By: Ron L'Esteve | Updated: 2023-10-05 | Comments | Related: > Azure Databricks
Problem
Coding efficiently in Python, SQL, or other programming languages can be challenging, time-consuming, and quite frustrating, especially when you run into errors that could take significant amounts of time to diagnose and fix. For decades, developers who have written code in several programming languages have often wondered if there could be a better way to infuse natural language-based queries in English to create the desired results. Furthermore, if such a technological capability were readily available, then data exploration, transformation, and analysis would be democratized for citizen developers due to low learning curves and barriers to getting easier answers to their data. Let's explore how easy it is to get started with this capability with Databricks and OpenAI.
Solution
The future is now, and we can quickly start working with our data by using natural language-based queries with the English SDK. In this article, you'll learn how to ask complex questions in English and get the desired results within seconds. This demonstration will use Databricks as the data platform, coupled with Apache Spark compute, to work with the data. I will also use the open-source English SDK for Apache Spark, which takes English instructions and compiles them into PySpark objects like DataFrames. We will also use OpenAI's API to access their GPT-based Gen AI Large Language Model (LLM)
Pre-requisites
Databricks Workspace Running Within the Cloud
Let's get started with our first pre-requisite: get your Databricks Workspace running within your cloud environment. I will use Azure, but you could easily use AWS if desired. Check out this article to create your Databricks account and workspace: Get started: Account and workspace setup - Azure Databricks | Microsoft Learn. You can use a Standard account for this demo. Once your Databricks instance is up and running, you'll need a compute cluster with a runtime and node type configured. Choose a newer runtime version and a low node type, such as a Standard DS3 v2 with 14 GB Memory and 4 cores.
OpenAI API Key
You will also need an OpenAI API key. You can create a trial version by navigating to https://platform.openai.com/ and following the steps shown in the figure below to create a new secret key. Note: With the trial account, you may get trial credits, but if you have had your account associated with your phone number previously, then you will not receive the free credits. Nevertheless, $5 in funding will go a long way and certainly be more than enough to get started with a few demos.

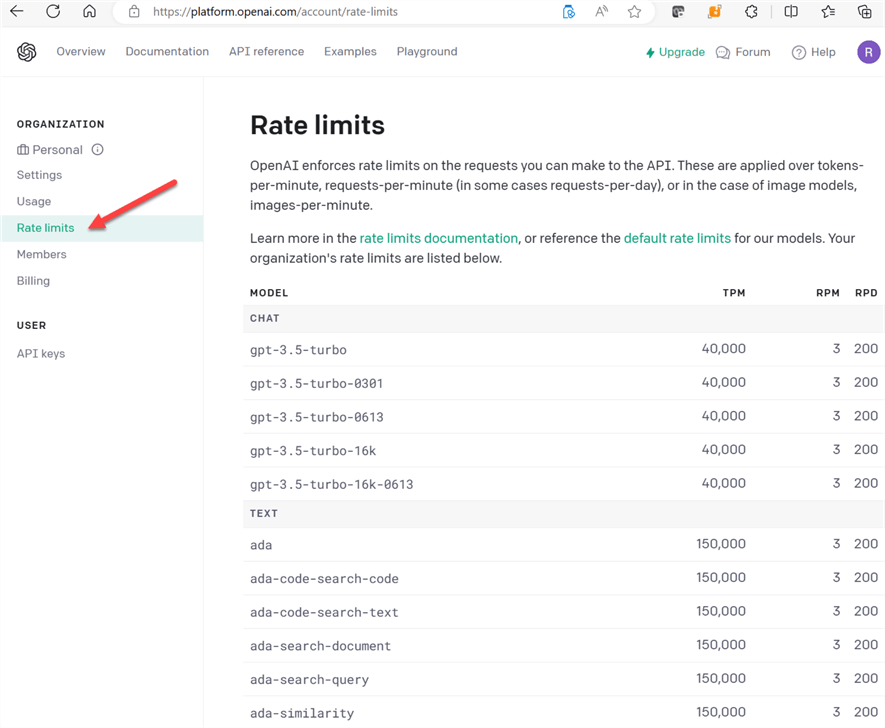
Rate Limits
While you are still within OpenAI's platform, verify the rate limits and model availability, as you will need to select a model on this list for the English SDK to work.
Databricks Workspace Compute Cluster Configuration
Next, head over to your Databricks workspace, open the Advanced options within the compute cluster's configuration settings, and enter the OPENAI_API_KEY environment variable with the OpenAI API key you created in Step 2. You can also add this key within the notebook, but I've found it more efficient to bind this to your compute than to the notebook level. Restart the cluster for this environment variable to take effect. From here forward, you can work with the English SDK in your Databricks notebook.

Install English SDK
Install the English SDK by running the following command in a notebook cell, as shown in the figure below.
pip install pyspark-ai
Import SparkAI and Langchain
Run the following code to import SparkAI and Langchain as a final pre-requisite for the setup. LangChain is a framework for developing applications powered by language models, designed to connect a language model to other sources of data and allow it to interact with its environment. Notice that you'll also need to specify your OpenAI model. I have used gpt-3.5-turbo since gpt-4 was not on the available OpenAI models list for use with the API.
from pyspark_ai import SparkAI from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name="gpt-3.5-turbo") spark_ai = SparkAI(llm=llm) spark_ai.activate()
Query & Transform Data Using English with AI
In my previous tip, I described how to enable Databricks Assistance and begin working with it. Please review that tip to understand the capabilities of the Databricks Assistant better. To query your data in English, you'll first need a good data frame to work with. You could use available data in your delta lakehouse, your hive metastore, or through the Databricks sample datasets. I have two tables in my hive metastore with customer and order data. I'll use the Assistant to write a Python query to generate a new single joined dataset with customer and order data, which I can use for querying in English.

Here is the Python code that the Assistant generated for me. Notice that this is efficient Python code, which I could also generate using English. I can now take this code and run it in a notebook cell.
from pyspark.sql.functions import col
# get the DataFrames
orders_df = spark.table("samples.tpch.orders")
customer_df = spark.table("samples.tpch.customer")
# change the column names in the join condition
customer_orders_df = orders_df.join(customer_df,
col("o_custkey") == col("c_custkey"),
"inner").select("*")
# display the DataFrame
customer_orders_df.show()
When I run this code, a new dataframe called customer_orders_df is created and displayed for me, as shown in the figure below. I can now begin asking questions of this dataframe in English.

I want to know the top 5 unique customers based on their total order price. I'll wrap that question in the following code to get an answer. Notice that the ai.transform function registers a Thought about what it intends to do first, along with an Action about how it will achieve the task. For this example, it has created and run a SQL query to generate an answer to my question.
customer_orders_df.ai.transform("List the top 5 unique customers based on their total order price?").show()

Explain Query Plans in English with AI
Let's explore the ai.explain function next. If you've been working with SQL-based storage systems for long enough, you've probably come across the EXPLAIN PLAN statement, which returns the execution plan for a specified SQL statement, allowing you to preview which operations require data movement and view the estimated costs of the query operations. By running the following code against our dataframe, there is now an easily comprehensive and detailed explanation describing the EXPLAIN PLAN statement in English.
customer_orders_df.ai.explain()

Plot Data Using English with AI
Next, let's explore the ai.plot function. I want a pie chart displaying the customer market segment as a percentage of total order price. Notice from the figure below that Python code has been generated and run to visualize the results using Plotly without me needing to type a single line of code.

Here is the code generated for me based on my question in English.
INFO: Here is the Python code to visualize the result of `df` using plotly:
```
import plotly.express as px
import pandas as pd from pyspark.sql
import SparkSession
# Create SparkSession
spark = SparkSession.builder.getOrCreate()
# Convert Spark DataFrame to Pandas DataFrame
pandas_df = df.toPandas()
# Calculate the total order price for each market segment
segment_total_price = pandas_df.groupby('c_mktsegment')['o_totalprice'].sum()
# Calculate the percentage of each market segment
segment_percentage = segment_total_price / segment_total_price.sum() * 100
# Create a new DataFrame for the pie chart
pie_chart_df = pd.DataFrame({'Market Segment': segment_percentage.index, 'Percentage': segment_percentage.values})
# Create the pie chart using plotly fig = px.pie(pie_chart_df, values='Percentage', names='Market Segment', title='Customer Market Segment as a Percentage of Total Order Price')
# Display the plot fig.show()
``` Please note that this code assumes you have already imported the necessary packages and started your Spark session.
One final capability I wanted to show is spark_ai.create_df. This function will take a website with an HTML table and convert it to a dataframe by wrapping your website in the following code and running it, as shown in the code below. My initial observation is that there are probably better screen scraping tools available on the market for this task and that it needs more work. Notice that it creates a temp view and occasionally runs out of memory since it runs a row-by-row UNION ALL. The concept of this AI screen scraping capability is great; perhaps it will be more mature someday. Google Python Client is also available, which requires additional setup and can leverage Google queries in natural language to extract data from the internet and into dataframes.
Create Dataframes from Websites with AI
movies_df = spark_ai.create_df("https://www.imdb.com/chart/boxoffice/")
display(movies_df)

Summary
Querying, transforming, and plotting data with English is very much a possibility with AI. This brings the opportunity to democratize data further and empower citizen developers to gain more insights into their data with no-code, natural language-based solutions. To take it a step further, the interfaces and UIs to interact with data via chat-based AI applications can be developed to enhance the experience. Also, a FinOps-based cost analysis should be undertaken to determine the overall price tag to implement these platforms and pay-per-use API keys at scale with your organizations. Furthermore, this capability is just one of many new proprietary Gen AI and NLP architectures (e.g., Vector Databases) taking center stage in the data and AI industry, empowering organizations to build proprietary platforms and applications that infuse AI to gain insights into their data. Organizations should also always compare various models and architectures, consider security implications, and understand the risks of AI, such as hallucinations and bias, and how to fine-tune their custom LLMs to get the best value for their organizations.
Next Steps
- GitHub - databrickslabs/pyspark-ai: English SDK for Apache Spark
- Introducing English as the New Programming Language for Apache Spark | Databricks Blog
- How to Get an OpenAI API Key (howtogeek.com)






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-10-05
