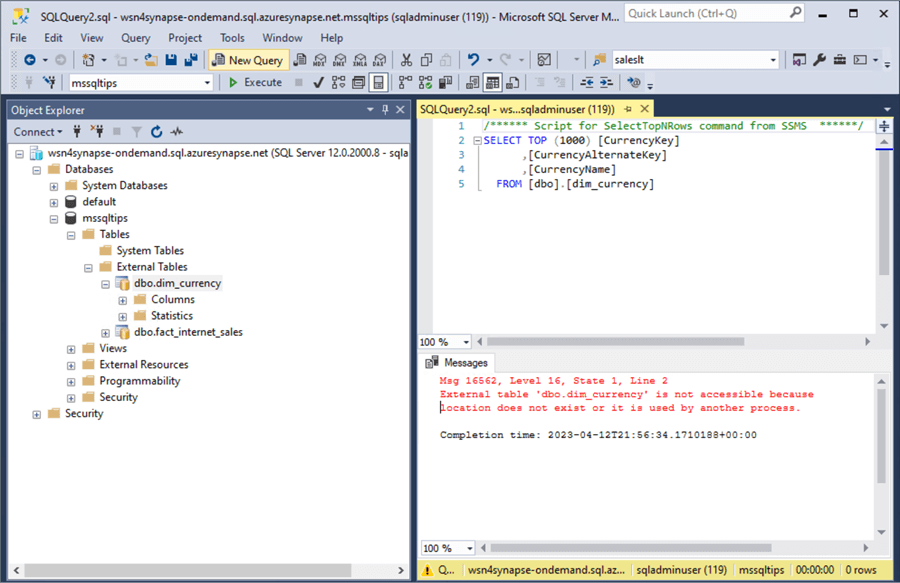
At this time, I will add [email protected] as a Synapse SQL Administrator via the access control panel in Synapse Analytics.

Giving a user access to Azure Data Lake Storage is a two-step process. First, we must give the user RBAC – role-based access security rights using the IAM page. See the image below for details. Usually, Storage Blob Data Contributor is enough to read and write to files in the data lake.
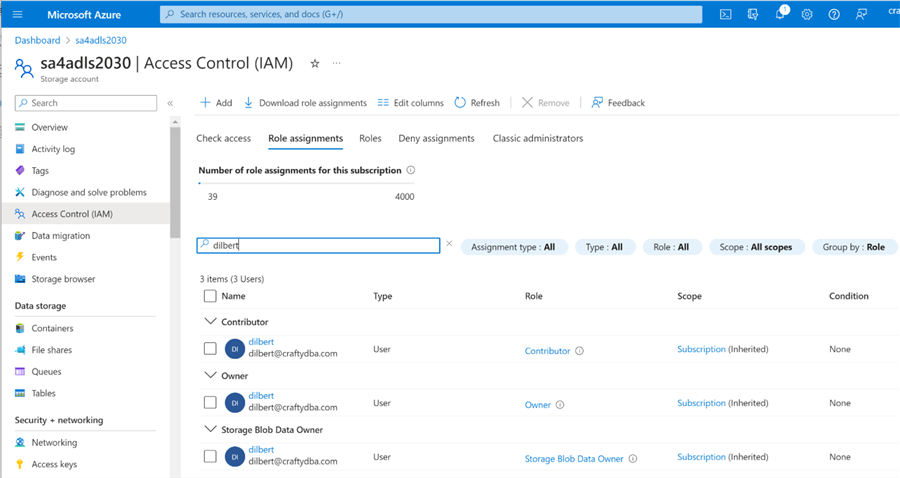
The second step is to use Azure Storage Explorer to give [email protected] access control list (ACL) rights to the synapse folder under the sc4adls2030 container. If there are existing files or folders, you want to propagate the rights from the root folder down to the leaf files.

Now, let's test using our account. The screen below shows a connection page filled out for the user named [email protected].

The last step is to try to execute a SELECT query against the currency table. The image shows the successful execution of the query against the external table. In turn, the POLYBASE engine uses the Active Directory credentials to validate that the user has rights to read the file as a table.

What have we learned with this security model? If you add users one at a time to the database, you must manage the security of the data lake. This can be time-consuming. Instead, use Azure Active Directory groups instead of users for a one-time setup. Next, we will investigate how to configure standard security for a Serverless Database.
Define Complete Database
The complete data files for the SALES LT database from Microsoft do exist in our Data Lake. The next step is to create a complete database using these files. However, we need to consider how to define security using a shared access signature (SAS) key.
The code below creates a master key and a database scoped credential. This credential is how we can access the storage layer without worrying about RBAC and ACL rights.
-- -- 6 - create master key / database scoped credential -- -- Drop if required DROP MASTER KEY; GO -- Create master key CREATE MASTER KEY ENCRYPTION BY PASSWORD='AcEADre5eHJvEcWFhUf8'; GO -- Drop if required DROP DATABASE SCOPED CREDENTIAL [LakeCredential]; GO -- Create a database scoped credential. CREATE DATABASE SCOPED CREDENTIAL [LakeCredential] WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'sp=rl&st=2023-01-25T19:10:08Z&se=2024-01-01T03:10:08Z&spr=https&sv=2021-06-08&sr=c&sig=OcSmdA6WPlCA5LUf3JXM%2F34v8pQgWtPH2NA1MyDT5aI%3D'; -- Show credentials SELECT NAME FROM sys.database_scoped_credentials; GO
The output from the SELECT statement shows that our credential exists in the database.
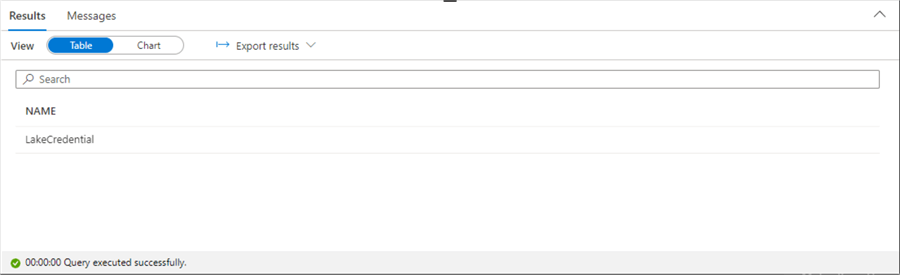
To use the SAS key, we must change the "LakeDataSource" External Data Source previously created using the CREATE EXTERNAL DATA SOURCE code using the LakeCredential that was just defined. The code below does just that.
-- -- 7 - create data source -- -- Drop if required DROP EXTERNAL DATA SOURCE [LakeDataSource]; GO -- Create if required CREATE EXTERNAL DATA SOURCE [LakeDataSource] WITH ( LOCATION = 'https://sa4adls2030.dfs.core.windows.net/sc4adls2030/', CREDENTIAL = [LakeCredential] ) GO -- Show data sources SELECT * FROM sys.external_data_sources; GO
The screenshot below shows the newly defined data source.

I will only post the CREATE EXTERNAL TABLE statement for one table. All other tables follow a similar pattern. All tables will go into a single schema named saleslt.
Below is a code snippet to create the new schema. Using dbo is not a best practice.
-- -- 8 - create data source -- CREATE SCHEMA [saleslt]; GO
The code below creates an external table for the currency dimension using the parquet data files.
-- -- 9 – create table – currency -- -- Drop if required DROP EXTERNAL TABLE [saleslt].[dim_currency] GO -- Create table CREATE EXTERNAL TABLE [saleslt].[dim_currency] ( [CurrencyKey] [int], [CurrencyAlternateKey] [nvarchar](3), [CurrencyName] [nvarchar](50) ) WITH ( LOCATION = ‘synapse/parquet-files/DimCurrency/**', DATA_SOURCE = [LakeDataSource], FILE_FORMAT = [ParquetFile] ) GO -- Show data SELECT * FROM [saleslt].[dim_currency]; GO
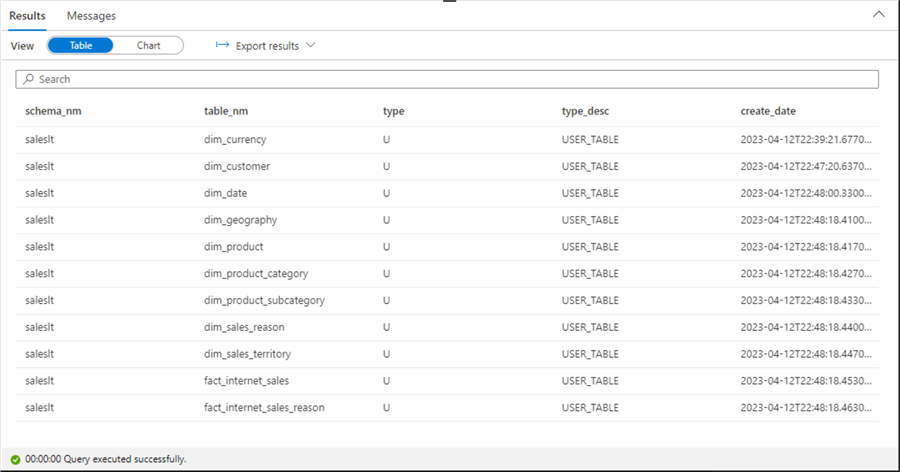
Last, we can query the system tables to obtain a list of our user-defined tables.
--
-- 10 – create table – currency
--
SELECT
S.NAME AS schema_nm,
O.NAME AS table_nm,
O.type,
O.type_desc,
O.create_date
FROM
SYS.SCHEMAS S JOIN SYS.OBJECTS O
ON
S.SCHEMA_ID = O.SCHEMA_ID
WHERE
IS_MS_SHIPPED = 0;
The image below shows the 11 tables that are part of the SALES LT database.
During the quality assurance process, one must ensure that the record counts match the file rows. This can be done by executing a union of SELECT statements that return row counts by table name. The image below shows the execution of a query.

A view can be used to package up complex T-SQL statements into a simple object that can be queried. The code below creates a view named rpt_prepared_data that joins many tables to report on sales data.
--
-- 11 – Create a view
--
CREATE VIEW [saleslt].rpt_prepared_data
AS
SELECT
pc.EnglishProductCategoryName
,Coalesce(p.ModelName, p.EnglishProductName) AS Model
,c.CustomerKey
,s.SalesTerritoryGroup AS Region
,DATEDIFF(DAY, c.BirthDate, current_timestamp) / 365.25 AS Age
,CASE
WHEN c.YearlyIncome < 40000 THEN ‘Low'
WHEN c.YearlyIncome > 60000 THEN ‘High'
ELSE ‘Moderate'
END AS IncomeGroup
,d.CalendarYear
,d.FiscalYear
,d.MonthNumberOfYear AS Month
,f.SalesOrderNumber AS OrderNumber
,f.SalesOrderLineNumber AS LineNumber
,f.OrderQuantity AS Quantity
,f.ExtendedAmount AS Amount
FROM
[saleslt].fact_internet_sales as f
INNER JOIN
[saleslt].dim_date as d
ON
f.OrderDateKey = d.DateKey
INNER JOIN
[saleslt].dim_product as p
ON
f.ProductKey = p.ProductKey
INNER JOIN
[saleslt].dim_product_subcategory as psc
ON
p.ProductSubcategoryKey = psc.ProductSubcategoryKey
INNER JOIN
[saleslt].dim_product_category as pc
ON
psc.ProductCategoryKey = pc.ProductCategoryKey
INNER JOIN
[saleslt].dim_customer as c
ON
f.CustomerKey = c.CustomerKey
INNER JOIN
[saleslt].dim_geography as g
ON
c.GeographyKey = g.GeographyKey
INNER JOIN
[saleslt].dim_sales_territory as s
ON
g.SalesTerritoryKey = s.SalesTerritoryKey
GO
The T-SQL below summarizes sales by year, month, region, and model number. Given this information, the sales manager can see what products are being sold monthly.
-- -- 12 – Use view in aggregation -- SELECT CalendarYear as RptYear, Month as RptMonth, Region as RptRegion, Model as ModelNo, SUM(Quantity) as TotalQty, SUM(Amount) as TotalAmt FROM [saleslt].rpt_prepared_data GROUP BY CalendarYear, Month, Region, Model ORDER BY CalendarYear, Month, Region; GO
The output of the query is shown below.

To recap, one must create and use a database credential in the data source definition to leverage standard security. So far, we have created and tested the schema using the login I used within the Azure Synapse environment. Next, we will test with a login created for standard security.
Secure Complete Database
The Synapse Serverless Pools use the same standard security pattern released with SQL Server 2005. The administrator creates a server login in the master database. Then, a database user is created off the server login. The code below creates the server login for Dogbert.
-- -- 13 – create a login -- -- Which database? USE master; GO -- Drop login DROP LOGIN [Dogbert] -- Create login CREATE LOGIN [Dogbert] WITH PASSWORD = ‘sQer9wEBVGZjQWjd', DEFAULT_DATABASE = mssqltips; GO -- Show logins SELECT * FROM sys.sql_logins GO
The code below creates the database user for Dogbert in the mssqltips database with data reader rights.
-- -- 14 – create a user -- -- Which database? USE mssqltips; GO -- What are the principles SELECT * FROM sys.database_principals where (type=‘S' or type = ‘U') GO -- Drop user DROP USER [Dogbert]; GO -- Create user CREATE USER [Dogbert] FROM LOGIN [Dogbert]; GO -- Give read rights ALTER ROLE db_datareader ADD MEMBER [Dogbert]; GO
Now, let's see if our security works! The image below shows a login attempt using the Dogbert account.

The account can see all the tables and views defined in the mssqltips database. However, we get an error message if we query the currency table. This is because the standard user does not have access to the database credential.

This can be easily fixed by executing the following T-SQL script:
-- -- 15 – give user rights to credential -- -- Give rights to credential GRANT CONTROL ON DATABASE SCOPED CREDENTIAL :: [LakeCredential] TO [Dogbert]; GO
If we execute the query again, the result set is returned without system errors.

Using standard security with a Serverless Synapse pool is like turning the clock back to 2005. However, do not forget to give the user access to the database credential. Otherwise, a system error will pop up when you execute the query.
Summary
Many companies are creating data lakes in the Azure Cloud. It can be expensive to leave up a Spark cluster for data engineering and reporting needs. One way to reduce costs is to use Azure Synapse Serverless Pools to query the data lake.
Databases and tables can be created by both T-SQL and/or PySpark. Views, on the other hand, are only supported by a SQL database. Today, we explored how to create and secure a SQL database for the SALES LT data files. This serverless technology supports Azure Active Directory authentication pass through and Stand Security Logins/Users. The first security protocol requires the management of permissions using both RBAC and ACL. The second security protocol requires a SAS key. Don't forget that SAS keys have an expiration date.
Currently, this technology only allows reading files in the data lake. You can execute a create a table as (CTAS) statement; however, this is not that different from creating a view. The only benefit is that the results are stored as a table in storage. Today, we focused on creating a serverless SQL database and found that it was not hard. Next time, we will explore creating a Lake House database using the Spark engine within Azure Synapse.
Enclosed are the following artifacts to start your journey with Azure Synapse Serverless SQL Databases: csv files, parquet files, and T-SQL code.
Next Steps
- Learn how to create a Lake House database using Synapse Spark.
- Read these additional Azure Synapse Analytics Tips






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-08-30
