By: Temidayo Omoniyi | Updated: 2023-09-06 | Comments | Related: > Azure Databricks
Problem
Today's data hardly comes in a structured format, making it difficult for most data professionals to manage. Data are usually of three forms: structured, semi-structured, and unstructured format. Data from Application Programming Interfaces (APIs) are mostly in JSON format. It is frequently used for data exchange between clients (as web and mobile applications) and servers. JSON is said to be a simple and lightweight structure that makes it easy for machines to process and create, while JSONs human-readable format makes it straightforward for developers to work on. In this article, we look at how to use these data formats with Databricks.
Solution
Utilizing cloud-based platforms such as Databricks provides an integrated solution for data analytics, data engineering, and machine learning, all powered by the underlying capabilities of Apache Spark.
The Spark API provides an efficient way of reading and processing JSON files. Using the Spark API, users can leverage the power of distributed computing to handle large-scale JSON data.
It should be noted that this project supports all PySpark libraries, meaning all code should work on the user's local machine if PySpark is installed.
Advantages of Using Spark with JSON Files
Spark provides several benefits for reading and writing JSON files, especially when working with massive amounts of data and distributed processing, including:
- Scalability: Spark can be used in handling large JSON datasets. This is possible because Spark can split up the JSON file processing over several cluster nodes, i.e., it scales horizontally by adding more nodes to the cluster.
- Flexibility: Spark's flexibility empowers users to seamlessly read and write JSON files in diverse formats, including nested JSON and multiline structures, while effortlessly extracting data from various sources.
- Schema Inference: Automatically infer the schema of a JSON file, thereby saving time and effort of manually specifying the structure of the data.
- Parallel Processing: Spark distributes the processing of JSON files across a cluster of machines, enabling parallelism and significant acceleration of data reading and writing operations.
Read Different JSON Formats
For this article, we will be managing different JSON formats in Databricks. Databricks supports a wide range of data formats.
Mount Azure Storage Endpoint
Before we can work on Azure Databricks, we must first mount storage to it. Our previous article explains how to mount different Azure storage to the Azure Databricks.
For this article, we will use the Azure Datalake Gen 2 as our primary storage. You can check the different mounts on your Databricks using the dbutils command. The dbutils command provides various utilities available in Databricks, ranging from Secret management, File system operations, Notebook chaining, and External service integration.
#Check for all the mount point folders display(dbutils.fs.mounts())

Task 1: Read Single Line JSON File
A single-line JSON file is usually formatted on a single line without any line breaks or spaces. We will read this file in our Azure Databricks.
{"id":1,"name":"John Doe","age":30,"email":"[email protected]"}
{"id":2,"name":"Jane Smith","age":28,"email":"[email protected]"}
{"id":3,"name":"David Brown","age":45,"email":"[email protected]"}
{"id":4,"name":"Emily Johnson","age":22,"email":"[email protected]"}
{"id":5,"name":"Michael Lee","age":34,"email":"[email protected]"}
{"id":6,"name":"Sophia Wilson","age":27,"email":"[email protected]"}
{"id":7,"name":"Daniel Martinez","age":40,"email":"[email protected]"}
{"id":8,"name":"Olivia Adams","age":29,"email":"[email protected]"}
{"id":9,"name":"James Taylor","age":38,"email":"[email protected]"}
{"id":10,"name":"Isabella White","age":25,"email":"[email protected]"}
Step 1: Read JSON File
Databricks runs on Apache Spark, a powerful open-source distributed computing framework that provides a programming interface with implicit data parallelism and fault tolerance for entire clusters.
Using Spark, the syntax spark.read() can be used to read a variety of data sources such as CSV, JSON, Parquet, Avro, ORC, JDBC, and numerous others. The spark.read() syntax below shows that data can be read using Spark.
spark.read().format("data_source").option("option_name", "option_value").load("file_path")
The line of code is used to read the single-line JSON file from the Azure Data Lake Gen 2 mount point.
#Read JSON file using spark.read()
singlejson_df = spark.read.json("/mnt/adfdatalakeurbizedge/bronzeunitycatalog/single.json")
Now let's view the data just by using the display function in PySpark.
#To display value display(singlejson_df)

The output shows that the data column has been re-arranged from the original JSON file, which can be caused by many factors, including Schema Evolution. Schema Evolution occurs when Spark tries to deduce the data's schema (column names and data types). Columns may be altered by Spark's schema inference if the JSON data's structure varies between different records.
To maintain consistent column ordering, you can fix this by explicitly specifying a schema when reading the JSON file. By doing this, you are validating the structure and schema you want Spark to follow.
Step 2: Set Data Schema
To prevent data fields from re-arrangement, we need to set a schema, which helps validate the entire data structure expected.
Firstly, we need to import all necessary libraries for PySpark SQL types.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
Now let's set the structure for the dataframe individual fields.

Lastly, read the JSON file in the mount point with the schema we just created.
single_standard = spark.read. schema(single_schema) .json("/mnt/adfdatalakeurbizedge/bronzeunitycatalog/single.json")

Step 3: Create a TempView
TempView in Spark is a temporary view or table created on a current SparkSession. It is like a genuine SQL table but not stored on disk. As a result, the information in the temporary view is only accessible during the current SparkSession and will be removed once the SparkSession ends. TempView can be created using the createOrReplaceTempView() function.
single_standard.createOrReplaceTempView("temp_view_single") #Create TempView
Query TempView Table. Databricks notebooks allow users to switch between different programming languages using the magic command. These instructions run code written in a particular language inside a notebook cell. With the help of the following magic commands, you can switch between Python and SQL or Scala.

Task 2: Read Nested JSON File
Now we are going to read a nested JSON file. This is otherwise known as a hierarchical or nested data structure. These are objects nested inside another object, which provides more intricate and structured data representations. The nested JSON structure allows you to define relationships and hierarchies between several data types by enabling values to be other JSON objects or arrays.
{"id":1,"name":{"first_name":"John","last_name":"Doe"},"age":30,"contact":{"email":"[email protected]"}}
{"id":2,"name":{"first_name":"Jane","last_name":"Smith"},"age":28,"contact":{"email":"[email protected]"}}
{"id":3,"name":{"first_name":"David","last_name":"Brown"},"age":45,"contact":{"email":"[email protected]"}}
{"id":4,"name":{"first_name":"Emily","last_name":"Johnson"},"age":22,"contact":{"email":"[email protected]"}}
{"id":5,"name":{"first_name":"Michael","last_name":"Lee"},"age":34,"contact":{"email":"[email protected]"}}
{"id":6,"name":{"first_name":"Sophia","last_name":"Wilson"},"age":27,"contact":{"email":"[email protected]"}}
{"id":7,"name":{"first_name":"Daniel","last_name":"Martinez"},"age":40,"contact":{"email":"[email protected]"}}
{"id":8,"name":{"first_name":"Olivia","last_name":"Adams"},"age":29,"contact":{"email":"[email protected]"}}
{"id":9,"name":{"first_name":"James","last_name":"Taylor"},"age":38,"contact":{"email":"[email protected]"}}
{"id":10,"name":{"first_name":"Isabella","last_name":"White"},"age":25,"contact":{"email":"[email protected]"}}
Step 1: Read the Nested JSON File
Using the spark.read() function, read the nested JSON file from the data mount point in your Azure storage.
#Read JSON file using spark.read()
nestedjson_df = spark.read.json("/mnt/adfdatalakeurbizedge/bronzeunitycatalog/Nested_JSON.json")
You will notice a nested JSON when you display the Dataframe on the contact and name fields.

Step 2: Set Data Schema
We must set a unique data schema for both the contact and name fields to remove the nested JSON file.
Let's start by importing the necessary libraries needed.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DateType
Now, set a schema for both the contact and name fields.

With the individual column schema set, we now need to set a structure for the dataframe.

Now, read the JSON file with the schema just created, and concat both the first name and last name to a single column called name.


Step 3: Display Transformed DataFrame
The DataFrame's contents can be tabulated and displayed using the display() command.

Task 3: Read Multi-line JSON File
Spark provides you with the ability to read both single and multi-line JSON. A file is loaded in multi-line mode as a single unit and cannot be divided.
Let's read the multi-line JSON file by using Databricks Spark.
[
{
"id": 1,
"name": "John Doe",
"age": 30,
"email": "[email protected]"
},
{
"id": 2,
"name": "Jane Smith",
"age": 28,
"email": "[email protected]"
},
{
"id": 3,
"name": "David Brown",
"age": 45,
"email": "[email protected]"
}
]
Step 1: Read Multi-line JSON.
To read the multi-line JSON file, the line of code should be used below.
#Read JSON file using spark.read()
multiline_df = spark.read.json("/mnt/adfdatalakeurbizedge/bronzeunitycatalog/Multiline.json")
After successfully reading the JSON file, let's display our data using the display command. You will notice that the file is corrupted due to its structure, but this is not something to worry about. Open the file in any text editor to better understand the data.

Step 2: Set Data Schema
We must create a schema for all the individual fields to read the multi-line JSON file.
The line of code below will help set the schema structure we want to use.

With the schema structure created, now read the multi-line JSON file from the mount point and set the parameter option to multiline.

Let's create a TempView that provides a temporary table view of our multiline data.
multiline_nested.createOrReplaceTempView("temp_view_multiline")
Step 3: Run Spark SQL Command
The Spark.SQL()command is used to execute SQL-like queries on Spark SQL Table or Dataframe. It enables you to conduct different operations such as filtering, aggregating, joining, and more on structured data using a syntax like SQL.

Task 4: Read JSON File from Folder
Reading data from a folder is a unique feature that allows you to append data from multiple tables into a single table. This operation is also dynamic as it adds new records to the data table.
The steps below will help us read JSON data from a folder:
Step 1: Set Data Schema
This can be done by importing all the necessary libraries to set the structure.
#Import all necessary Libraries from pyspark.sql.types import StructType, StructField, IntegerType, StringType
Set the schema for both the nested fields.


After setting the schema for the email and name fields, let's add it to the data structure.

Step 2: Read Folder
Reading the folder will automatically append the entire data in that folder. The line of code below will help read the data from the mount point folder.

After reading the folder, use the .show() command to display the read data.

Now, let's set the column structure by using the withColumn command.

Use the display function to view the append data.
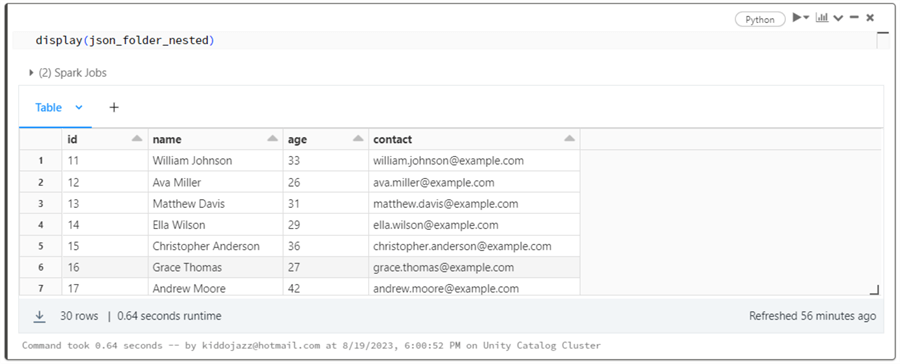
Step 3: Query Data
SQL queries work on structure data, so we must create a table from the DataFrame.
The line of code below will help create a virtual table called temp_view_folder.
json_folder_nested.createOrReplaceTempView("temp_view_folder")

To get the total number of rows, use the count command in SQL.
%sql select count(*) from temp_view_folder

Task 5: Read Excel File
Spark provides users with the ability to read different file types. To read Excel files in Spark, we can use two methods.
Method A
The first method uses the Pandas library to read the data in a Pandas DataFrame and converts the created DataFrame to a Spark DataFrame.
Pandas is a free, open-source Python library that offers tools for analyzing and manipulating structured data.
Step 1: Install and Import all Necessary Libraries.
To work with Excel on Databricks, we need to install the Openpyxl library. Openpyxl is a free and open-source library that allows users to read and write in Excel 2010 and above.
%pip install openpyxl

After you have installed the necessary libraries, we import the Pandas library back to our Notebook.
#Import the pandas library import pandas as pd
Step 2: Setting Up Databricks File Storage.
A distributed file system that can be mounted into the Databricks workspace and used on Databricks clusters is called the Databricks File System (DBFS).
To enable the DBFS, click on Admin Settings from your Databricks workspace. This should take you to another window.

In your Admin Settings, navigate to the Workspace settings and search for DBFS.
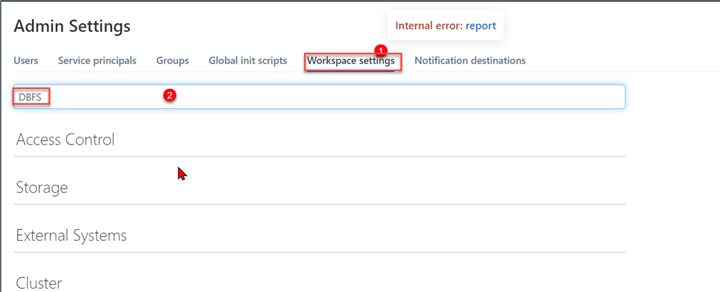
Scroll down and enable the DBFS in the Advanced area. Ensure you "Refresh" the browser tab for all the settings to be fully effective.

Now that we have successfully activated the DBFS, let's upload an Excel file.
From your Databricks workspace, click on Data, navigate to the top right corner, and select Browse DBFS.
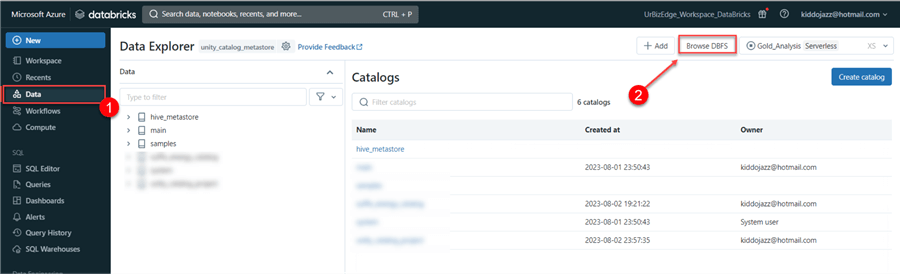
A new window will appear. Click the Upload button, navigate to the desktop, and select the file on your local machine.
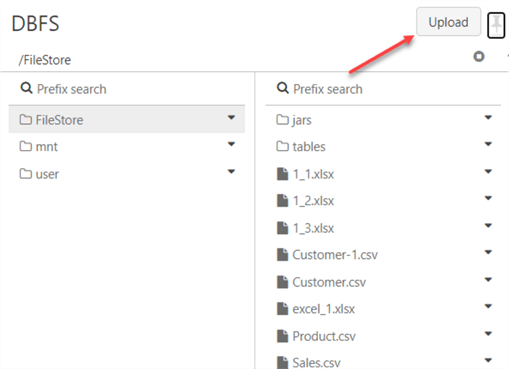
Step 3: Interact with Uploaded Files.
Now that the files are uploaded, head back to the notebook and write the following lines of code.
The first line of code will show the user all the files available in the Databricks file system.


Step 4: Read the Excel File.
Now that we know the File Format API location, read the file using Pandas.
# Read Excel File Path
excel_df = pd.read_excel("/dbfs/FileStore/excel_1.xlsx", engine='openpyxl')

The excel_df.shape gives you the number of rows and columns of the data itself.
To work with the file in Databricks, we need to convert the Pandas DataFrame to a PySpark DataFrame using the command spark.createDataFrame().

In this method, Excel files are read using the Pandas library's power, and the resulting Pandas DataFrame is converted to a PySpark DataFrame for further processing with Spark.
Keep in mind that Pandas may not manage all Excel features or formats correctly while reading files in Excel. Always check whether your data and Excel files work with this methodology.
Method B
For this method, we will use the com.crealytics.spark.excel library. Excel files can be read into a Spark DataFrame using the Spark DataFrame reader provided by this package.
For us to use the dependency method, we will need to follow the steps listed below.
Step 1: Install the Library.
To Install the com.crealytics.spark.excel library, click on Compute in your Databricks workspace, and select your running cluster.

Go to the Libraries tab in the Cluster and click Install new.

The Maven Library source is a way to install external libraries and packages to a Databricks cluster using the Maven Coordinates. In the Maven tab, click on Search Packages. This should take you to another window.

In the Search Packages window, search for Spark-excel and select the Scala version of your cluster. For us, we are using Databricks Runtime Version 12.2 LTS (includes Apache Spark 3.3.2, Scala 2.12). After selecting the appropriate version for your cluster, install the library.

After installation, you should see the library installed in your cluster.

Step 2: Read the Excel File.
The code below can be used to read the Excel file using the com.crealytics.spark.excel library.

Conclusion
In this article, we have learned diverse ways to import different file formats of JSON into Databricks Spark. We also imported data from an Excel file, which involved installing the com.crealytics.spark.excel library from Maven.
We created a TempView, discussed its importance, and how it works with Databricks clusters. The SQL magic command was introduced to help users switch between different languages in a single notebook.
Next Steps
- Databricks Lakehouse Fundamentals
- Databricks Unity Catalog
- Check out related articles:






About the author
 Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience.
Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-09-06
