By: Koen Verbeeck | Updated: 2023-12-08 | Comments | Related: > Microsoft Fabric
Problem
I've been reading the tips about Microsoft Fabric on MSSQLTips.com. I have wondered if most sample data was uploaded manually to Fabric, but I assume this is not ideal for a production environment. Which methods or tools can be used to automate the ingestion of data into Microsoft Fabric?
Solution
Microsoft Fabric is the new centralized end-to-end data analytics platform in the cloud. It offers several compute services, such as the lakehouse, data warehouse, and real-time analytics. Manually uploading data daily is not the goal; instead, it is having it ingested automatically. In this tip, we'll investigate some options to get data into Fabric.
We can divide the ingestion of data in Fabric into two categories:
- Code-based pipelines: Notebooks and Spark jobs.
- UI-based pipelines: Data pipelines and data flows.
Keep in mind that this tip was written while Microsoft Fabric was in public preview. This means features can change, disappear, or be added, and even the general outlook may change. Additionally, to limit the scope, real-time ingestion for the KQL databases or Eventstreams is left out.
Code-based Pipelines
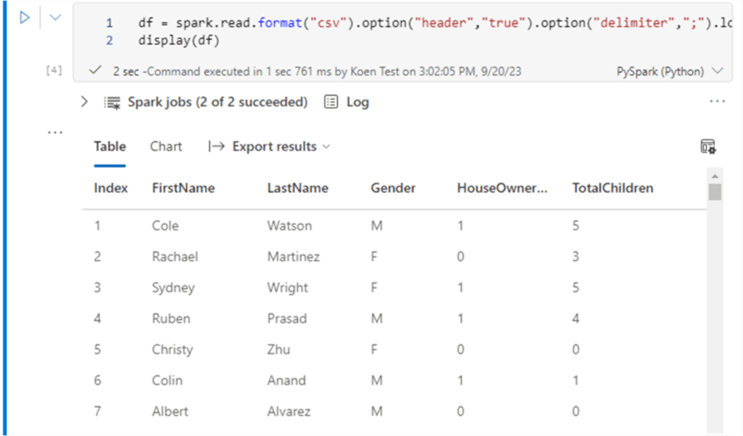
A previous tip, Create a Notebook and Access Your Data in a Microsoft Fabric Lakehouse, shows how to create a notebook that will read some data using PySpark.
You can go to its settings in a notebook by clicking on the gear icon.
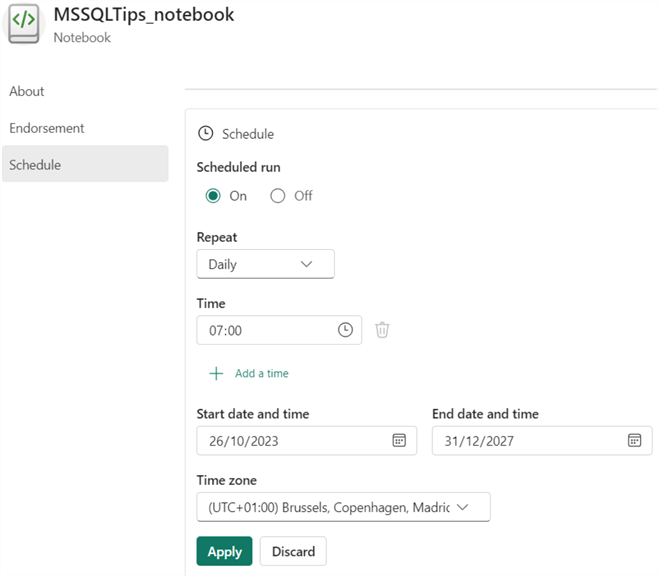
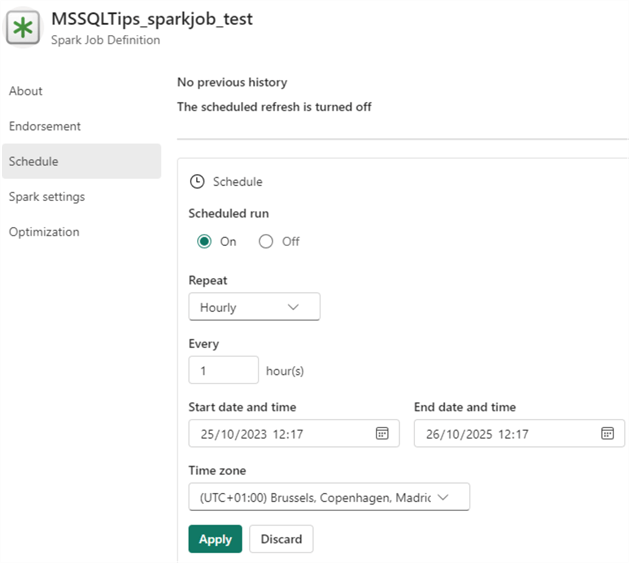
There, you will find a Schedule section to define a simple schedule that will execute your notebook.
Alternatively, you can go to the notebook's Run section and click Schedule for the same settings pane.
There's time zone support, but oddly, you must specify an end date for the schedule before clicking Apply. Another option is to add your notebook to a pipeline and then schedule that pipeline. You can find more information on pipelines in the UI-based pipelines section of this tip.
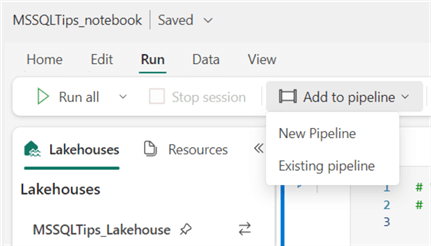
Using the Data Engineering persona, you can create a Spark Job Definition instead of directly scheduling a notebook.
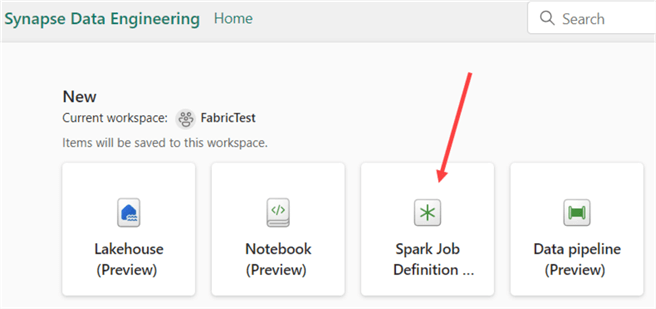
When a new Spark Job is created, you must specify a name first:
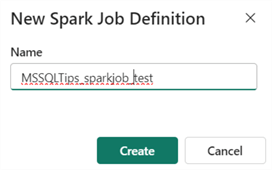
In the Spark Job, you can switch between the available languages by using the dropdown at the top:
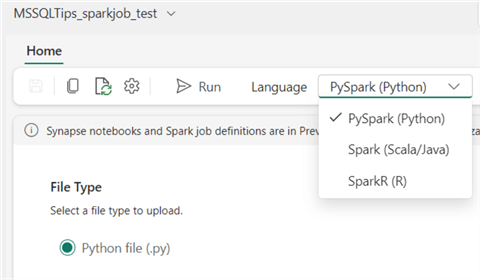
For the job configuration, you need to specify a main definition file (which contains the actual code that needs to be run) by either uploading a file or referencing one stored in Azure Data Lake Storage. You can also specify optional reference files (for example, modules used in your Python code) and/or command line arguments.
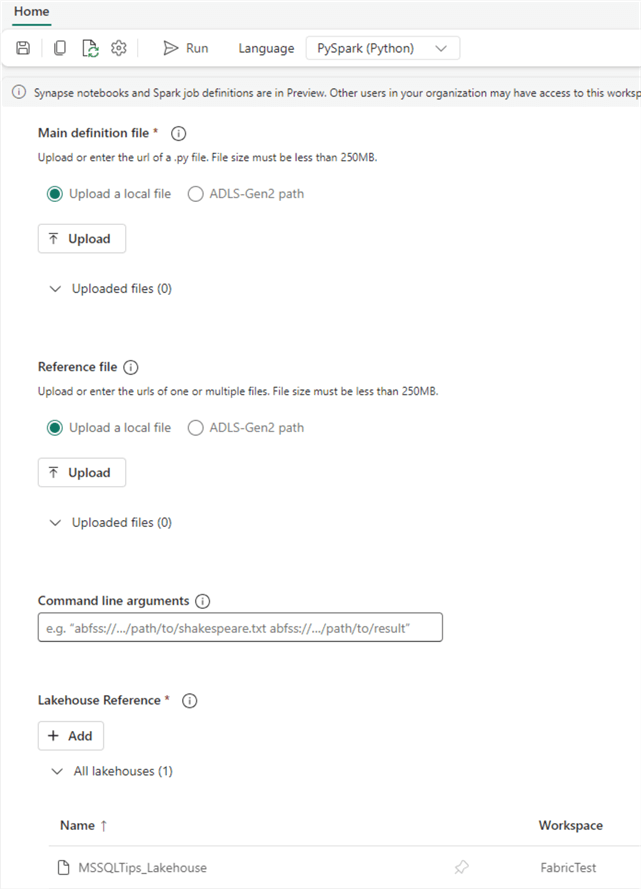
At the bottom, you need to reference one or more lakehouses, just as you would in a notebook. Once the configuration is done, you can schedule the job in Settings, like in the notebook.
UI-based Pipelines
When in the data factory persona, two possible objects can be created: data pipelines and dataflow Gen2.
A data pipeline is essentially the same as a pipeline in Azure Data Factory (ADF). However, it's not an exact copy of ADF for the moment. Some features are still missing and being added while Fabric is still in preview mode.
To create a new pipeline, you have three options: add a pipeline activity, copy data, or choose a task to start.
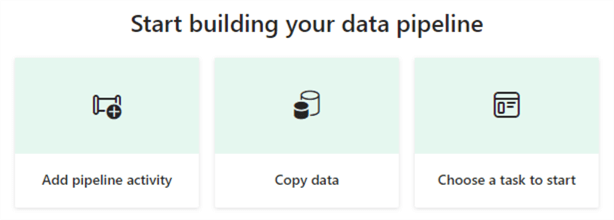
Adding a pipeline activity to a blank canvas is typically chosen if you already have experience with ADF and immediately want to start working on your pipeline.
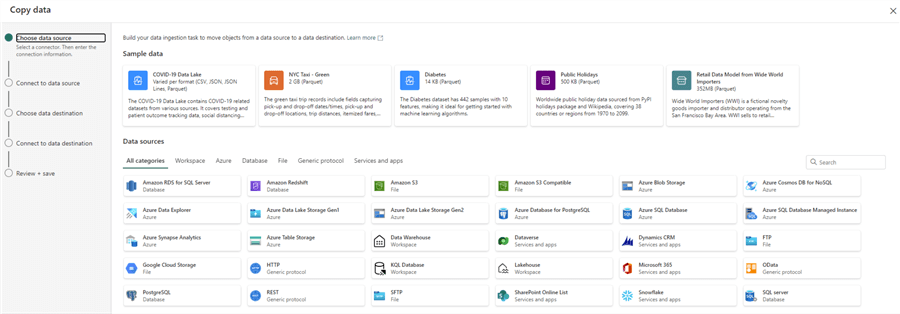
If you choose Copy data, this will create a pipeline with one Copy Data activity, configured by the wizard, similar to ADF, as seen in the image below.
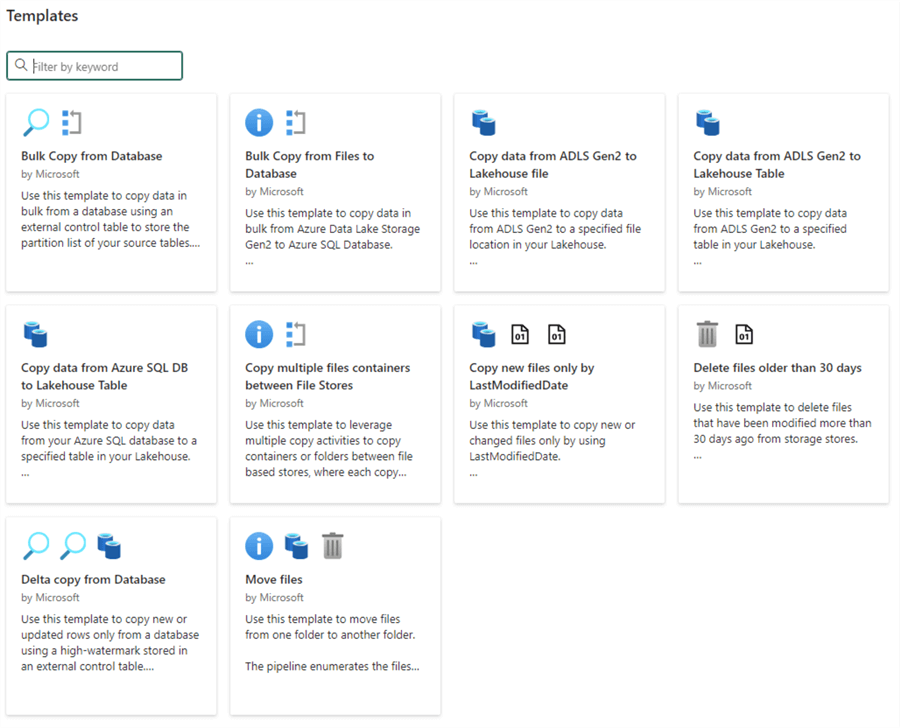
The third option, Choose a task to start, provides templates to begin the creation of your pipeline quickly, as seen below.
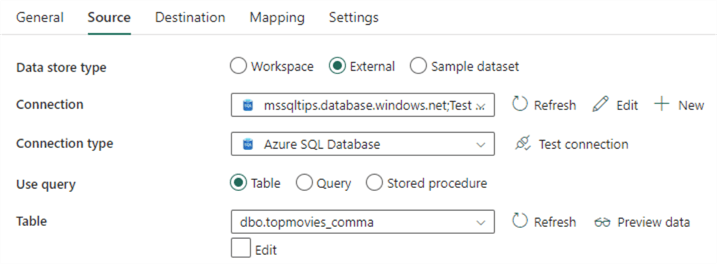
A significant difference between pipelines in Fabric and ADF is that there are no datasets and linked services in Fabric. Instead, everything is defined in-line:
If you want to edit an existing connection, click Edit next to the dropdown. This will take you to the Data screen, where you can edit the connection and view all other created connections.
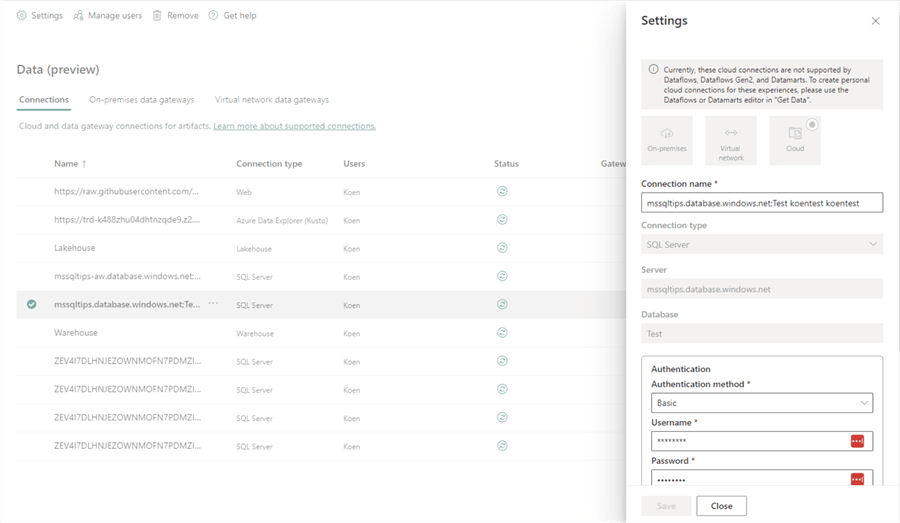
You can reach the same screen by clicking the gear icon in the top right corner and choosing Manage connections and gateways.
Another feature not present in Fabric is the mapping data flows of ADF. The Power Query data flow of ADF is similar to the Dataflow Gen2 pipeline in Fabric, as both are implementations of the Power Query engine. Dataflows Gen2 are also an improvement upon the Power BI dataflows, as you can choose a destination in the Gen2 pipeline.
A Dataflow Gen2 pipeline allows you to transform data by applying transformations. You can use the ribbon to create a new transformation or the visual editor to add a transformation.
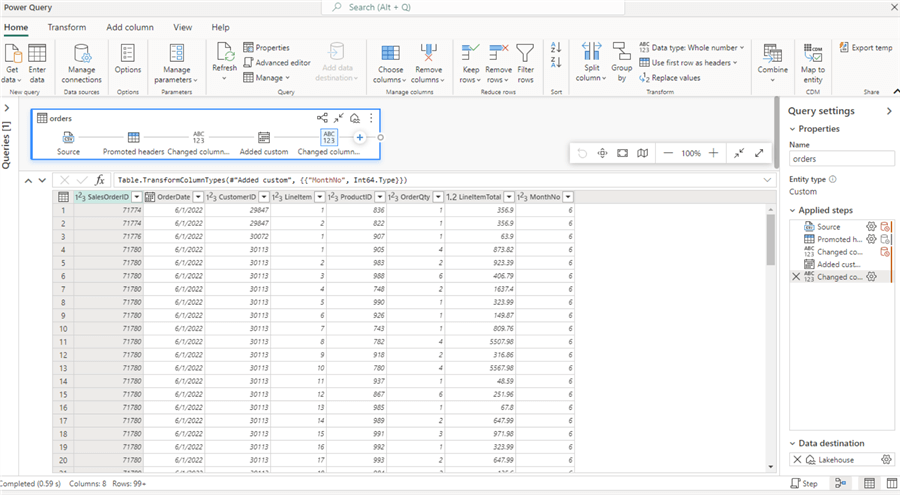
By clicking the icons in the visual editor or selecting a step in the sidebar, you can go back and forth between the different transformations and preview their effect on the data. As mentioned before, a destination can be configured. You can hover over the icon in the visual editor to see the current configuration.
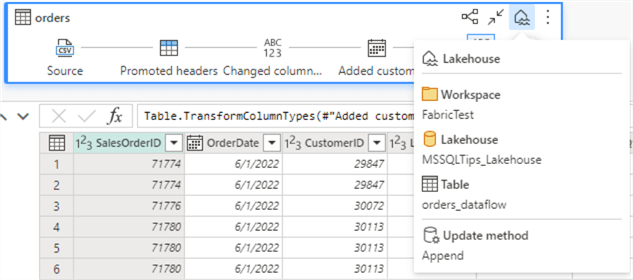
You can edit the destination by clicking on it.

The same can be done in the query settings pane:
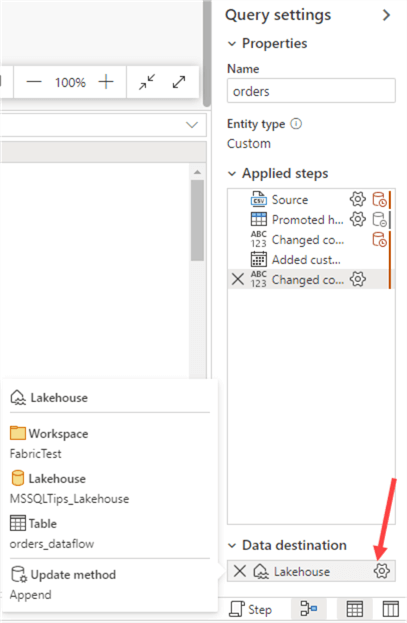
You can choose a destination in the ribbon if you don't have one. If a destination is already configured, this option will be greyed out:
In the destination settings, you can choose to either overwrite the target or to append data to the target:
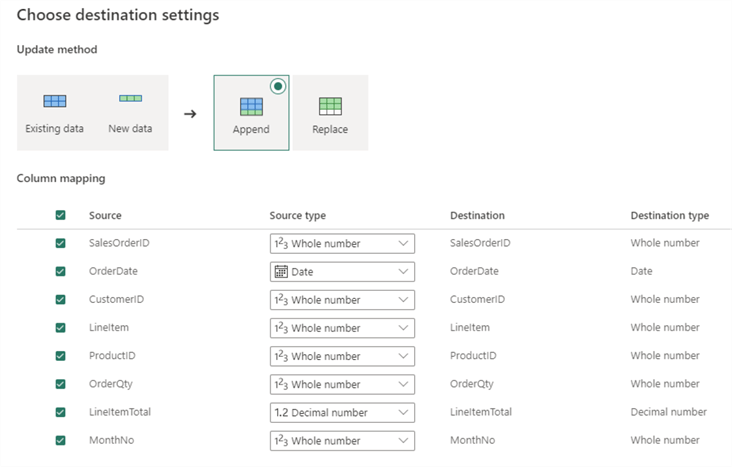
Conclusion
In Microsoft Fabric, there are several methods in two broad categories to ingest data: code-based pipelines and UI-based pipelines. The first category, Code-based pipelines, mainly uses Spark for data ingestion and transformation. You can use notebooks and Spark jobs to automate ingestion. The second category, UI-based pipelines, is either data pipelines (like Azure Data Factory) or dataflows (Power Query online in the browser, with the option to choose a destination).
These are not your only options, though. Because the storage format is open (both the lakehouse and the warehouse store data as delta tables), you are free to use any tool you like to get data into Fabric. In the warehouse, it's also possible to use SQL statements such as COPY INTO or CREATE TABLE AS SELECT to get data into tables.
Next Steps
- If you want to familiarize yourself with the concepts of Azure Data Factory (which can be translated to Microsoft Fabric pipelines), check out the free tutorial.
- The tip, What is Power Query?, introduces the Power Query editor. Power BI Desktop is used in this tip, but the concepts are roughly the same in a Microsoft Fabric Dataflow Gen2.
- You can find more Fabric tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-12-08
