By: Koen Verbeeck | Updated: 2024-04-10 | Comments | Related: 1 | 2 | 3 | 4 | 5 | > Microsoft Fabric
Problem
We're using the warehouse functionality of Microsoft Fabric, and we've already created a couple of tables. Data is loaded into the tables, and reports are running on top of them. Coming from a SQL Server background, do we have to do the same types of maintenance? For example, in SQL Server, we needed to perform maintenance on tables, such as updating statistics, removing fragmentation, or making sure the log files of the database didn't grow out of bounds. Are these tasks still required?
Solution
In Part 1 of this tip, we've established some maintenance is required for the warehouse tables in Microsoft Fabric. However, some parts – like the automatic data compaction of the different Parquet files of the delta table – are automated by the system. In this tip, we'll delve into other aspects of table maintenance:
- Checkpointing of the transaction log, which is also automated.
- Statistics, which are also created and updated automatically but can also be manually created or updated through a script.
In Part 1, we showed how to load some sample data into a warehouse. We're using the same table and transaction log, so it's recommended that you read the first part if you haven't already. You can get a free Fabric trial if you want to follow along. Keep in mind that Microsoft Fabric is a fast-moving product with regular updates, which means some of the functionality may have been expanded, changed, or improved by the time you read this.
Table Maintenance in the Fabric Warehouse
Checkpointing
Up until this point, we have done the following actions on our sample table (see Part 1):
- Creating the table
- Inserting data into the table
- Selecting data from the table (triggering the first data compaction)
- Deleting data
- Selecting data from the table (triggering the second data compaction)
This resulted in five JSON log files for the delta table. You can imagine that if lots of transactions are on the table, many log files are created. Each time we read data from the table, all transaction log files need to be read. When there are many transaction log files (suppose you have a streaming process inserting data regularly), this will become less efficient over time. To solve this problem, the system creates a checkpoint after every 10 transactions. A checkpoint file contains a summary of the previous log files, which means that when data is read, only the checkpoint file and log files created after this checkpoint file need to be read. In other words, instead of reading all transaction log files, only 10 or fewer files need to be read.
It is important to know that there are multiple transaction logs. Two are hidden: the internal transaction logs for the warehouse itself and the SQL analytical endpoint. The only transaction log we can actually see is the delta table transaction log. Checkpointing happens for all three logs, but we can only observe the behavior in the delta log.
Let us look at this process in action. First, let's add some transactions by deleting records. The following statements are run one at a time, resulting in separate transactions for each statement.
delete from dbo.nyctlc where lpepPickupDatetime = '2016-06-28 07:57:19.000000'; delete from dbo.nyctlc where lpepPickupDatetime = '2016-06-28 07:52:32.000000'; delete from dbo.nyctlc where lpepPickupDatetime = '2016-06-28 08:58:32.000000'; delete from dbo.nyctlc where lpepPickupDatetime = '2016-06-11 12:52:18.000000';
At this point, we're at exactly 10 transaction log files. When we run another delete statement, another transaction log file is created.
delete from dbo.nyctlc where lpepPickupDatetime = '2016-06-11 12:52:00.000000';
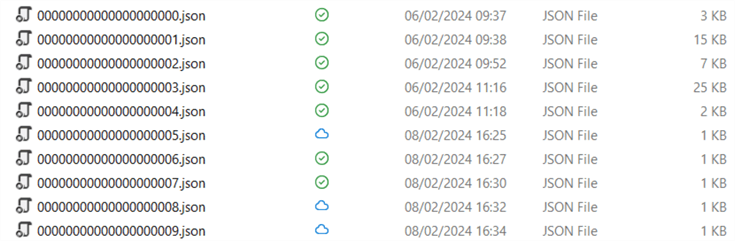
A checkpoint file wasn't automatically created. One minute later, I ran a SELECT COUNT on the table, and at that time, a checkpoint was created. (This might have been triggered by the SELECT, or there was perhaps an automatic asynchronous process at the same time.):
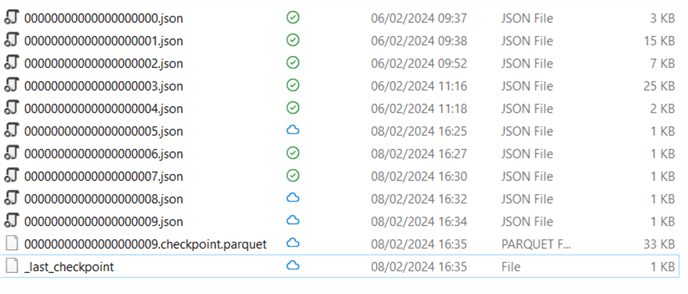
The contents of _last_checkpoint are the following:
{"version":9,"size":117,"sizeInBytes":33032,"numOfAddedFiles":38}
It points to the last known checkpoint and has more information on the size and the number of Parquet files. The last checkpoint file (09.checkpoint.parquet) is not a JSON file but a Parquet file. It's a bit hard to read. (I opened the file with a Parquet file reader, and it showed mostly empty data because there are a lot of nested structures in it). But, if you open it with Power Query in Power BI Desktop, you can get some sense of the data that's in there:
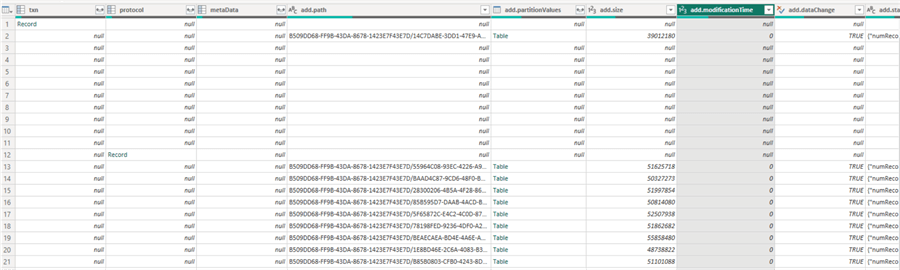
It's a condensed version of all the previous log files so that by reading only this single checkpoint file, the system can construct a correct transaction log history of the table.
Statistics
Just like in SQL Server, the query engine of the Fabric warehouse uses statistics to produce an optimal plan (the one with the least amount of estimated work). To have efficient query performance, it's important statistics are up-to-date. Again, similar to the SQL Server database engine, you can create statistics manually or have them created and updated automatically. Since the concepts are similar, you can learn more about SQL Server statistics in the following tips:
- Importance of Update Statistics in SQL Server
- SQL Server Auto Update and Auto Create Statistics Options
Using our sample table, let's dig a bit deeper into its statistics. With the following query (retrieved and adapted from the documentation), we can find out which automatically created statistics exist for our table:
SELECT
[object_name] = object_name(s.object_id)
,column_name = ISNULL(c.name,'N/A')
,stats_name = s.name
,s.stats_id
,stats_update_date = STATS_DATE(s.object_id, s.stats_id)
,s.auto_created
,s.user_created
,s.stats_generation_method_desc
FROM sys.stats s
JOIN sys.objects o ON o.object_id = s.object_id
LEFT JOIN sys.stats_columns sc ON s.object_id = sc.object_id
AND s.stats_id = sc.stats_id
LEFT JOIN sys.columns c ON sc.object_id = c.object_id
AND c.column_id = sc.column_id
WHERE o.type = 'U' -- Only check for stats on user-tables
AND s.auto_created = 1
-- AND o.name = '<YOUR_TABLE_NAME>'
ORDER BY object_name, column_name;
The following results are returned:
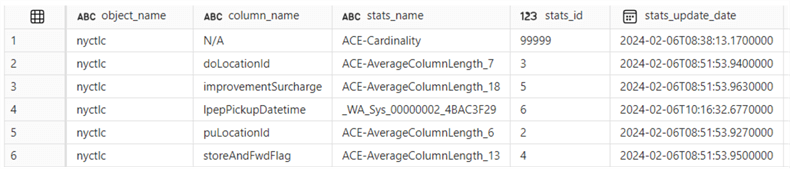
The first statistic with the cardinality estimation was created when the table was populated with data. (You can cross-check with the transaction log files timestamps but add one hour since this query returns the dates in UTC). The statistics for the columns doLocationId, improvementSurcharge, puLocationId, and storeAndFwdFlag were created after the first automatic data compaction. The statistic for IpepPickupDatetime was created before the first big delete statement. This last one is a histogram statistic, just like in SQL Server.
With DBCC SHOW_STATISTICS, we can get more information about this histogram:
DBCC SHOW_STATISTICS ('nyctlc', '_WA_Sys_00000002_4BAC3F29');

This statistic is a bit out-of-date since we deleted about 1/5th of the table. With the following statement, we can update it (if you don't specify a specific statistic, everything should be updated):
UPDATE STATISTICS dbo.nyctlc (_WA_Sys_00000002_4BAC3F29) WITH FULLSCAN;
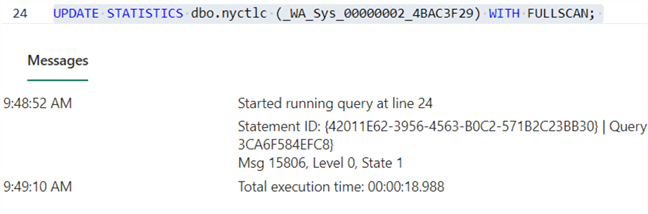
When we run the DBCC statement again, we can see the histogram is now up to date:

Next Steps
- If you haven't already, check out Part 1 of this tip, where the sample data is loaded into the warehouse and where automatic data compaction is discussed.
- If you want to learn more about the performance impact statistics can have, check out the tip: How Incorrect SQL Server Table Statistic Estimates Can Cause Slow Query Execution.
- SQL Server itself also has a concept of checkpoints to write pages from the buffer cache to disk. You can learn more about this in the tip: Indirect Checkpoints in SQL Server 2012.
- You can find more Fabric tips in this overview.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-04-10
