By: Rajendra Gupta | Updated: 2023-09-19 | Comments | Related: > Amazon AWS
Problem
Amazon Web Services (AWS) is a popular cloud service for deploying infrastructure and applications with scalability, flexibility, and reliability. You can also use serverless computing to run codes without deploying any server. Amazon Athena is one such serverless computing application. This tip will introduce SQL Athena and its use cases.
Solution
In today's data world, organizations leverage various structured, semi-structured, and unstructured data for multiple purposes.
- Structured data: It uses a pre-defined schema and formats, like storing or organizing data in different rows and columns in a relational database. Examples: database table, Excel spreadsheet.
- Unstructured data: Unstructured data does not have a pre-defined structure. Examples: images, audio, video, and web pages.
- Semi-structured data: Semi-structured data does not follow a strict table structure like structured data. It uses attributes or tags to define the data structure. Examples: JSON, XML, CSV.
If you are using the traditional system for data analysis, you need to fulfill the following requirements:
- Dedicated infrastructure (hardware/software) such as servers, storage, network, and software.
- Pre-defined schema for importing data from defined sources. It cannot add or remove the columns during runtime (data import).
- Design and configure an Extract-Transform-Load (ETL) process for data transformations and import. The data should be imported first before analyzing it further. For an extensive data set, it might be a time and resource-consumption process. The data transformation process could be complicated for semi or unstructured data.
- Scaling infrastructure might be a challenging task with data growth requirements. It requires manual intervention and upfront costs.
- If you get various ad-hoc requests for data analysis, it might be tedious to do all setups and then eliminate them.
Amazon Athena – Serverless Architecture
Amazon Athena solves these problems by providing a serverless architecture-based service:
- No Dedicated Infrastructure: You do not need a dedicated infrastructure before using the Athena service. It is a serverless architecture, so you do not need to provision hardware or software. You can start using the service as soon as you want.
- No ETL: Athena does not require you to deploy any ETL process. You can directly query data stored in the S3 bucket. It supports various data formats such as CSV, JSON, Apache Parquet, or ORC.
- Define Table Scheme on the Fly: Athena is especially suitable for semi- and unstructured data since you can define the table scheme during runtime, providing greater flexibility.
- Scaling Up Capabilities: It supports automatic scaling up resources; therefore, you get consistent performance with increasing the data volumes.
- SQL Compatible: Standard SQL queries can be used to analyze unstructured, semi-structured, and structured data. It supports aggregation, joins, subqueries, and predicates as well. It increases flexibility for users to use the existing SQL knowledge for data analysis.
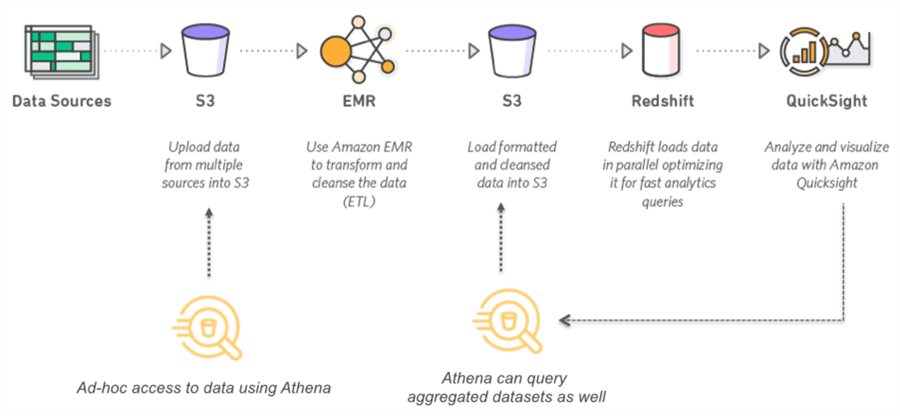
- Athena + AWS Services: You can integrate Athena with AWS services like QuickSight, CloudFormations, IAM, and VPC. The following figure illustrates the integration of services such as S3, WMR, RedShift, and QuickSight for data analysis. Athena can use both ad-hoc and aggregated data sets. You can query large datasets with joins and window functions using ANSI SQL.
- Flexible Billing: Amazon Athena provides per-query and capacity-based billing depending upon workload requirements. You can use both costing models at the same time in the same account.
- Highly Available and Durable: Amazon Athena uses S3 bucket to store the data set and directly query from the stored data. The S3 provides the durability of 99.999999999% of objects. Therefore, your data is highly available. Also, AWS automatically routes queries if a particular facility is not reachable.
Pricing
It is essential to understand the pricing of Amazon Athena before executing the queries. It is a serverless service, so you do not pay for deploying any resources. It has two different pricing models: Pay-As-You-Go and Capacity-based.
Pay-As-You-Go Model
Here are some higher-level points about this pricing model:
- In this model, Athena bills for the amount of data scanned by individual queries. It rounds up the total data scanned to the nearest pricing unit of 1 TB.
- It is the default pricing model for Amazon Athena.
- AWS does not ask for upfront costs or fixed data scanning commitments.
- It is suitable for ad-hoc query analysis.
- You can minimize the cost by optimizing the queries or using techniques such as data partitioning.
- It is also known as per query billing.
You can utilize the AWS pricing calculator to get an estimate on the per-query billing. Let's say we have the following requirements:
- Total number of queries per day: 1000
- Amount of data scanned per query: 10 GB

As per the calculations (data derived from AWS Cost Calculator), the estimate for using Amazon Athena on per query billing model is as below:
- Total number of queries: 1000 per day * (730 hours in a month / 24 hours in a day) = 30416.67 queries per month
- Amount of data scanned per query: 10 GB x 0.0009765625 TB in a GB = 0.009765625 TB
Pricing Calculations
- Rounding (30416.67) = 30417 rounded total number of queries
- 30,417 queries per month x 0.009765625 TB x 5.00 USD = 1,485.21 USD
- SQL queries with per query cost (monthly): 1,485.21 USD
- RoundUp (24) = 24 DPUs (increments of 4)
- Total SQL queries cost (monthly): 1,485.21 USD
Capacity-Based Model
Some higher-level points about this pricing model include:
- This model uses dedicated computing resources for your workload. You purchase
the Data Processing Units (DPU).
- 1 DPU = 4 vCPU and 16 GB memory.
- Minimum DPUs you can purchase: 24
- You can increase or decrease CPUs in units of 4 DPUs.
- There is no charge for the amount of data scanned. You pay for the provisioned capacity and the duration it is active in your account. The minimum duration is 8 hours.
- This model is suitable where you have a predicated workload.
Let's look at cost calculation for capacity-based pricing as per AWS Cost Calculator:
- Number of DPUs: 24
- Length of time (hours) capacity is active: 10 hours
Unit Conversions
- Amount of data scanned per query: 0.1 GB x 0.0009765625 TB in a GB = 0.00009765625 TB
- Length of time (hours) capacity is active: 10 hours per day * (730 hours in a month / 24 hours in a day) = 304.17 hours per month
Pricing Calculations
- RoundUp (24) = 24 DPUs (increments of 4)
- Max (304.17 hours per month, 8 ) = 304.17 hours per month
- 24 DPUs x 304.17 hours per month x 0.30 USD per DPU hour = 2,190.02 USD
- SQL queries with capacity-based cost (monthly): 2,190.02 USD
- Total SQL queries cost (monthly): 2,190.02 USD
Cost Optimization Techniques in AWS Athena
The cost factor is important when we work with any cloud service. We should work towards getting the high throughput with the least possible resources. There are a few optimization techniques that you can use to reduce your cost footprint while working with AWS Athena.
- Data Compression: You can compress your data to process less data in Athena queries. A few popular compression techniques are Apache Parquet or ORC.
- Partitioning: Partitioning can help reduce the Athena cost by processing only the required data. You can partition data based on year, month, day, region, etc. The SQL query can scan only the data needed from the suitable partition, resulting in less data scanning. Therefore, data access is faster and more cost-effective.
- Query Selected Columns and Rows: It is one of the best
practices not to select all the columns while querying the data table. Sometimes,
we retrieve the data using the SELECT * from Table. It returns all data (rows
and columns) from the specified table. You can do the following:
- Choose only the required columns needed in the output, such as Select col1, col3, col8 from Table;
- Specify the Where clause to return only the specific rows from the table. Suppose your data table has millions of data rows. It is not advisable to scan all rows and get the output. It will require more resources and increased cost to process the data. Therefore, you can filter the required data using the where predicate as we use in regular SQL queries.
Next Steps
- Read AWS Athena documentation on the AWS blog
- Read existing AWS tips on MSSQLTips.






About the author
 Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.
Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-09-19
