By: John Miner | Updated: 2024-02-22 | Comments | Related: > PostgreSQL
Problem
Many companies want to reduce licensing costs by moving existing databases written for SQL Server (commercial software) to PostgreSQL (open source). First, consider the man-hours needed to make this migration possible. Then, weigh the cost of the migration against the potential savings in the future. If your company is undertaking this adventure, what are the technical pitfalls you might encounter when moving not only the database schema but also refactoring the code?
Solution
In this tip, I will demonstrate how to migrate an existing database schema from SQL Server to PostgreSQL. However, the old saying "garbage in equals garbage out" applies to both views and stored code. These two types of pre-compiled code will challenge the developer to use their skills to decipher code written years ago and convert it to modern-day code that is performant, uses intermediate steps for debugging, and uses logging for run time metrics.
Business Problem
There are many ways to find the prime numbers between 1 and n. The user-defined function in the math database uses the Sieve of Eratosthenes. This brute force method executes division tests on the candidate number. Because it uses both compute (programming code) and storage (table inserts), it is a good benchmark test for comparing different relational database systems at a high level.
Our manager has asked us to convert the current bench database named math from Microsoft SQL Server to PostgreSQL. We will also explore how to schedule both SQL and Batch commands using the pgAdmin extension. After reading this article, you will understand the objects inside a PostgreSQL database and how to design a system with them.
All sample code will be supplied at the end of the article. If you want to follow along with the examples, grab the code now.
Tablespace
This article assumes you read the previous article on deploying and configuring a PostgreSQL database on a Windows operating system.
What are tablespaces? They are areas where the files for the database are stored. Typically, a database administrator (DBA) places different databases on different disks. You do not have control over the individual files. For instance, since it is seldom used, we want our historical reporting database on a slower IOPS disk in an Azure Virtual Machine. On the other hand, our current reporting database is frequently used and should be on a high IOPS disk.
By default, the postgres account is the super user. This account can execute create tablespace, alter tablespace, and drop tablespace commands. The code snippet below shows the current user via a SELECT statement. We can also see the postgres user is connected to the postgres database in the query tool image below. The postgres database in PostgreSQL is analogous to the master database in SQL Server.

The code below is quite simple.
/*
Create a tablespace
*/
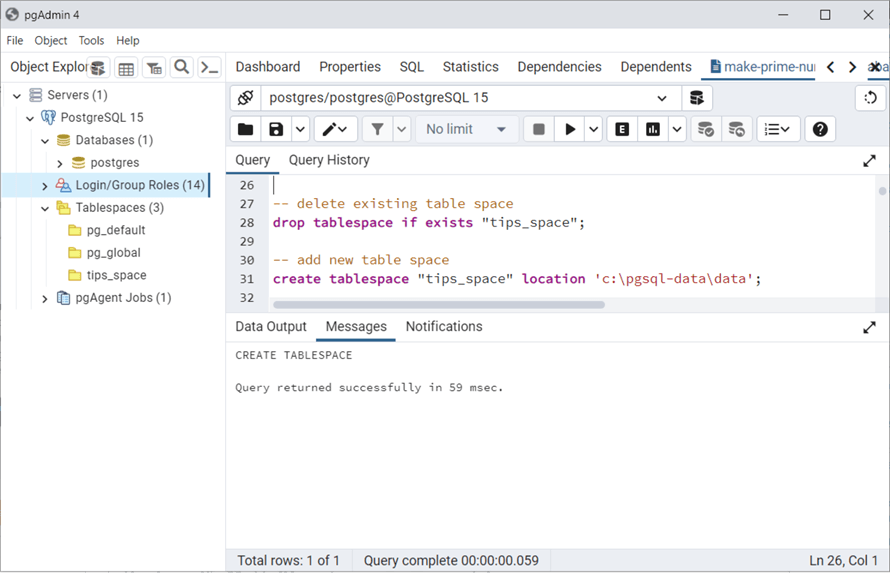
-- delete existing table space
drop tablespace if exists "tips_space";
-- add new table space
create tablespace "tips_space" location 'c:\pgsql-data\data';
Let's talk about the issues one might encounter when trying to execute the commands. Certain commands can not be executed in the same transaction. The tablespace command falls into this category. Instead, run each command separately.

The disk and directory must exist before creating a tablespace. The following error will occur if the directory does not exist:

After creating the directory using Windows Explorer, we can execute the create tablespace and receive a successful execution. The image below shows that three tablespaces exist.
If we open a command shell, we can execute the following directory listing command in the new folder. The /s flag tells the utility to search the directories recursively.
dir /s
We can see that the directory is empty at this time. The directory will fill up once we create databases using the given tablespace name.

One word of caution: Do not delete this directory! First, you must drop all the databases and then the empty tablespace. Otherwise, you might break the logical links used by the database engine, which can lead to a broken database system.
Database
The PostgreSQL database engine supports the create database, alter database, and drop database commands. The same issue exists when executing these commands in the same transaction. The with force option of the drop database command terminates all connections before dropping the database. The owner and tablespace options of the create database are optional. It will default to who is logged in during creation as well as the pg_default tablespace.

The above image shows a failure when both commands are executed as one transaction. Instead, execute each line separately. The image below shows the newly created database, math, in the database list.

While SQL Server supports the concept of a model database, PostgreSQL supports the concept of template databases. Version zero of the template database is pristine and should never be changed. Version one of the template database is used to create all other databases. Additionally, you can mark a database as "template" so that it can be cloned.

The command shell snippet below lists all files in a comprehensive format.
dir /w
Let's look at the innermost tablespace directory now.
The creation of the math database resulted in two new directories and 298 files consuming around 7.5MB of disk space.

We had errors when executing both the create tablespace and create database commands. Where are the errors from the database engine stored?
Errors
Under the installation directory of the PostgreSQL engine, there is a data directory. This is where databases that use the default tablespace are created. One sub-directory is called log. This is where the log files are stored. The image below shows the database engine capturing the previous tablespace error. Log files have both date and time appended to the name.

As a test, I deleted all the files in the log directory. To my surprise, errors were no longer being recorded. One way to fix this problem is to restart the database service. This will force the creation of a new log file. Use the services snap-in to manage both the database and agent services.

The next logical step is to create a user for our math database.
Users and Privileges
In past versions of PostgreSQL, users and groups were supported. Today, both commands are an alias to the newer role command. A user is a role that has login rights. A group is a role that contains a bunch of users.
The PostgreSQL database engine supports the create user, alter user, and drop user commands. Additionally, rights can be granted or revoked. There are several predefined roles, such as pg_read_all_data and pg_write_all_data. The code snippet below creates a user named mssqltips with these roles. In short, this user can now execute SELECT, INSERT, UPDATE, and DELETE statements on all databases.
-- delete existing user drop user if exists "mssqltips"; -- add new user create user mssqltips with password '<your password here>'; -- grant rights (cluster wide) grant pg_read_all_data, pg_write_all_data to mssqltips;
The public schema in PostgreSQL is analogous to the dbo schema in SQL Server. Let's log into the math database using the new user named mssqltips and create a new table called public.tips.

Unsurprisingly, this command failed since we did not give the user rights to the data definition language (DDL) – create table rights.
In another window, open the query window using the super user (postgres) and the user database (math). Execute the above command to create the table. Note: The query tool is associated with a connection that points to a single database. If we want to switch databases, we need to open another window. Make sure to focus on the correct database before opening the query tool.

The image above shows the postgres user creating the table. The image below shows the mssqltips user inserting and selecting data. Both the create and drop table commands will fail when executed by the mssqltips user.

Let's use revoke the default roles on the mssqltips user.
-- grant rights (cluster wide) revoke pg_read_all_data, pg_write_all_data from mssqltips;
We can see that the execution of SELECT statements is no longer allowed by the user account.

If we execute the following grant commands, the mssqltips user will have all rights to both the math database and the public schema. All the above statements will execute without errors.
-- specific database grant all privileges on database math to mssqltips; -- specific schema grant all privileges on schema public to mssqltips;
As a database administrator, granting security can be a full-time job. Try using groups to reduce the amount of work you have to do.
Schemas
One cool feature in PostgreSQL is the ability to drop a non-empty schema, which is powerful and dangerous if not used correctly. The details on create schema, alter schema, and drop schema can be found in the documentation on the PostgreSQL website.
-- -- must re-connect query tool 2 math database! -- -- drop existing schema drop schema if exists "dbo" cascade; -- create new schema create schema "dbo";
Why not use the public schema? For existing systems that have schemas defined in the application, it is best to reproduce what is already there—that way, coding changes are reduced for the front-end applications.
Tables
The math database has two tables. The first table contains the prime numbers that we find during the execution of the plpgsql code. Why am I explicating stating the extension? Because there is support for other programming languages, such as Perl and Python. The functions in PostgreSQL can be defined with these languages. However, I suggest sticking with SQL since it is generally portable between database engines.
As a SQL Server developer, you might ask where my GO statements are. That language feature is only supported by Transaction SQL. Also, you might notice that everything is terminated with a semicolon. That is how the parser determines the end of a statement. Unlike SQL Server, semicolons are required, not optional. Another interesting fact is that SQL Server uses brackets [], not double quotes " " to escape names that might be reserved. Also, PostgreSQL is case-sensitive by default for strings, and object names are converted to lowercase by the parser. Thus, I suggest escaping names or doing everything in lowercase if you want to use mixed case. We will talk more about string searching in a future article.
The code below incorporates the drop table and create table statements to rebuild a table from scratch. Note that constraints, default constraints (values), check constraints, and primary key constraints are used in the table design.
/*
Create a table to hold the prime numbers.
*/
-- delete existing table
drop table if exists "dbo"."tbl_primes";
-- add new table
create table "dbo"."tbl_primes"
(
"my_value" bigint not null,
"my_division" bigint not null constraint "chk_tbl_primes" check ("my_division" > 0),
"my_time" timestamp not null constraint "df_tbl_primes" default (current_timestamp),
constraint "pk_tbl_primes" primary key ("my_value")
);
The control card table is used to determine the search range of a given stored procedure call. The first call would search the numbers from 1 to 250,001. The create table statement in PostgreSQL has a GENERATE ALWAYS AS IDENTITY option. However, behind the scenes, the database engine uses a sequence. The code below uses both the drop sequence and create sequence statements.
/* Create a sequence for the job card table. */ -- drop existing sequence drop sequence "dbo"."seq_control_card_id"; -- add new sequence create sequence "dbo"."seq_control_card_id" increment 250000 start 1;
Now that we have a sequence, we can complete the definition of the control card table. Notice the nextval function sets the my_id field to the next number in the sequence. This only works if no value is given for the field.
/*
Create a table to hold the job control card
*/
-- delete existing table
drop table if exists "dbo"."tbl_control_card";
-- add new table
create table "dbo"."tbl_control_card"
(
"my_id" bigint default(nextval('dbo.seq_control_card_id')),
"my_comment" varchar (128),
"my_date" timestamp default (current_timestamp)
);
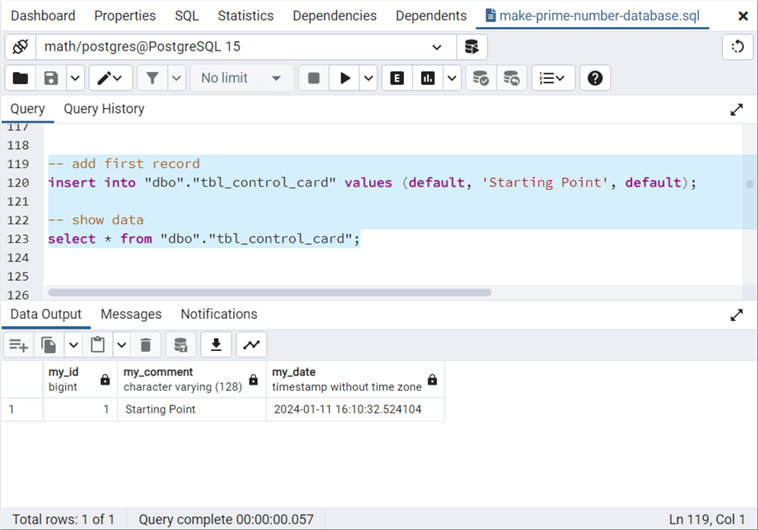
-- add first record
insert into "dbo"."tbl_control_card" values (default, 'Starting Point', default);
-- show data
select * from "dbo"."tbl_control_card";
The image below shows the control card table is all set. Let's define our is prime function.
Functions
The PostgreSQL engine supports the create function, alter function, and drop function statements.
I discovered several key differences other than syntax between the SQL Server and PostgreSQL languages. Parameters and/or local variables are the same. I used default values so that parameters are optional. But we only expect one parameter, the number we want to determine if it is prime. Since PostgreSQL supports many different coding languages, the $$ markers are used to identify the start and end of the code. The language parameter tells the parser which language the body was written in. The equality command is a single equal (=), and the assignment command is a colon equal (:=) series of characters. Finally, the square root function in SQL Server automatically rounded down when casting to an integer. I had to use the floor function to come up with similar results.
/*
Create a function to determine if number is prime!
*/
-- delete existing function
drop function if exists "dbo"."ufn_is_prime";
-- create new function
create function "dbo"."ufn_is_prime"
(
var_num2 bigint = 1,
var_cnt2 bigint = 0,
var_max2 bigint = 0
)
returns integer as $$
begin
-- not a prime number
if (var_num2 = 1) then
return 0;
end if;
-- is a prime number
if (var_num2 = 2) then
return 1;
end if;
-- set up counters
var_cnt2 := 2;
var_max2 := floor(sqrt(var_num2)) + 1;
-- trial division
while (var_cnt2 <= var_max2)
loop
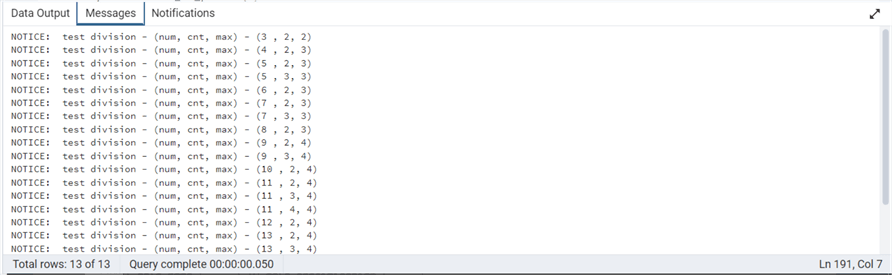
-- debugging
raise notice 'test division - (num, cnt, max) - (% , %, %)', var_num2, var_cnt2, var_max2;
-- not a prime number
if (var_num2 % var_cnt2) = 0 then
return 0;
end if;
-- increment counter
var_cnt2 := var_cnt2 + 1;
end loop;
-- is a prime number
return 1;
end;
$$ language plpgsql;
It is always important to test your code. The image below shows the union of 13 distinct calls to the ufn_is_prime function. The result set is the numbers that are prime (1) versus not prime (0).

When learning a new language, it is important to write debugging information to track down bugs. The raise notice statement allows the developer to print text to the messages window. Comment out this code when you are interested in execution time.
Now that we have a boolean function to determine if a number is prime, we need to write a stored procedure to test and store prime numbers from x to y.
Procedures
The PostgreSQL engine supports the create procedure, alter procedure, and drop procedure statements.
The algorithm for this procedure, named dbo.usp_store_primes, is quite simple. Create a counter and increment from x to y. For each candidate prime number, call the function dbo.ufn_is_prime. If the return value is 1, then save the value and square root into the dbo.tbl_primes table.
/*
Create a procedure to store primes from x to y.
*/
-- delete existing procedure
drop procedure if exists "dbo"."usp_store_primes";
-- create new procedure
create procedure "dbo"."usp_store_primes"
(
var_alpha bigint = 1,
var_omega bigint = 1,
var_cnt1 bigint = 1,
var_ret1 integer = 0
)
as $$
begin
-- set starting point
var_cnt1 := var_alpha;
-- trial division
while (var_cnt1 <= var_omega)
loop
-- test current number
select * into var_ret1 from "dbo"."ufn_is_prime"(var_cnt1);
-- debugging
raise notice 'store primes - (number, prime) - (% , %)', var_cnt1, var_ret1;
-- is a prime number
if (var_ret1 = 1) then
insert into "dbo"."tbl_primes" values (var_cnt1, floor(sqrt(var_cnt1)) + 1, default);
end if;
-- increment counter
var_cnt1 := var_cnt1 + 1;
end loop;
end
$$ language plpgsql;
The image below shows a sample call to the stored procedure. The SELECT statement shows that the code found 8 prime numbers between 1 and 21.

Views
The PostgreSQL engine supports the create view, alter view, and drop view statements. By the way, I have not mentioned yet that the "create" statement has an optional "or replace" clause for most commands. That means the alter statement is usually used to perform maintenance chores like changing ownership or name.
The view named dbo.uvw_processing_time calculates how long it takes to detect primes and how many primes were found. It assumes that the test to find all prime numbers from 1 to 5 million is done with 20 asynchronous calls to the database. What might be strange is how dates are handled in PostgreSQL. I leave this up to you to investigate.
/* Create a view for processing time. */ -- delete existing function drop view if exists "dbo"."uvw_processing_time"; -- create new function create view "dbo"."uvw_processing_time" as select min(p."my_time") as "start_time", max(p."my_time") as "end_time", extract(seconds from (max(p."my_time") - min(p."my_time"))) as "elapsed_time", count(*) as "total_recs" from "dbo"."tbl_primes" as p; -- show results select * from dbo.uvw_processing_time;
The image below shows that calculating prime numbers between 1 and 21 took no time.

I do not have time to cover the information schema in this article; however, the pgsql script does have a sample call that displays the objects in the database. Let's reset the database objects so that we can create and run our first job.
/*
Reset for testing.
*/
truncate table "dbo"."tbl_control_card";
truncate table "dbo"."tbl_primes";
alter sequence dbo.seq_control_card_id restart with 1;
insert into "dbo"."tbl_control_card" values (default, 'Starting Point', default);
Batch Jobs
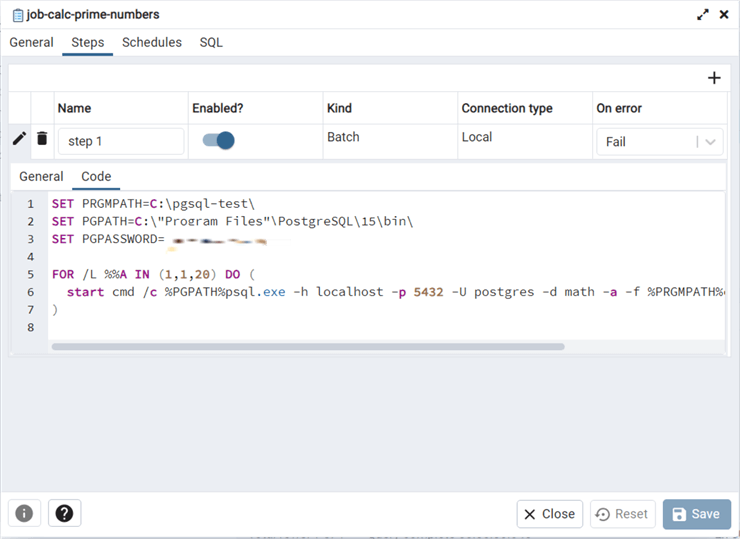
In the last article, we installed the pgAgent extension but did not create sample jobs. Today, we will finish that task. Our first job will be called "job-calc-prime-numbers." It will run MS-DOS commands to execute the calculate prime number script.

The general page shown above captures the name of the job and description. The steps page below allows the developer to define one or more steps. Make sure you use the plus sign to add one or more steps or schedules. We can see we are defining a local batch job.

The DOS commands below set three environment variables: the path to the PLPGSQL script, the path to the psql utility, and the password for the database connect. The for loop opens 20 command windows to run the test in parallel.
It is always important to create a schedule. The schedule should have a start and end date. Without an end date, I found the run once command will run the job continuously.
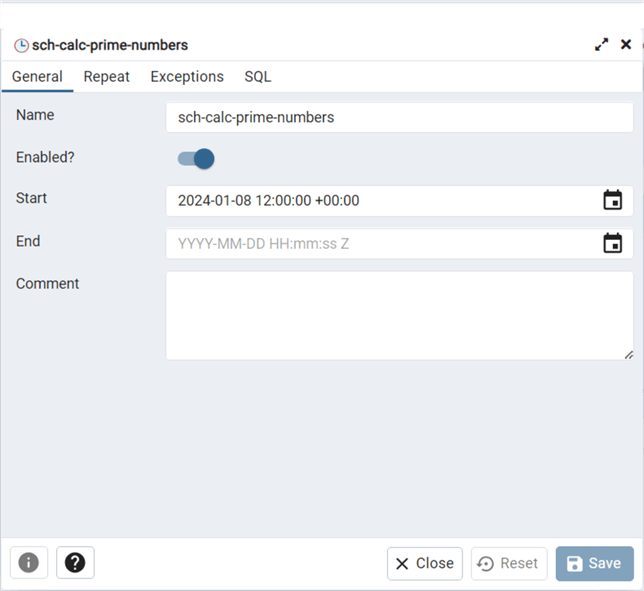
Additionally, we can schedule the job in many ways. See the dialog box below for details.

The query below shows the number of entries that should be in the control card table.

The query below shows that 348,513 prime numbers exist between 1 and 5 million.

Were you able to get the job running? This problem stumped me for a little while. The pgAgent is running under the Postgres local Windows operating system user. For some reason, it is looking for the pgpass.conf file for passwords. See the documentation on this file usage here.
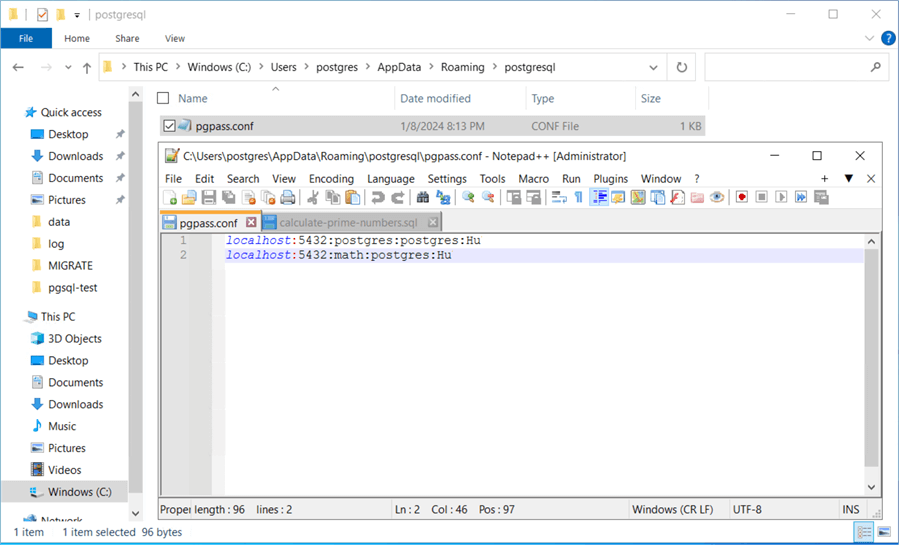
In the next section, we will create an hourly job to investigate the next 250,000 numbers and determine which ones are prime.
SQL Jobs
Let's repeat the steps for creating a batch job. The only difference is we must select a database this time. If creating a remote SQL connection, we need to enter a connection string. The password file still comes into play; don't forget to add a new entry. Just change the local host entry to the IP address.

The above image shows the general screen for a SQL step. The image below shows the code for the SQL step. Interestingly, I did not need to name the $$ delimiter when calling the script from psql in the batch file. However, we must supply a mnemonic, such as the word "code" in the editor. This could be anything you want.
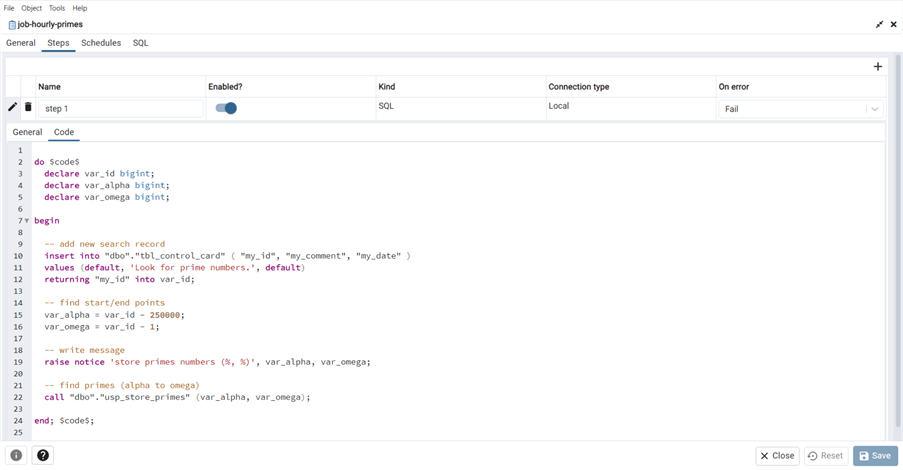
This article is not meant to cover the pgAgent extension completely. But I wanted to leave you with a debugging SQL statement. The pgagent.pga_jobsteplog table in the postgres database can be used to track down errors. Line 43 shows that the postgres database was the default for the job during iteration one, and it could not find the table name control card. Also, the next line shows the job execution was deleted. In short, the following error codes might be seen: s = success, f = failure, d = delete, and r = retry.

During extensive testing, I noticed that the pgAgent service terminated one time unexpectedly. I fixed this issue by going into the services snap-in in Windows and starting the service.
Summary
Today's article focused on converting the existing benchmark database from SQL Server to PostgreSQL. The following database topics were discussed: tablespaces, databases, roles, privileges, schemas, tables, sequences, functions, stored procedures, and views. That pretty much covers the basics of converting a simple database schema to PostgreSQL.
What I dislike about PostgreSQL is that some statements can not be executed in a single transaction. Also, you can't switch connections between different databases in the administrative tool. What I like is that a cascade drop removes all objects in a schema. The support for creating a table as (CTAS) when using temporary tables is quite nice. When dealing with large datasets, implementing materialized views can speed up results.
I will be writing more about PostgreSQL in the future. I hope you enjoyed reading the article. Enclosed is the zip file with all the code covered in this article.
Next Steps
- Follow along with these future related articles:
- Deploy and configure Azure SQL Database for PostgreSQL
- How to use temporary tables in PostgreSQL
- Using materialized views with large datasets in PostgreSQL
- Different ways to create and call functions in PostgreSQL.
- Main differences between functions and procedures in PostgreSQL.
- How to perform PostgreSQL database CI/CD with Liquid Base






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-02-22
