By: Rick Dobson | Updated: 2023-10-30 | Comments (1) | Related: > Python
Problem
I want to programmatically find, navigate around, and enumerate content from web pages. My goal is to eventually migrate selected content from these pages to SQL Server databases. However, at this point, I am still trying to figure out how to programmatically access content on web pages. Please present some code samples that target database professionals with limited prior exposure to HTML.
Solution
BeautifulSoup is one of several screen scraping packages for web pages. The BeautifulSoup library can be imported into Python to programmatically find, navigate, and enumerate HTML elements on web pages. This kind of functionality enables the automated retrieval of content from the internet because web content often resides in HTML elements. Gathering data from web pages can serve many purposes, including retrieving retail prices from different websites, getting weather information for a database, or collecting data about financial securities.
This tip builds on an earlier one that introduces the basics of web scraping with Python 3.10 and BeautifulSoup 4. The prior tip covers how to download and install Python and BeautifulSoup. It also shows how to read and search a web page manually. Additionally, it shows how to explore HTML elements on a web page. However, the prior tip does not present any code to programmatically find, navigate, and enumerate HTML elements on a web page. This current tip presents several code samples that aim to help SQL Server professionals get started writing Python code to examine programmatically the HTML content on a web page. To further build on the prior tip, this tip processes the same source URL as in the prior tip, which is on my author page at MSSQLTips.com (https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/).
Enumerating div Elements with a Class Attribute
The initial script for this tip shows how to print a subset of HTML div elements on a web page. The following script has two main parts. The two parts are separated by a row of Python comment markers (#).
- The top part appears in all the sample scripts in this tip because all scripts
in this tip begin by pulling HTML from the same web page. This part starts
by importing the requests library and the BeautifulSoup 4 library.
- The requests library allows you to make a request from a web page
- In this tip, the myURL string variable points to my author page at MSSQLTips.com. By switching the myURL string variable assignment, you can programmatically gather content about the articles of other authors at MSSQLTips.com
- The get method can send a request to a web server for the HTML content on a web page, such as the one assigned to myURL
- The BeautifulSoup function extracts the content returned by the get method and parses it with the BeautifulSoup html.parser. The result is saved in a BeautifulSoup object named soup
- The requests library allows you to make a request from a web page
- The bottom part performs functions that are specific to the first script
- The second part begins by invoking the find_all() method on the soup
object. The find_all() method has two parameter assignments in the
example below
- The first parameter for the find_all() method designates a type of HTML element (div) for which to find instances. The div element is an HTML container for other HTML elements
- The second parameter assigns a value to the class attribute. The class attribute serves as an identifier for HTML elements
- Both find_all() parameter assignments function similarly to where clause criteria in a T-SQL select statement. For example, the find_all() method in the following script only returns HTML div elements that have a class attribute value of tabcontent
- Additionally, the code sample uses _= to discard the return value from the find_all() method because the expression is only meant to assign the result to the div_elements object, which contains the div elements in soup matching the criteria for the soup_all() function call
- After the find_all() method populates the div_elements object, a for
loop iterates through each div element in the div_elements object
- The for loop prints each div element in div_elements preceded by three header lines and followed by three trailer lines
- The lines before and after each div element mark the beginning and end of successive div elements returned by the find_all() method
- The second part begins by invoking the find_all() method on the soup
object. The find_all() method has two parameter assignments in the
example below
#Prepared by Rick Dobson for MSSQLTips.com
#reference libraries
import requests
from bs4 import BeautifulSoup
#assign a url to myURL
myURL = "https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/"
#get url content
r = requests.get(myURL)
#parse HTML code
soup = BeautifulSoup(r.content, 'html.parser')
##################################################################
# Find all the div elements with the class name "tabcontent".
div_elements = soup.find_all()("div", class_="tabcontent")
# Print the div elements to the console
# with start and end markers for each div element
for div_element in div_elements:
print ()
print (' start of div element with tabcontent class')
print ()
print(div_element)
print ()
print (' end of div element with tabcontent class')
print ()
Here is an excerpt from the IDLE Shell window. Recall from the predecessor tip that IDLE is an integrated development environment for Python scripts, much like SQL Server Management Studio is an integrated development environment for T-SQL scripts. The script returns seven div elements. The excerpt below shows the second and third div elements.
- Both elements have the same class attribute value of tabcontent. In fact, all seven returned div elements have the same class attribute because of the second parameter value for the find_all() method in the preceding script
- Each div element in the excerpt below has a different id attribute value
- The id attribute for the second of seven div elements is Bio
- The id attribute for the third of seven div elements is Awards
- As these outcomes suggest, a class attribute can pertain to two or more HTML element instances in a web page, but an id attribute can pertain to just a single HTML element instance in a web page
- Notice that the structure of the two div elements is distinct
- The Bio div element contains a paragraph element (<p>…</p>) with an embedded anchor element (<a>…</a>)
- The Awards div element has a strong element and an img element for each
award earned by an author
- The strong element (<strong>…</strong>) denotes the year for one or more awards followed by the text Awards
- The img element represents an image object for the award with the source path and file for the image as well as the height and width for displaying the image. The img element source file contains an emblem and short descriptive text for the type of award. The alt attribute indicates some alternative text to display when an image file cannot be presented
- Also,
- For the years 2020, 2019, and 2018, there are two award images per year
- For the other years, there is one award image per year

Here is a browser view of the Awards div element. It shows the emblem for each type of award as well as the year when each type of award is granted.

Displaying the Content for a Single div Element
The prior section showed how to list the structure and content of multiple HTML elements with the find_all() method so long as they satisfy two criteria – namely, the HTML element is of a specific type (div), and the class attribute has a specific value (tabcontent).
This section presents a script to display the structure and content of a single div element. Instead of using the find_all() method with two criteria settings, the following script uses the find() method and a single criterion setting based on an id attribute value. The find() method returns just the first instance of an element on a web page if the web page has more than one element matching the criterion. In this example, only one HTML element can match the criterion because the criterion is based on a single id attribute value.
The first part of the script below is identical to the script in the preceding section. This part of the script merely populates the soup object with all the HTML elements in the web page pointed at by the myURL string object. Because the myURL string value is the same in this section and the preceding one, the scripts for both sections process the same pool of HTML elements.
The second part of the script in this section has just two lines of code.
- The first line populates the div_tag object with the results of applying the find() method to the soup object. By assigning a value of Tips to the id parameter, the code returns the structure and contents of the Tips div to the div_tag object
- The second line merely displays all the HTML elements within the Tips div via a Python print function in the IDLE shell window.
#Prepared by Rick Dobson for MSSQLTips.com #reference libraries import requests from bs4 import BeautifulSoup #assign a url to myURL myURL = "https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/" #get url content r = requests.get(myURL) #parse HTML code soup = BeautifulSoup(r.content, 'html.parser') ################################################################################# #display the Tips div tag and all the elements within it #there can only be one id value per web page (url) div_tag = soup.find(id="Tips") print(div_tag)
The preceding script returns more than 1000 lines of HTML code. Here are several lines from the beginning of the IDLE window output.
- The first line denotes the beginning of a div element (<div) with an id attribute value of Tips
- The second line specifies the beginning of a table element (<table) in the div element
- The next four lines denote
- The beginning and ending tags for the table’s head section (<thead>…</thead>)
- Within the beginning and ending table head cell elements are names for the first and second columns in the table (Category and Tip Title); each column name is embedded within a th element (<th>…</th>)
- The following screenshot ends with HTML for the first three rows in the
table
- Each row begins with a start row tag (<tr>) and finishes with an end row tag (</tr>)
- Each column value within a row begins with a start cell tag (<td>) and finishes with an end cell tag (</td>)
- The first column’s value contains a hyperlink reference (href)
for the category to which a tip title belongs. The hyperlink reference
is embedded with an anchor tag (<a>…</a>)
- The href points to a URL with additional articles for the category
- The text after the URL for a hyperlink is the category name
- The second column’s value is a hyperlink reference for the tip’s
title
- The href points at a URL for the tip
- The text after the URL is for the tip’s title
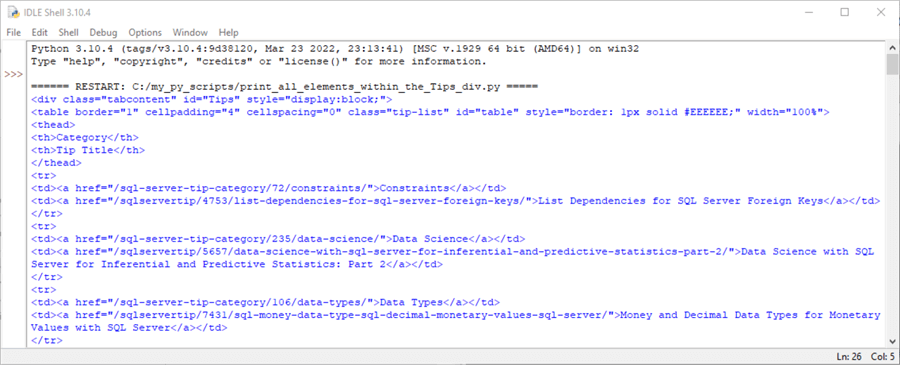
Here is a screenshot excerpt of the web page representation of the preceding HTML content.
- The table header row has a gray background color (#EEEEEE)
- Below the table header row are three more rows with hyperlinks for tip titles and their corresponding categories

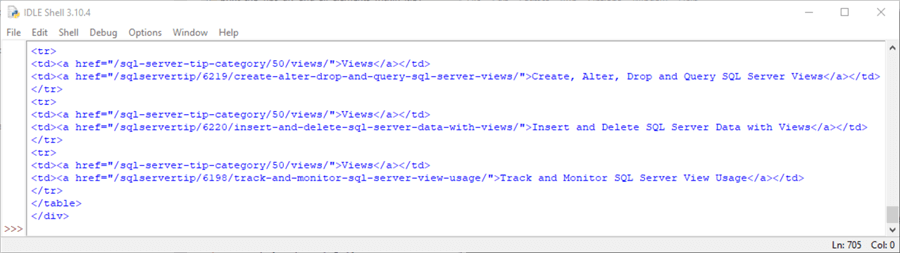
The following screenshot displays the closing HTML lines for the Tips div.
- There are four HTML elements for each tip that an author publishes in MSSQLTips.com
- The <tr> and </tr> tags mark the beginning and ending of a tip listing
- The first pair of <td> and </td> tags within a row mark the beginning and end of the category href attribute value and text
- The second pair of <td> and </td> tags within a row mark the beginning and end of the tip title href and text for the title
- Within the following screenshot excerpt, the first twelve lines are for the category and title for the last three tips listed on the author’s page at the MSSQLTips.com site
- The </table> tag closes the table element within the Tips div element
- The </div> tag marks the end of the Tips div element
Displaying Selected Anchor Elements from a div Element
This section shows four approaches to displaying anchor elements from within a div element – namely, the Tips div in the https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/ web page. The script for this page has five sections. The first section extracts all HTML elements from the source web page. The second through the fifth sections successively illustrate the four approaches for extracting and displaying anchor elements.
Here is a summary of the four approaches to extracting and displaying anchor elements from a div tag.
- Approach 1: Extract the whole div element and assign it to a Python object. Next, find all the anchor elements from the object, namely the div element, and save them in another Python object; this step is to exclude all non-anchor elements extracted from the div element. Finally, iterate through the anchor elements in the second Python object. On each iteration, invoke a print function to display the current anchor element in the IDLE Shell window.
- Approach 2: In the second approach, you can, again, start by saving all HTML elements in a div element to a Python object. Next, find an initial subset of anchor elements from the first Python object and save the subset in a second Python object. Complete the approach by printing the subset of anchor elements to the IDLE Shell window.
- Approach 3: In the third approach, you can, again, start by saving all HTML elements in the Tips div element to a Python object. Next, find a subset of just anchor elements from the tail end of the anchor elements in the first Python object. Save the subset in a second Python object. Finally, iterate through the subset of anchor tags in the second Python object. On each iteration, invoke a print function to display the anchor element in the IDLE Shell window.
- Approach 4: The fourth approach illustrates how to refer to items from the beginning and the end of a list of HTML elements with index values in Python. This approach can be especially convenient when you have a relatively short number of elements to reference. The index values for items from the beginning of a list start with 0 and increase by one for each additional item in the list. The index values for items from the end of a list start with -1; each subsequent list item from the end of the list has an index value that grows by -1.
Here is the script for implementing the four approaches. There are five sections to the script. The code implements each of the preceding bullets and is heavily commented, so the section descriptions below are brief.
- The first section extracts all the HTML elements on a page to a soup object.
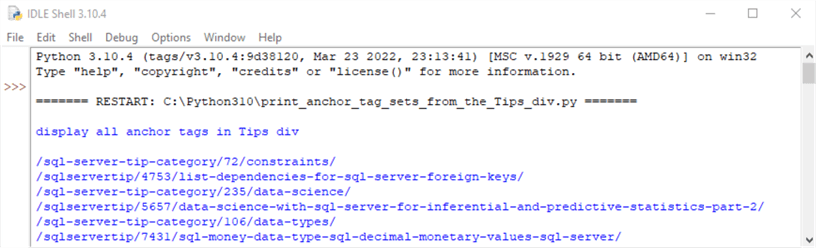
- The second section shows how to extract all the anchor tags from the Tips div in the soup object. The results are then displayed in the IDLE window.
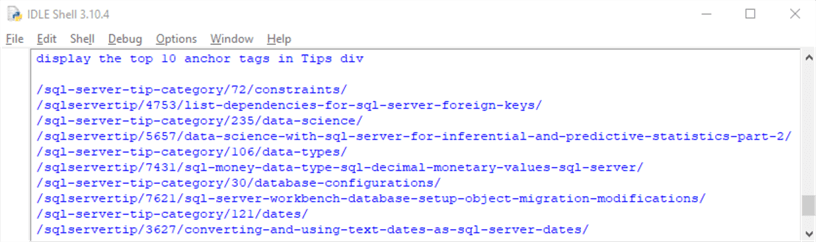
- The third section shows how to extract only the top 10 anchor tags from the Tips div in the soup object. The results are then displayed in the IDLE window.
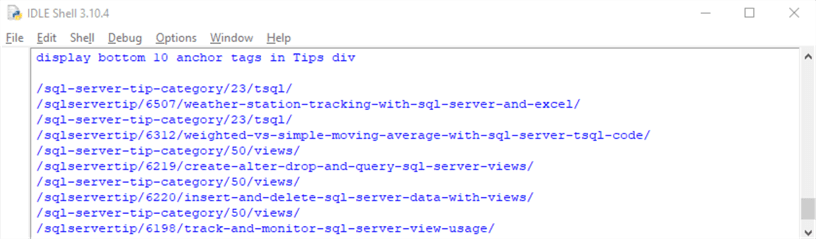
- The fourth section shows how to extract only the bottom 10 anchor tags from the Tips div in the soup object. The index value for the bottom-most element (-1) is implicit. The results are then displayed in the IDLE window.
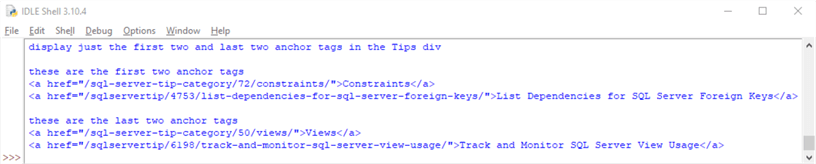
- The fifth section shows how to display only the first two anchor tags and the last two anchor tags from the Tips div in the soup object. The results are then displayed in the IDLE window.
#Prepared by Rick Dobson for MSSQLTips.com
#reference libraries
import requests
from bs4 import BeautifulSoup
#assign a url to myURL
myURL = "https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/"
#get url content
r = requests.get(myURL)
#parse HTML code
soup = BeautifulSoup(r.content, 'html.parser')
#################################################################################
print()
print ('display all anchor tags in Tips div')
print()
#find the div tag with an id attribute of Tips
div_tag = soup.find("div", id="Tips")
#find all the anchor tags in the Tips div
Tips_div_anchor_tags = div_tag.find_all("a")
#print all extracted anchor tags to the IDLE Shell window
for anchor_tag in Tips_div_anchor_tags:
print(anchor_tag["href"])
#################################################################################
print()
print ('display the top 10 anchor tags in Tips div')
print()
#find the div tag with an id attribute of Tips
div_tag = soup.find("div", id="Tips")
#get top 10 anchor tags in the Tips div
top_10_anchor_tags = div_tag.find_all("a", limit = 10)
#print all extracted anchor tags to the IDLE Shell window
for anchor_tag in top_10_anchor_tags:
print(anchor_tag["href"])
################################################################################
print()
print ('display bottom 10 anchor tags in Tips div')
print()
#find the div tag with an id attribute of Tips
div_tag = soup.find("div", id="Tips")
#find all the anchor tags in the Tips div
Tips_div_anchor_tags = div_tag.find_all("a")
#get the last 10 anchors
bottom_10_anchor_tags = Tips_div_anchor_tags[-10:]
#print all extracted anchor tags to the IDLE Shell window
for anchor_tag in bottom_10_anchor_tags:
print(anchor_tag["href"])
################################################################################
print()
print ('display just the first two and last two anchor tags in the Tips div')
print()
#find the div tag with an id attribute of Tips
div_tag = soup.find("div", id="Tips")
#find all the anchor tags in the Tips div
Tips_div_anchor_tags = div_tag.find_all("a")
# display the first two anchor tags
print ('these are the first two anchor tags')
print (Tips_div_anchor_tags[0])
print (Tips_div_anchor_tags[1])
print ()
# display the last two anchor tag
print ('these are the last two anchor tags')
print (Tips_div_anchor_tags[-2])
print (Tips_div_anchor_tags[-1])
Here is an excerpt from the IDLE Shell for the second section. It shows the initial six anchor tags in the Tips div.
Here is a second excerpt from the IDLE Shell window for the second section. It shows the bottom six anchor tags in the Tips div.

Here is the output from the third section. It shows the top ten anchor tags from the Tips div.
Here is the output from the fourth section. It shows the bottom ten anchor tags from the Tips div.
Here is the output from the fifth section. It shows the top two anchor tags followed by the bottom two anchor tags from the Tips div.
Next Steps
The next steps for this tip can take you in any of at least four different directions:
- Search for different content on the sample page within this tip. Examining the predecessor tip to this one may be a good place to find additional HTML content that you may care to explore.
- Migrate the content extracted in this tip with Python to SQL Server for populating a table and/or some frequency counts for words, such as T-SQL, Foreign, Keys, Decimal, Money, Select, View, Dependencies, From, Where, Insert, and Delete.
- Search other source web pages at MSSQLTips.com besides the sample one for this tip. This may allow you to compare the number of tips as well as the range of categories addressed by different authors. The list of anchor elements may help you locate articles by one or more of your favorite MSSQLTips.com authors.
- Choose a web page from another website besides the sample page for this tip from the MSSQLTips.com site. Then, use the techniques covered in this tip to learn about the HTML elements and content from your alternate URL.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-10-30
