By: John Miner | Updated: 2023-11-02 | Comments | Related: > Azure Databricks
Problem
The Delta Lakehouse design uses a medallion (bronze, silver, and gold) architecture for data quality. How can we abstract the read and write actions in Spark to create a dynamic notebook to process data files?
Solution
The data movement between the bronze and silver zones is a consistent pattern. Therefore, we will build generic read and write functions to handle various file types. Once these functions are tested, we can put the pieces together to create and schedule a dynamic notebook.
Business Problem
The top management at the Adventure Works company is interested in creating a Delta Lakehouse. The image below shows how the data quality improves when files are processed from left to right. In my design, I will use a stage zone. This storage container contains just today's data file, while the bronze zone will keep a copy of all data files. This may be a requirement for highly regulated industries that need a file audit trail.

We will store the metadata for a given job as a row in a delta table. Please see my previous article on why SQL-based storage is important when many parameters are passed to a program. The following tasks will be covered in four articles. Tasks 1-7 are focused on building a toolbox. This is where we will be focusing our attention today.
| Task Id | Description | Article |
|---|---|---|
| 1 | Abstract logging | 1 |
| 2 | Test logging | 1 |
| 3 | Abstract file reading | 1 |
| 4 | Additional test files | 1 |
| 5 | Test file reading | 1 |
| 6 | Abstract file writing | 1 |
| 7 | Test file writing | 1 |
| 8 | Full load notebook | 2 |
| 9 | Designing Workflows | 2 |
| 10 | Scheduling Workflows | 2 |
| 11 | Upserting data | 3 |
| 12 | Identifying primary keys | 3 |
| 13 | Soft vs. hard deletes | 3 |
| 14 | Incremental load notebook | 3 |
| 15 | Creating gold layer delta tables | 4 |
| 16 | Reading from delta tables using Power BI | 4 |
| 17 | Creating gold layer parquet files | 4 |
| 18 | Reading from the data lake using Power BI | 4 |
Looking back at our dashboard, we can see a whole system overview. Here are the components used in our Delta Lake Design:
- Azure Key Vault – save secrets.
- Azure Storage – store files.
- Azure Log Analytics – keep audit log.
- Azure Databricks – data engineering notebooks.

At the end of the article, we will have a toolbox with completely tested code. These functions will be used to create a dynamic notebook that will move data between the stage, bronze, and silver zones.
Abstracting Logging
Azure Log Analytics allows system designers to centralize auditing from a variety of programs running on various Azure services. To make a rest API call, we need to store the workspace ID, primary key and secondary key that are shown below in a key vault. This information can be found under Settings -> Agents menu selections.

The code snippet below brings in the libraries needed to make the REST API call. Please see Microsoft documentation for the details. Of course, we need to pull the workspace ID and key from the key vault for the code to work. Why not pass this information as parameters to the toolbox function? Since we are trying to create a centralized logging area, there is no need to have multiple log analytic services.
#
# Include libraries, read secrets
#
import base64, datetime, hashlib, hmac, json, requests, uuid
workspace_id = dbutils.secrets.get("ss4tips", "sec-la-workspace-id")
shared_key = dbutils.secrets.get("ss4tips", "sec-la-workspace-key")
The hardest part of making a REST API call is creating the header. This usually involves encoding the secret and passing other required information for a successful call. The child function named build_signature returns an authorization string.
#
# build_signature() - this is the authorization string for the api call
#
def build_signature(date, content_length, method, content_type, resource):
# define headers
x_headers = 'x-ms-date:' + date
string_to_hash = method + "\n" + str(content_length) + "\n" + content_type + "\n" + x_headers + "\n" + resource
# encode header
bytes_to_hash = str.encode(string_to_hash, 'utf-8')
decoded_key = base64.b64decode(shared_key)
encoded_hash = (base64.b64encode(hmac.new(decoded_key, bytes_to_hash, digestmod=hashlib.sha256).digest())).decode()
# return authorization
authorization = "SharedKey {}:{}".format(workspace_id, encoded_hash)
return authorization
The parent function, post_log_data, takes two parameters: the body and the log type. When designing a function, one must decide what to do if the call fails. I have decided to print a message that will be shown in the data engineering notebook. Either the JSON document was logged or not. Please see the Python code below for full details.
#
# post_log_data() – save the body to the log table
#
def post_log_data(body, log_type):
# Static variables
method = 'POST'
content_type = 'application/json'
resource = '/api/logs'
# Grab date/time
rfc1123date = datetime.datetime.utcnow().strftime('%a, %d %b %Y %H:%M:%S GMT')
# Size of msg
content_length = len(body)
# Grab auth signature
signature = build_signature(rfc1123date, content_length, method, content_type, resource)
# Define url + header
uri = 'https://' + workspace_id + '.ods.opinsights.azure.com' + resource + '?api-version=2016-04-01'
headers = {
'content-type': content_type,
'Authorization': signature,
'Log-Type': log_type,
'x-ms-date': rfc1123date
}
# Make https call
response = requests.post(uri, data=body, headers=headers)
# Check return value
if (response.status_code >= 200 and response.status_code <= 299):
print ('post_log_data() - accepted and stored message')
else:
print ("post_log_data() - error processing message, response code: {}".format(response.status_code))
Now that we have defined our function, it is time to test it.
Test Logging
The toolbox notebook is a work in progress. In my last article, we talked about abstracting parameters. Today, we will focus on logging, reading, and writing files. The header from the test notebook is shown below.

For this simple testing notebook, I chose to pass the parameters using a JSON document. However, in the final data engineering notebook, we will store the parameters in a metadata table using the DELTA file format. The code below parses the folder path to retrieve the schema and table name for the dimensional model files, representing each table in the SQL Server source. I will show the first call that logs the start of the notebook. Just change the action property to log the end of the notebook. Having recorded these two events, we can calculate the total time the notebook executes.
#
# Write start msg to log analytics
#
# remove slash from dir path, split into parts
path_parts = app_config['folder_path'].split("/")
# which file are we processing
nb_parm = "process [{}].[{}] file".format(path_parts[0], path_parts[1])
# Custom log in workspace
log_type = 'AdvWrksDlp'
# Create start message
json_data = [ {
"id": str(uuid.uuid4()),
"platform": "Azure Data Bricks",
"software": "Adventure Works - Data Platform",
"component": "nb-test-toolbox",
"action": "Start Program",
"parms": nb_parm,
"version": 1.01
} ]
body = json.dumps(json_data)
# Post message to log analytics
post_log_data(body, log_type)
We can use the Kusto Query language to look at the entries in the Adventure Works Data Lake Platform Custom Log (AdvWrksDlp_CL).

Unless you think there will be a potential bottleneck in the notebook code, adding a log entry for the start and end of the Spark session is good enough to calculate the total run time. Additional entries can be added to determine how long it takes to move from one quality zone to another if needed.
Abstracting File Reading
The Python Spark library can read the following file formats: AVRO, CSV, DELTA, JSON, ORC, PARQUET, and TEXT. We want to provide our generic read_data function with enough parameters to read any supported file type. The function will return a Spark dataframe as an output. The code snippet below implements our user-defined function. File type can be classified as strong or weak. Strong file types are self-contained and do not require additional data. Weak file types may require additional parameters such as a schema definition, a header line flag, and/or a delimiter character to perform the read.
#
# read_data - given a file format, read in the data
#
def read_data(file_path, file_type = 'PARQUET', file_header = None, file_schema = None, file_delimiter = None):
# convert to upper case
file_type = file_type.upper()
# valid file types
file_types = ['AVRO', 'CSV', 'DELTA', 'JSON', 'ORC', 'PARQUET', 'TEXT']
# read avro
if (file_type == 'AVRO'):
df = spark.read.format("avro").load(file_path)
return df
# read delta
if (file_type == 'DELTA'):
df = spark.read.format("delta").load(file_path)
return df
# read orc
if (file_type == 'ORC'):
df = spark.read.format("orc").load(file_path)
return df
# read parquet
if (file_type == 'PARQUET'):
df = spark.read.format("parquet").load(file_path)
return df
# read json
if (file_type == 'JSON'):
if (file_schema is None):
df = spark.read.format("json").option("inferschema", "true").load(file_path)
else:
df = spark.read.format("json").schema(file_schema).load(file_path)
return df
# do we have a header line?
if (file_header is None or file_header.upper() == 'TRUE'):
header_flag = "true"
else:
header_flag = "false"
# do we have a delimiter?
if (file_delimiter is None and file_type == 'CSV'):
sep_char = ","
elif (file_delimiter is None and file_type == 'TEXT'):
sep_char = "\r\n"
else:
sep_char = file_delimiter
# read csv
if (file_type == 'CSV'):
if (file_schema is None):
df = spark.read.format("csv").option("header", header_flag).option("inferschema", "true").option("delimiter", sep_char).load(file_path)
else:
df = spark.read.format("csv").option("header", header_flag).schema(file_schema).option("delimiter", sep_char).load(file_path)
return df
# read text
if (file_type == 'TEXT'):
df = spark.read.format("text").option("lineSep", sep_char).option("wholetext", "false").load(file_path)
#df = spark.read.format("text").load(file_path)
return df
# unsupported file type
if (file_type not in file_types):
df = spark.emptyDataFrame()
return df
Note: An invalid file type results in an empty dataframe return value. Now that we have our user-defined read function, we need to create test cases for each file type.
Additional Test Files
The Azure Databricks workspace contains a folder on the file system named databricks-dataset. This folder contains data in various formats. However, I could not file data in the AVRO and/or ORC formats. Therefore, we need to read in a known dataset and create temporary copies of the file to work with.
I found an online retail dataset saved in a CSV format. The Python code below uses our new function to read the file into a variable named df0.
# # Setup 1 - read csv data file # # the folder var_path = '/databricks-datasets/online_retail/data-001' # the type var_type = 'CSV' # read files & infer schema df0 = read_data(var_path, var_type) # show data display(df0)
The display command shows the information in a scrollable grid. We can see the online retail data in the image below.

Because I have not defined a generic write_data function yet, we will use the Databricks utility and PySpark commands to solve the problem. The code below creates a sub-directory named online_retail under the tmp root directory. I will repartition the dataframe to one file and save the information in a sub-directory named avro.
#
# Setup 2 - write avro file
#
# remove dir
tmp_dir = '/tmp/online_retail/avro'
try:
dbutils.fs.rm(tmp_dir, recurse=True)
except:
pass
# write dir
df0.repartition(1).write.format('avro').save(tmp_dir)
# show dir
display(dbutils.fs.ls(tmp_dir))
The list command was used to display the files in the avro sub-directory. The one file starting with part-00000 represents the partitioned dataframe saved in AVRO format. Please see the image below for details.

We need to repeat this process for the ORC file format.
#
# Setup 3 - write orc file
#
# remove dir
tmp_dir = '/tmp/online_retail/orc'
try:
dbutils.fs.rm(tmp_dir, recurse=True)
except:
pass
# write dir
df0.repartition(1).write.format('orc').save(tmp_dir)
# show dir
display(dbutils.fs.ls(tmp_dir))
Again, the list command was used to display the files in the orc sub-directory. The one file starting with part-00000 represents the partitioned dataframe saved in ORC format. Please see the image below for details.
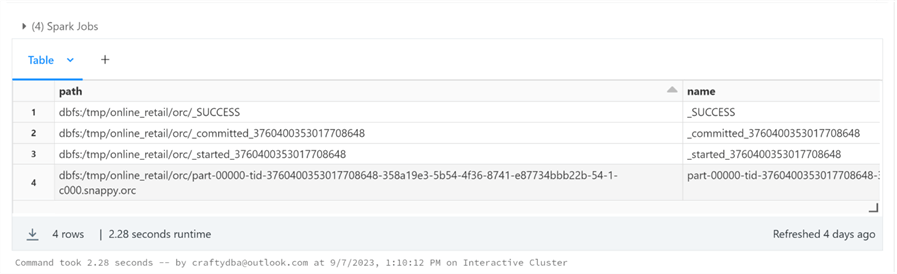
Now that we have test files for each format, we can finally test our generic read_data function.
Test File Reading
The pattern for reading files is quite similar. That is why we created a generic read function that can be parameter-driven. The code below reads an AVRO file. It requires a file path and file type since it is a strong file type!
# # Read 1 - avro file(s) # # the folder var_path = '/tmp/online_retail/avro' # the type var_type = 'AVRO' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the online retail dataframe displayed in a scrollable grid. Note: The AVRO and ORC file tests use the same dataset.

The code below reads in CSV data files on bike sharing.
# # Read 2 - csv file(s) # # the folder var_path = '/databricks-datasets/bikeSharing/data-001/' # the type var_type = 'CSV' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the bike sharing dataframe displayed in a scrollable grid.
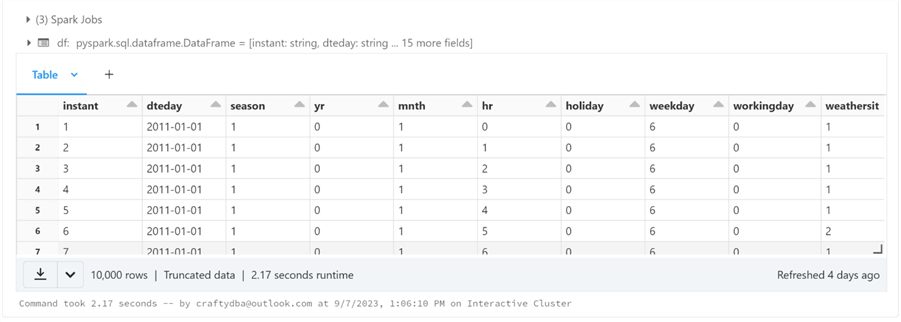
The code below reads in the DELTA file for people's salaries.
# # Read 3 - delta file(s) # # the folder var_path = '/databricks-datasets/learning-spark-v2/people/people-10m.delta' # the type var_type = 'DELTA' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the people's salary dataframe displayed in a scrollable grid.

The code below reads in JSON data files for IOT devices.
# # Read 4 - json file(s) # # the folder var_path = '/databricks-datasets/iot/' # the type var_type = 'JSON' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the Internet Of Things (IOT) dataframe displayed in a scrollable grid.
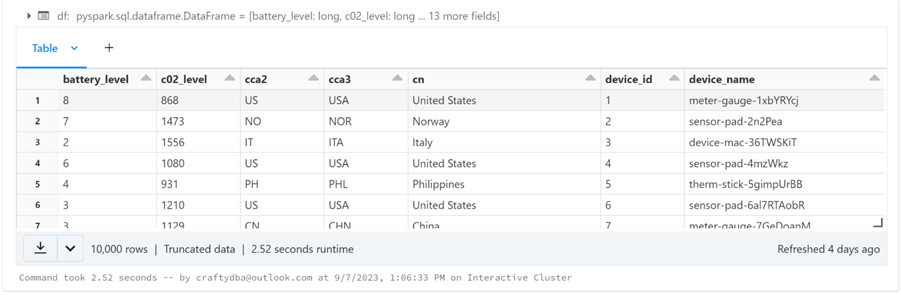
The code below reads in the ORC data file for online retail data.
# # Read 5 - orc file(s) # # the folder var_path = '/tmp/online_retail/orc' # the type var_type = 'orc' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the online retail dataframe displayed in a scrollable grid.

The code below reads in the PARQUET data file for Amazon Sales data.
# # Read 6 - parquet file(s) # # the folder var_path = '/databricks-datasets/amazon/data20K/' # the type var_type = 'PARQUET' # read files & infer schema df = read_data(var_path, var_type) # show data display(df)
The image below shows the amazon sales dataframe displayed in a scrollable grid.

The code below reads in a TEXT data file for power plant readings.
That has been a tedious exercise, but testing is almost complete. One thing I did not disclose is that we have been passing parameters by position. Also, the read_data function has default values for missing arguments. The only required function arguments are the file path and the file type. To pass a parameter that is out of order, I suggest passing the parameters by name.
# # Read 7 - text file(s) # # the folder var_path = '/databricks-datasets/power-plant/data/' # the type (CR - '\r' or LF - '\n') var_type = 'TEXT' var_del = '\n' # read files & infer schema df = read_data(file_path=var_path, file_type=var_type, file_delimiter=var_del) # show data display(df)
Passing a different delimiter to the read data function results in different looking dataframes. The Azure Databricks system runs on a cluster of Linux boxes. When we use the line feed character (LF or \n) as the delimiter, we read all five files a line at a time. There are thousands of lines or strings.
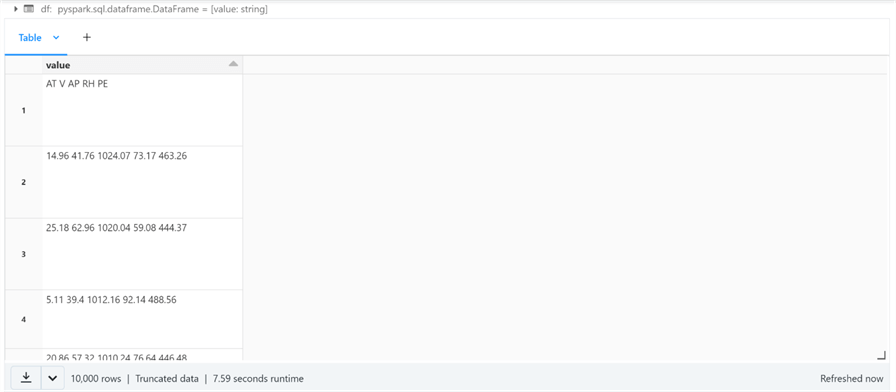
The power plant data file contains no carriage returns (CR or \r). If we choose this character as the delimiter, we can see that the dataframe has five rows. Each row is the complete file as a single string.

To recap, we have painstakingly tested all file formats supported by the read_data function.
Abstracting File Writing
The Python Spark library can write the following file formats: AVRO, CSV, DELTA, JSON, ORC, PARQUET, and TEXT. We want to provide our generic write_data function with enough parameters to write any supported file type. The return value from the function is a numeric representing failure (-1) or success (0). It is up to the developer to set the partition count or column of the input dataframe. While some file formats support appending data, the only file format that truly supports INSERT, UPDATE, and DELETE commands is the DELTA format. Today, we are going to focus on the full data load pattern. Thus, the file folder is deleted before data is written.
#
# write_data - given dataframe, write files
#
def write_data(input_df, file_path, file_type = 'PARQUET', file_header = None, file_schema = None, file_delimiter = None):
# convert to upper case
file_type = file_type.upper()
# valid file types
file_types = ['AVRO', 'CSV', 'DELTA', 'JSON', 'ORC', 'PARQUET', 'TEXT']
# unsupported file type
if (file_type not in file_types):
return -1
# remove dir if exists
try:
dbutils.fs.rm(file_path, recurse=True)
except:
pass
# write avro
if (file_type == 'AVRO'):
input_df.write.format("avro").save(file_path)
return 0
# write delta - supports ACID properties
if (file_type == 'DELTA'):
input_df.write.format("delta").save(file_path)
return 0
# write orc
if (file_type == 'ORC'):
df.write.format("orc").save(file_path)
return 0
# write parquet
if (file_type == 'PARQUET'):
input_df.write.format("parquet").save(file_path)
return 0
# write json
if (file_type == 'JSON'):
input_df.write.format("json").save(file_path)
return 0
# do we have a header line?
if (file_header is None or file_header.upper() == 'TRUE'):
header_flag = "true"
else:
header_flag = "false"
# do we have a delimiter?
if (file_delimiter is None and file_type == 'CSV'):
sep_char = ","
elif (file_delimiter is None and file_type == 'TEXT'):
sep_char = "\r\n"
else:
sep_char = file_delimiter
# write csv
if (file_type == 'CSV'):
input_df.write.format("csv").option("header", header_flag).option("delimiter", sep_char).save(file_path)
return 0
# write text
if (file_type == 'TEXT'):
input_df.write.format("text").option("lineSep", sep_char).option("wholetext", "false").save(file_path)
return 0
Now that we have our user-defined write function, we need to test each file type.
Test File Writing
The pattern for writing files is quite similar. That is why we created a generic write function that can be parameter-driven. All files will be written to a test folder in the data lake. We will use the online retail dataframe as the input for all write tests.
The code below writes an AVRO file.
# # Write 1 - avro file format # # the folder var_path = '/mnt/advwrks/datalake/test/avro' # the type var_type = 'AVRO' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the AVRO directory with the files listed in a scrollable grid.

The code below writes a CSV file.
# # Write 2 - csv file format # # the folder var_path = '/mnt/advwrks/datalake/test/csv' # the type var_type = 'CSV' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the CSV directory with the files listed in a scrollable grid.

The code below writes a DELTA file.
# # Write 3 - delta file format # # the folder var_path = '/mnt/advwrks/datalake/test/delta' # the type var_type = 'DELTA' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the DELTA directory with the files listed in a scrollable grid.

The code below writes a JSON file.
# # Write 4 - json file format # # the folder var_path = '/mnt/advwrks/datalake/test/json' # the type var_type = 'JSON' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the JSON directory with the files listed in a scrollable grid.

The code below writes an ORC file.
# # Write 5 - orc file format # # the folder var_path = '/mnt/advwrks/datalake/test/orc' # the type var_type = 'ORC' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the ORC directory with the files listed in a scrollable grid.

The code below writes a PARQUET file.
# # Write 6 - parquet file format # # the folder var_path = '/mnt/advwrks/datalake/test/parquet' # the type var_type = 'PARQUET' # write out retail data ret = write_data(input_df = df0, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the PARQUET directory with the files listed in a scrollable grid.
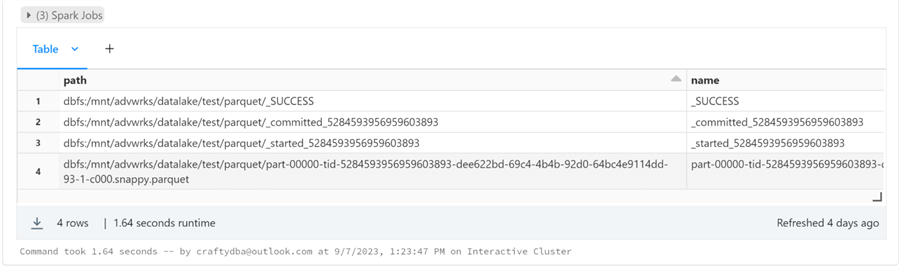
To write a text file, we need to work on formatting the dataframe into a single column of type string. The array spark function can be used to concatenate the fields into a single column called 'merged' of type string. Instead of df0 as the input dataframe, we will use df1, which has the correct format for the TEXT file type.
#
# Concatenate + Cast
#
# req lib
from pyspark.sql import *
# perform action
df1 = df0.select(array('InvoiceNo', 'StockCode', 'Description', 'Quantity', 'InvoiceDate', 'UnitPrice', 'CustomerID', 'Country').alias('merged').cast(StringType()))
# just one part
df1 = df1.repartition(1)
# show result
display(df1)
The image below shows the data as the string representation of an array.

The code below writes a TEXT file.
# # Write 7 - text file format # # the folder var_path = '/mnt/advwrks/datalake/test/text' # the type var_type = 'TEXT' # write out retail data ret = write_data(input_df = df1, file_path=var_path, file_type=var_type) # show dir display(dbutils.fs.ls(var_path))
The image below shows the TEXT directory with the files listed in a scrollable grid.

In a nutshell, we have painstakingly tested all file formats supported by the write_data function.
Summary
Today, we spent a lot of time creating generic functions for logging events, reading various file formats, and writing multiple formats. This time was well spent since this toolbox will be pivotal to the full load and incremental load parameter-driven notebooks we will craft in the future.
Why write audit logs to Azure Log Analytics? A complete data platform system might have events occurring in Azure Data Factory, Azure Databricks, and/or Azure SQL Database. Each service is completely separate and has different default data retention settings. By using Azure Log Analytics, we have a centralized logging solution. Even on-premises tools like SSIS can add audit logs using the REST API.
Reading and writing data using the Apache Spark Library is straightforward. However, abstracting the actual function calls is very powerful. A single function can be called with different parameters to read or write various file formats. These generic functions will be used to write future parameter-driven notebooks.
Not covered in this article is reading or writing from Relational Databases. Since we are focused on creating Delta Lakehouse, this functionality is unnecessary. Are the supplied functions complete? There is always room for improvement. For instance, many formats support compression. A TEXT file can be saved using the GZIP algorithm. I leave enhancements to the functions for you to complete. The current version of the functions is adequate to demonstrate both full and incremental loading using a parameter-driven notebook.
Enclosed are the files used in this article. Next time, we will focus on creating a full-load data engineering notebook and scheduling a complete set of files for our Adventure Works dimensional model.
Next Steps
- Full file loading with Delta Tables
- Incremental file loading with Delta Tables
- Read these additional Databricks articles






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-11-02
