By: Rajendra Gupta | Updated: 2023-10-16 | Comments | Related: > Amazon AWS
Problem
AWS Athena is an interactive and serverless service to analyze data stored in the AWS S3 bucket using standard SQL. It is a fast, secure, and flexible service that supports various data formats, including CSV, JSON, ORC, and Parquet. In previous tips, we explored how to configure AWS Athena, query using the AWS portal and create SQL-linked servers to query Athena tables.
Solution
In this article, we will look at how Amazon Athena can partition data based on data stored in AWS S3. With the use of partitioning, you can logically divide larger tables into smaller chunks which can improve performance by working on smaller sets of data instead of the entire table.
For example, if you have Sales data stored in the S3 and you define the Partition by date this will let you logically break up the data and focus on a set of data instead of all the data. Without the Partition, Athena needs to scan all the data which results in a huge amount of data scanned. As you may know, data scans are linked to Athena's cost. Using the Partition, Athena can scan the data in the relevant Partition, reducing the amount of data scanned. It increases the query response time as well as a reduction in cost.
AWS Athena Partition Data Organization
Once we define Partition in S3 bucket data, Athena organizes the folder structures based on the partition keys.
For example, if we use the date field to create the Partition on the sales data, the S3 bucket will have multiple folders in the following structure.

Similarly, if you choose to partition based on the year and month of sales, your S3 bucket might look like:
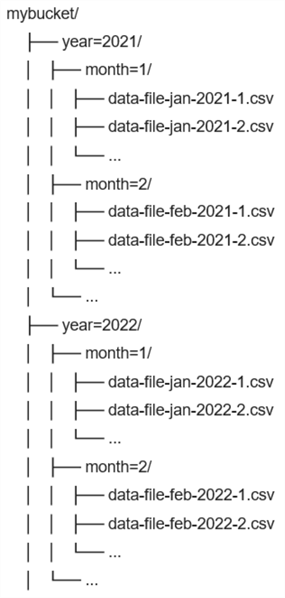
Create Partitioned Tables in Amazon Athena
Using the CREATE EXTERNAL TABLE statement, we can create a partitioned table by specifying the partitioning key columns and their data type. This external table is associated with the AWS S3 drive having the source data.
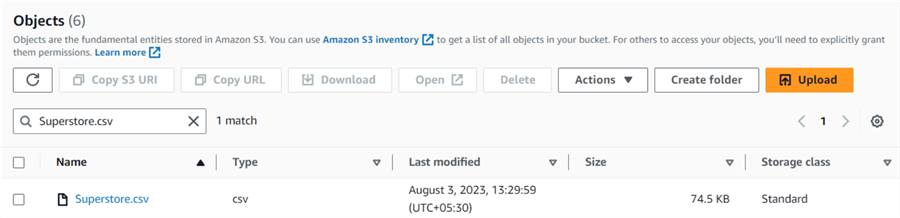
For this example, I uploaded sample data for the superstore in the S3 bucket, as shown below.
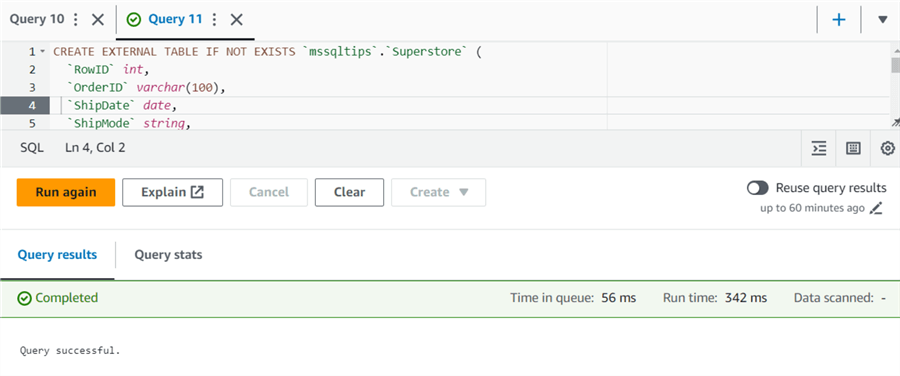
Launch Amazon Athena Service and create a new external table using the following query. You can also follow the earlier tip to create an external table using GUI.
The script below creates a table Superstore in the mssqltips database. You need to define the table columns as per your data in the S3 bucket CSV. The table script references the S3 bucket as s3://mymssqlbucket. Currently, this table does not have any partitioning.
CREATE EXTERNAL TABLE 'superstore'( 'orderdate' date, 'class' varchar(100), 'customername' varchar(100), 'segment' varchar(50), 'country' varchar(100), 'city' varchar(100), 'state' varchar(100), 'postalcode' string, 'sales' float, 'quantity' int, 'profit' float) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://mymssqlbucket/' TBLPROPERTIES ( 'classification'='csv');
We will create another table with a partition referencing the same S3 bucket CSV. To create the partitioning table, use the clause PARTITIONED BY and specify the column name as the partition key.
CREATE EXTERNAL TABLE IF NOT EXISTS 'sampledb'.'superstore_p' (
'Class' varchar(100),
'CustomerName' varchar(100),
'Segment' varchar(50),
'Country' varchar(100),
'City' varchar(100),
'State' varchar(100),
'PostalCode' string,
'Sales' float,
'Quantity' int,
'Profit' float
)
PARTITIONED BY ('OrderDate' date)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://mymssqlbucket/'
TBLPROPERTIES ('classification' = 'csv');
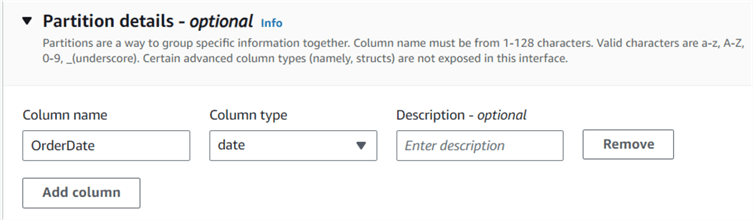
Using the Amazon Portal Athena GUI, you can specify the partition key column in the following section: Partition details - optional.
Use the INSERT INTO statement to load data from the original superstore table (without Partition) to the partition table superstore_p.
Insert into "superstore_p" ( "orderdate", "class", "customername", "segment", "country", "city", "state", "postalcode", "sales", "quantity", "profit") select "orderdate", "class", "customername", "segment", "country", "city", "state", "postalcode", "sales", "quantity", "profit" from "superstore"
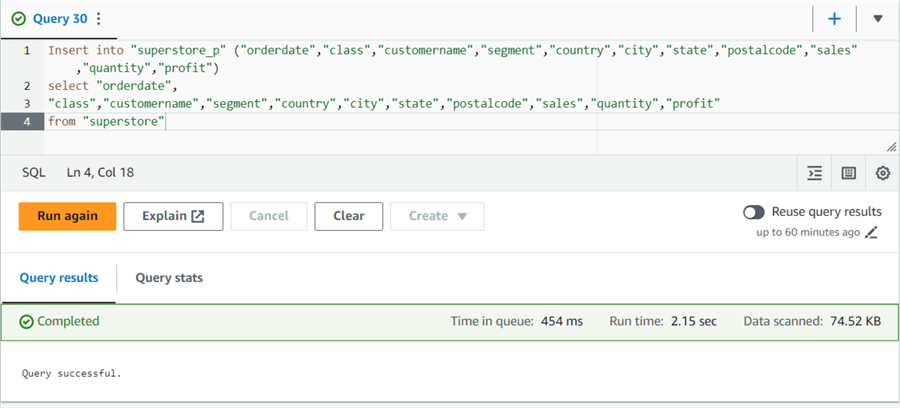
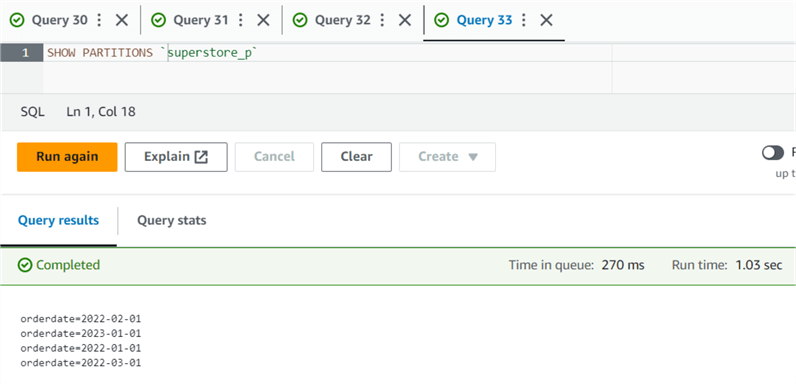
Once the data load is successful, use the query below to see the list of partitions in the partitioned table.
SHOW PARTITION tablename
As shown below, we have four partitions for the superstore_p table.
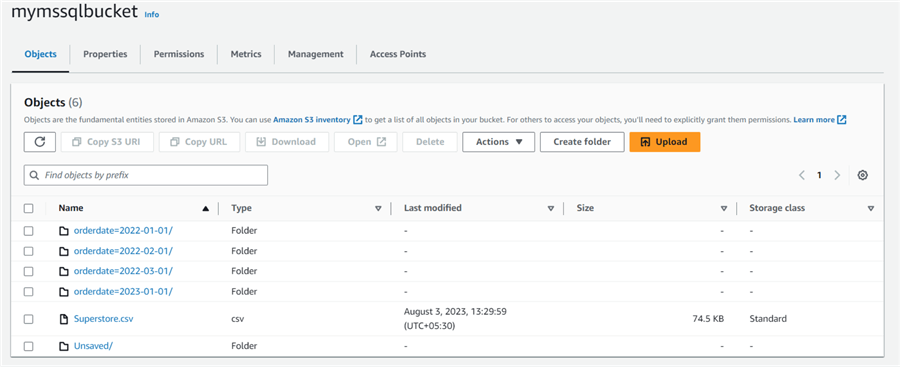
Navigate to the S3 bucket that you specified while creating the partitioned table. You will see separate folders for each partition. Since we have four partitions for the superstore_p table, it shows four folders in the S3 bucket, as seen below.
Note: You can create a maximum of 100 partitions using the INSERT INTO statements. You can use multiple INSERT INTO statements or follow the Using CTAS and INSERT INTO to work around the 100 partition limit.
Performance and Cost Comparison of Partitioned and Non-Partitioned Tables in AWS Athena
We have created two tables in Athena: one with Partition and the other without Partition. Let's run a SELECT statement to get the data from both tables.
select * from "superstore" where "orderdate"=date'2022-01-01'
Table without Partition:
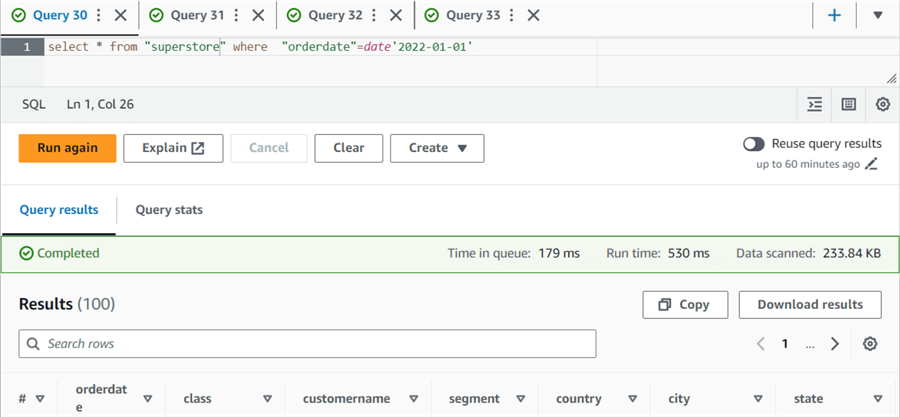
Table with Partition:
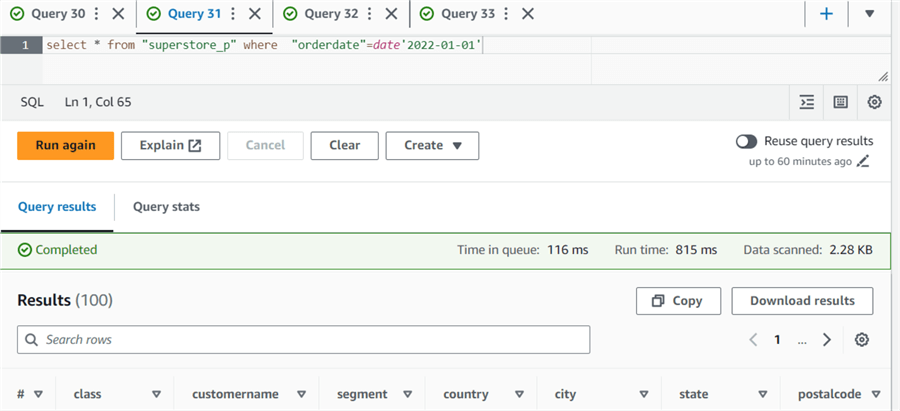
As shown in the below comparison, Amazon Athena scanned only 2.28 KB of the data for the partitioned table, while it had to scan 234 KB for the same data without the partition. You can imagine what this could be like for a large data set. The partitioned table has less data scanning, costing you less.
| Table without Partition | Table with Partition | |
| Number of rows returned | 100 | 100 |
| Data scanned | 233.84 KB | 2.28 KB |
Benefits of Partitioning Data in Amazon Athena
- Cost Optimization: You can significantly reduce the amount of data scanned with Athena partitioning. As Athena charges depend on scanned data, you can have substantial cost savings with large datasets.
- Dynamic Partitioning: Amazon Athena does not store data in the tables. It accesses the S3 drive file to return the relevant data. Once you insert new or modified data into the partition table, it automatically moves data into the appropriate partition based on the pre-defined partition key. It ensures that once data is loaded, you can query it directly for analysis.
- Single or Multiple-Column Partitions: This tip uses a single-column partition key. However, you can also use multiple columns to create the partitions. It will ensure you scan the least data to satisfy your analytical queries.
Next Steps
- Read AWS Athena documentation on the AWS blog
- Read existing AWS tips on MSSQLTips.






About the author
 Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.
Rajendra Gupta is a Consultant DBA with 14+ years of extensive experience in database administration including large critical OLAP, OLTP, Reporting and SharePoint databases.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-10-16
