By: Koen Verbeeck | Updated: 2024-03-27 | Comments | Related: 1 | 2 | 3 | 4 | 5 | > Microsoft Fabric
Problem
We're going to create a data warehouse in Microsoft Fabric using the warehouse feature. Do we need to do any special maintenance since all tables are actually delta tables? I believe I read somewhere that every time you do an insert, update, or delete, a new Parquet file is created. Doesn't this grow out of control? How do we handle this situation?
Solution
Microsoft Fabric is the new unified, all-encompassing data platform in the cloud. There are several types of workloads possible – check out the Microsoft Fabric Personas tip to learn more. One of them is the warehouse. With a Fabric warehouse, you can build a data warehouse using T-SQL like in SQL Server, Azure SQL Database, or Synapse Analytics. The only difference is that behind the scenes, all data is stored as delta tables (see also the tip: What is OneLake in Microsoft Fabric? to learn more about the storage structure in Fabric).
Delta tables are an open format and are comprised of a transaction log (in JSON files) and Parquet files that hold the actual data. When we take a look at the actual data of a warehouse table in the storage layer, we can see the following two folders:
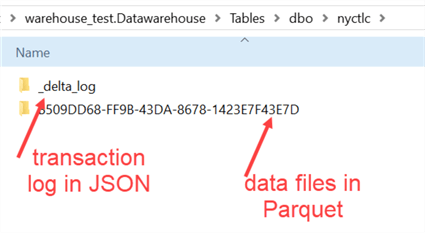
Like "regular" tables in SQL Server, delta tables also need maintenance. Since one of the biggest value propositions of Fabric is that everything is software-as-a-service (SaaS), automating the maintenance tasks is one of the methods to make everything easier for the developer/user.
In this tip, we'll cover what this means exactly for you. If you want to follow along, you can download and use a free Fabric trial. Keep in mind that Microsoft Fabric is a fast-moving product with regular updates, which means some of the functionality may have been expanded, changed, or improved by the time you read this.
Table Maintenance in the Fabric Warehouse
Setting Up the Warehouse with Sample Data
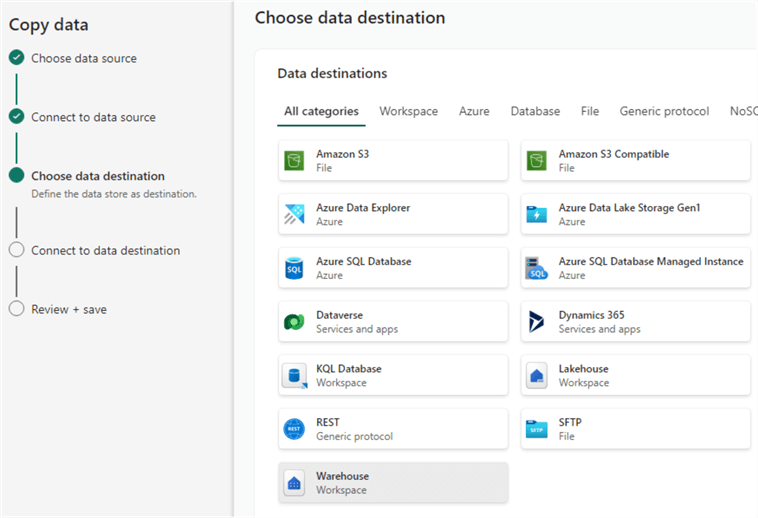
Before we start, ensure you have created a Fabric Warehouse in your Fabric workspace. If you're unsure how check out this tip: What are Warehouses in Microsoft Fabric? Next, we're going to load some sample data into our warehouse. Create a new pipeline (check out Microsoft Fabric Data Ingestion Methods and Tools for more info) and choose the option to copy data. In the wizard, choose NYC Taxi – Green as the data source.

As the destination, choose the Warehouse:
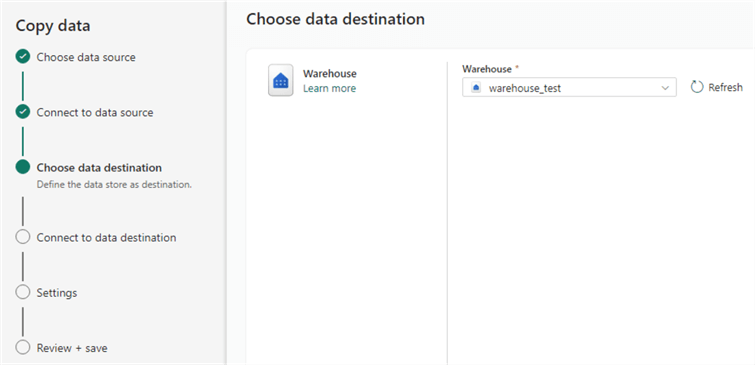
Choose the warehouse you created from the dropdown (hit refresh if it does not appear in the list):
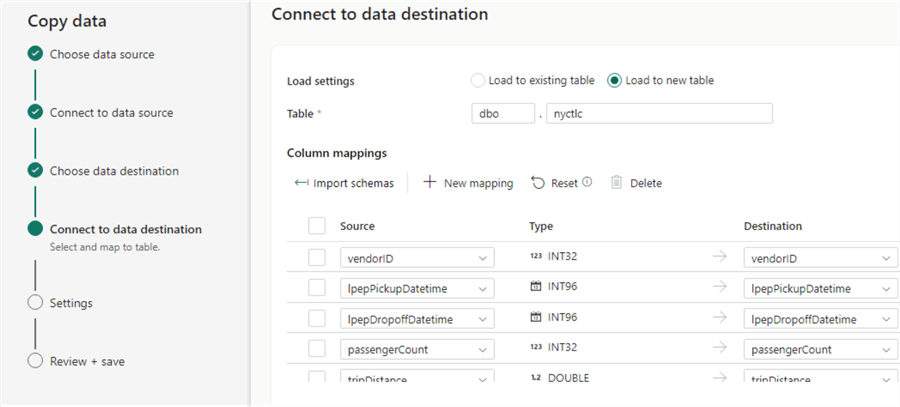
Configure the pipeline to load to a new table:
Leave everything else to the default and choose to immediately run the pipeline after creation.
After some time, the data should have been copied to your new table.
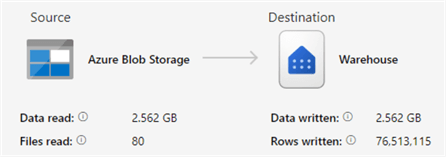
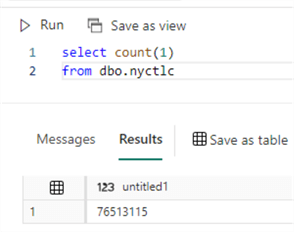
The table consists of approximately 76.5 million rows.
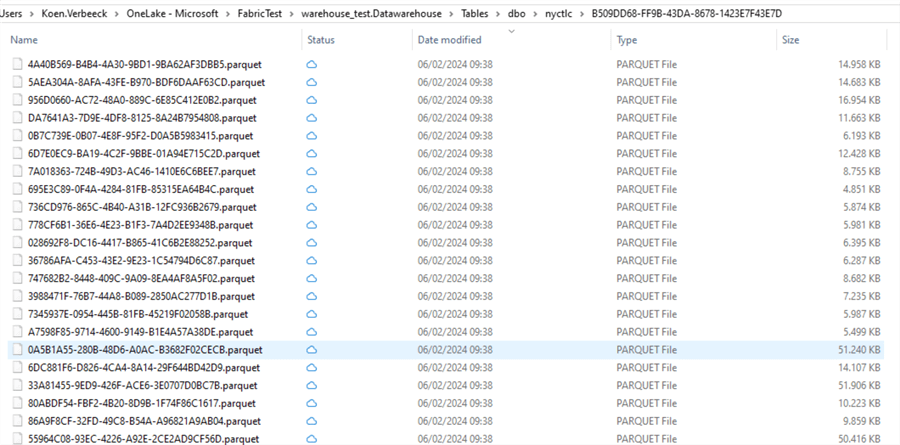
If we take a look at the actual files behind the table (using either Azure Storage Explorer or OneLake file explorer), we can see a whole bunch of Parquet files have been created:
Automatic Data Compaction
When DML statements (UPDATE, DELETE, INSERT, etc.) are run on the table, the data is changed. However, it is not possible to update the actual contents of a Parquet file. Instead, new Parquet files will be written with the changed data. The delta transaction log dictates which Parquet files are valid for which point in time. This means that over time, more and more Parquet files will be added to the underlying storage system, even though it's possible your total row count hasn't changed (or even decreased in the case of deletes)! To improve performance, data compaction will re-write smaller Parquet files into a couple of larger Parquet files. In the Fabric Warehouse, this is an automatic process that can be triggered when you execute queries (such as a SELECT statement).
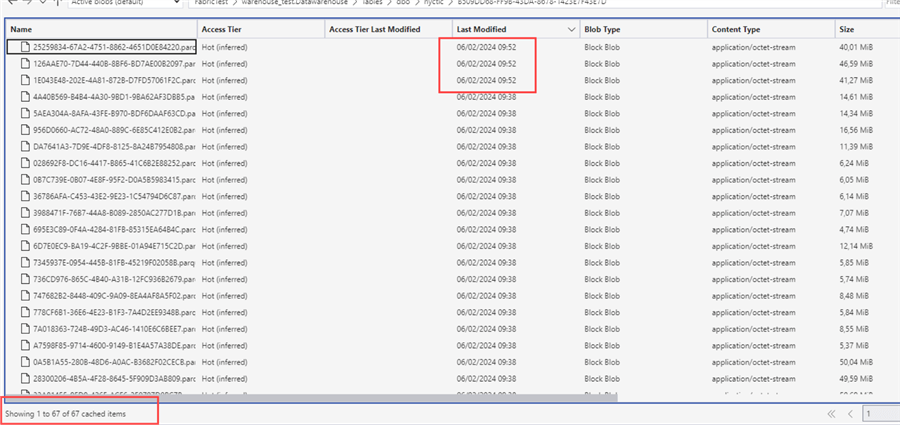
In fact, when we issued the SELECT COUNT(1) statement to count the rows of the table, data compaction had already taken place! We first had 64 Parquet files, but after running the SELECT statement, we have three more Parquet files:
We can observe the following files in the transaction log:

File 00.json holds details about the DDL statement that created the table, file 01.json explains which Parquet files were added to the table after loading the data, and file 02.json details the data compaction after the SELECT statement. In this last file, we can inspect the following:
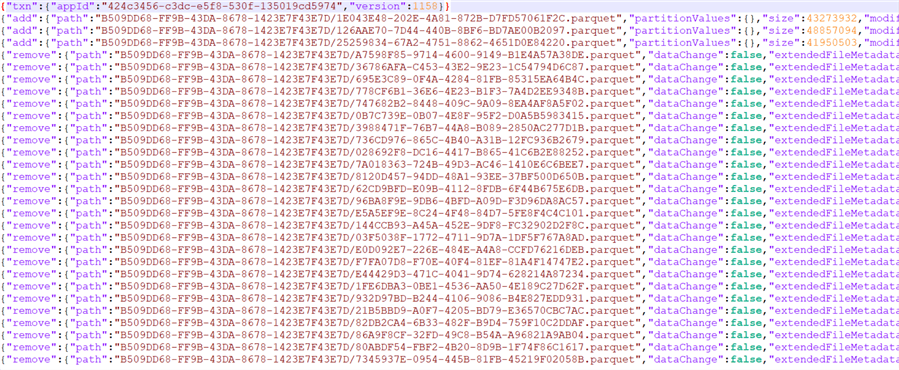
After the first line with version info, we see three lines detailing which Parquet files have been added. In all the lines after, we can see which existing Parquet files have now been removed from the table. The folder now contains 67 Parquet files, but the current version of the table consists of 41 Parquet files (64 + 3 – 21 = 41). The "old" Parquet files are still there because delta tables support time travel, so you can query the table as it was before the compaction (the results will be the same since no actual data has been changed). But because fewer Parquet files need to be read – and because data is better compressed in bigger files – performance should improve.
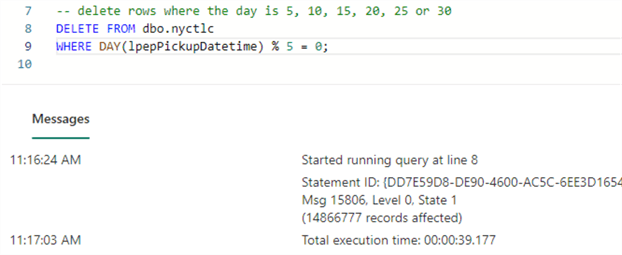
Let's modify the data with a DELETE statement to see what happens. With the following SQL statement, we will delete every record for which the day of the taxi pick-up can be divided by 5 using the modulo operator (so the 5th, 10th, 15th, 20th, 25th, or 30th of the month):
-- delete rows where the day is 5, 10, 15, 20, 25 or 30 DELETE FROM dbo.nyctlc WHERE DAY(lpepPickupDatetime) % 5 = 0;
This statement took about 40 seconds to run on an F4 capacity and deleted around 14.8M rows:
When we look at the transaction log, we can see another file has been added:
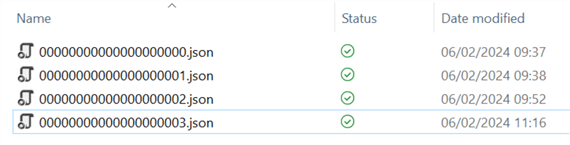
In file 03.json, all 41 current Parquet files have been removed but have been readded with a deletion vector.

A deletion vector is an improvement technique used in delta tables when records are deleted. Since you cannot actually delete (or update) records, deleting a record means the entire Parquet file needs to be written to another file, but without the deleted record. Since this causes significant overhead, soft-deleting records is implemented. A deletion vector keeps track of all the deleted rows in the different Parquet files. When a file is read, the system will check the deletion vector to see if certain records can be discarded.
In the previous screenshot of the transaction log, we can see that all Parquet files were "removed" but added back. This time, a reference to the deletion vector is included. When we format the JSON of a single line of the log, we can see the following:
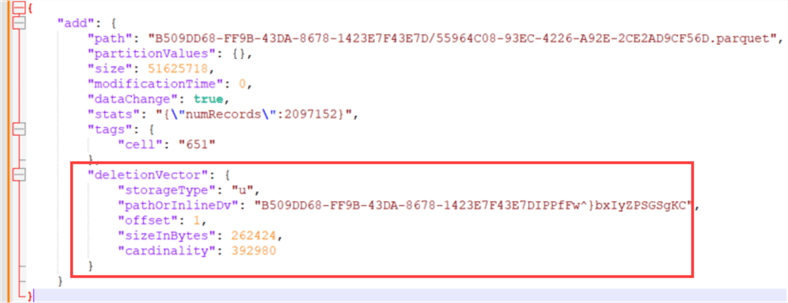
A reference to the deletion vector is included at the end of the information about that particular Parquet file. If you want to learn more about deletion vectors, how they work, and what performance improvements they bring, you can check out the official delta documentation.
When we take a look at the data folder of our table, we can see the actual deletion vector:

Of course, a deletion vector speeds up the actual deletes because entire Parquet files don't have to be rewritten, but when you read data, the deletion vector has to be consulted. At some point, the Parquet files will need to be optimized again; this is where the automatic data compaction comes into play.
When this is triggered, an analysis will run to see which Parquet files will benefit from being rewritten. In other words, which files have lots of deleted records? When a compaction is triggered – for example, by running a SELECT statement – we can see another log file is added:
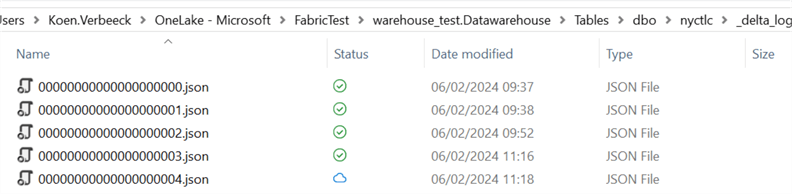
Log file 04.json details how four Parquet files are "removed" (again, they're still in the folder for time travel purposes) and one new Parquet file is added. Those four files probably had the highest ratio of deleted records versus the total records in the file.
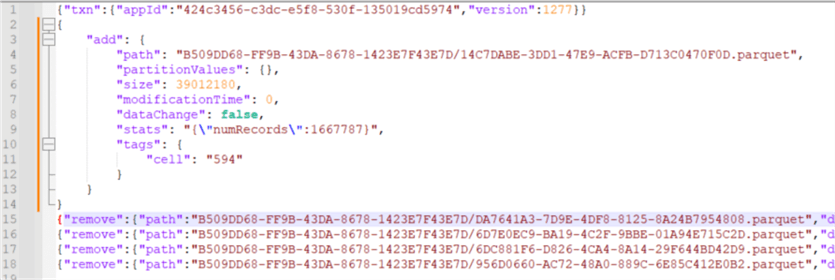
This new Parquet file now holds the data of those four Parquet files but without the deleted records. The screenshot shows that this file has no reference to the deletion vector.
At the time of writing, it is impossible to do a forced cleanup of all Parquet files. In the next part of the tip, we'll explore the concepts of checkpoints and statistics in the Fabric warehouse.
Next Steps
- Try it out yourself! There's a Fabric trial you can use, or you can create a cheap F2 capacity to run your Fabric workspace on.
- The official blog post about automatic data compaction: Announcing: Automatic Data Compaction for Fabric Warehouse.
- You can find more Fabric tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-03-27
