By: Andrea Gnemmi | Updated: 2024-05-23 | Comments | Related: > PostgreSQL
Problem
After creating a PostgreSQL database, the next step is creating tables which we will cover using the PostgreSQL CREATE TABLE command.
Solution
In this tutorial, we will review the syntax, features, and options of the CREATE TABLE command in PostgreSQL.
CREATE TABLE
The CREATE TABLE statement has many options and features. In this tip, we will review the most important ones and some of the peculiarities of the CREATE TABLE statement in PostgreSQL.
Simple Example for CREATE TABLE
So, first of all, the basics with an example.
Here is the syntax to create a table named "test" with two columns "id" and "description".
create table test (id bigint, description varchar(50));
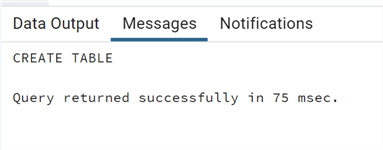
Using pgAdmin, we can see table "test" was created with the 2 columns.
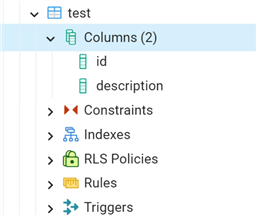
Schema
A schema is a way to categorize and group database objects.
We didn't specify a schema when we created the table above, so the default schema was used, which is probably "public", unless it was changed.
We can find the default schema using this command:
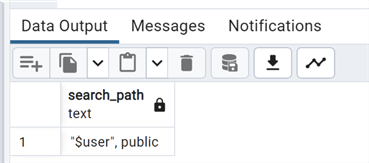
show search_path;
The search path displays the default schema in the session.
Owner
Another thing that is automatically set by default, if not specified, is the OWNER of the table. This is quite important as the owner automatically has all privileges on the table.
By default, the owner is the role/user connected to the database when the CREATE TABLE command is run. We can check this in pgAdmin by right-clicking the table and selecting Properties from the menu:
We can see below the owner is "postgres".
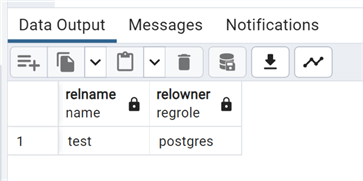
We can also use this script to check the pg_class catalog. This command uses the ::regrole statement to get the name.
--MSSQLTips.com select relname, relowner::regrole from pg_class where relname='test';
We can see the owner is "postgres".
Change the Table Owner
We can modify the owner of a table by issuing an ALTER TABLE command.
Let's create a new table including the schema and then change the owner.
--MSSQLTips.com
CREATE TABLE "Finance".test
(id bigint,
description character varying(50));
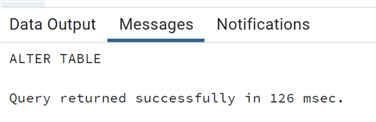
ALTER TABLE "Finance".test owner to "Finance";
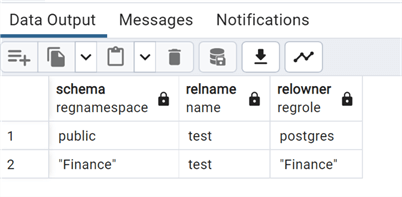
We can now check the pg_class catalog to get schema, table and owner.
--MSSQLTips.com select relnamespace::regnamespace as schema, relname, relowner::regrole from pg_class where relname='test';
IF NOT EXISTS
One of the features that I particularly like in PostgreSQL CREATE TABLE, is using the IF NOT EXISTS clause to avoid getting an error if the database object already exists.
Let's do an example and try to create a table that already exists:
--MSSQLTips.com
CREATE TABLE IF NOT EXISTS "Finance".test
(id bigint,
description character varying(50));
ALTER TABLE "Finance".test owner to "Finance";
As you can see, we do not receive an error just a message that the table already exists.
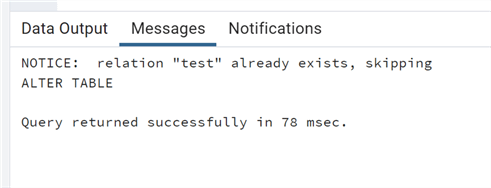
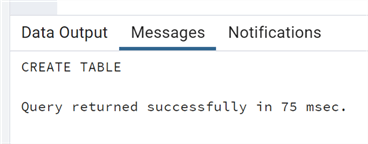
If we change the table name to a table that does not exist we can see this completes fine and the new table is created.
--MSSQLTips.com
CREATE TABLE if not exists "Finance".testexists
(id bigint,
description character varying(50));
ALTER TABLE "Finance".test owner to "Finance";
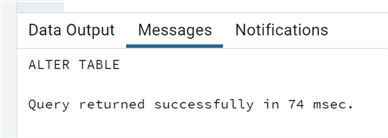
TEMP OR TEMPORARY Table
In PostgreSQL, we add the clause TEMP (or TEMPORARY) to the CREATE TABLE command to create a temporary table.
--MSSQLTips.com CREATE TEMP TABLE test_temporary (id bigint, testdescr varchar);
Quite simple, but some interesting features can also be implemented, such as the persistence of the temporary table. In fact, as a default, a temporary table is automatically dropped at the end of the session that created it but optionally, we can also specify a drop of the table if we want.
Temp Table with ON COMMIT DROP
Here is a simple example to create a table using the ON COMMIT DROP option and inserting a record.
--MSSQLTips.com CREATE TEMP TABLE test_temporary (id bigint, testdescr varchar) on commit drop; insert into test_temporary values(1,'test');
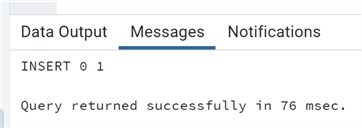
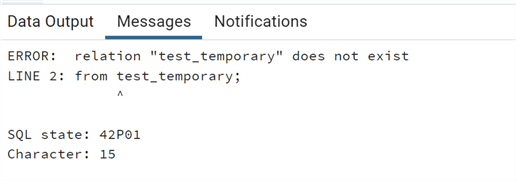
Now if we try to query this temporary table:
--MSSQLTips.com select * from test_temporary;
We get a message that the table does not exist. This is because once the query was committed the temp table was dropped.
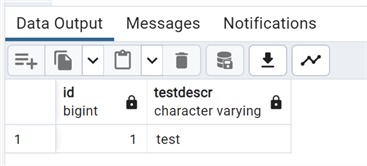
If we do the select at the same time, this works since the temporary table still exists:
--MSSQLTips.com CREATE TEMP TABLE test_temporary (id bigint, testdescr varchar) on commit drop; insert into test_temporary values(1,'test'); select * from test_temporary;
Temp Table with ON COMMIT DELETE ROWS
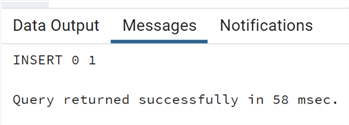
If we want to delete all of the rows from the temporary table at the end of the transaction we can use ON COMMIT DELETE ROWS:
--MSSQLTips.com CREATE TEMP TABLE test_temporary2 (id bigint, testdescr varchar) on commit delete rows; insert into test_temporary2 values(1,'test');
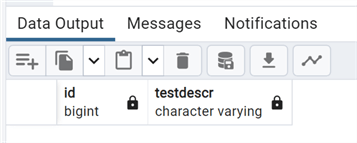
Querying the table now outside the transaction, we'll see the table still exists but there are no rows in it:
--MSSQLTips.com select * from test_temporary2;
But if we do it all in the same transaction:
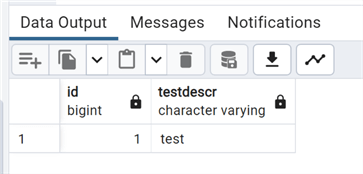
--MSSQLTips.com drop table if exists test_temporary; CREATE TEMP TABLE test_temporary (id bigint, testdescr varchar) on commit delete rows; insert into test_temporary values(1,'test'); select * from test_temporary;
We can see this works and shows the data.
Temp Table with ON COMMIT PRESERVE ROWS
There is one last option that can be used which is the default behavior, ON COMMIT PRESERVE ROWS. This is similar to how SQL Server works.
Temp Table Info
An important note on temp tables. They are not vacuumed by default. What is VACUUM? VACUUM is the process that fulfills two items with PostgreSQL MVCC: it marks dead tuples as no longer visible and it prevents the wraparound of transaction ids. When we delete or update from a table, there is a second step of VACUUM to mark the tuples as no longer visible. I will write a tip in the future about VACUUM and AUTOVACUUM as they are very important concepts with many parameters used to enhance performance.
LIKE SOURCE TABLE
A nice feature in the PostgreSQL CREATE TABLE command is the ability to easily build a new table by copying the structure from another existing table, using the LIKE <SOURCE TABLE> option. Let's look at it!
Suppose we want to create a new table based on the Chinook database Album. For those new to my tips, this is a free downloadable database on Github, available in multiple RDBMS. It is a simulation of a digital media store with sample data. All you have to do is download the version you need, and you will have all the scripts for data structure and all the Inserts for data.
Here is a sample command.
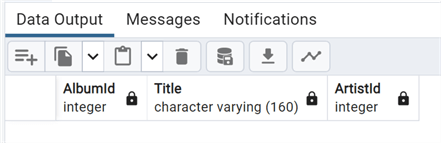
--MSSQLTips.com create table if not exists test_like (like "Album");
Taking a look at this new table, we see that it has the same structure as the source table, but there is no data in it, as it is not a create table done with a select/insert:
select * from test_like;
INCLUDE Options
We have some interesting options available if we want to include or exclude other objects related to the source table. In fact, by default, it includes all column names, their data types, their not-null constraints, and nothing else.
We can then use the INCLUDE option to include objects such as identity columns, indexes, comments, defaults, etc.
Let's make an example. If we check the Album and test_like tables, we see that Album has an index that is not in the test_like table:
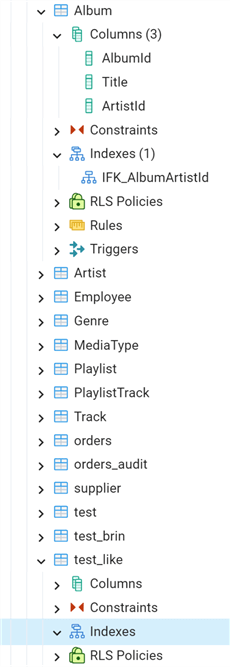
We can also include the indexes as follows:
--MSSQLTips.com drop table if exists test_like; create table test_like (like "Album" including indexes);
Let's recheck it:
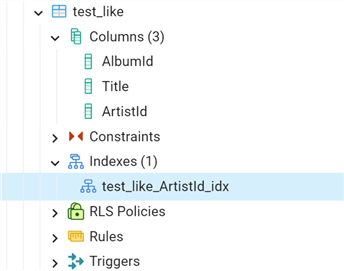
The index name is automatically generated using the table and column names.
INCLUDE ALL and EXCLUDE OPTIONS
We can also use the option INCLUDE ALL and then use EXCLUDE to keep out just some objects:
--MSSQLTips.com
COMMENT ON COLUMN public."Album"."AlbumId"
IS 'test comment';
--First add a comment on column AlbumId
drop table if exists test_like;
create table test_like (like "Album" including all excluding comments);
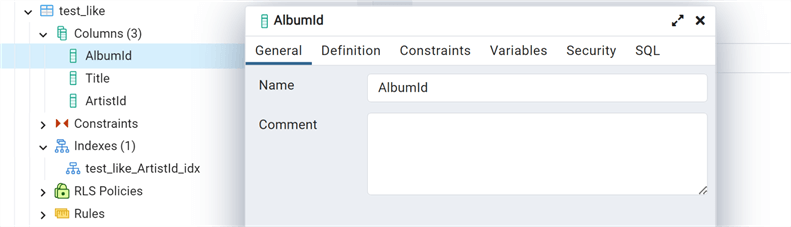
We have the index but not the comment.
INHERITS TABLE
This option of the CREATE TABLE statement is similar to the one we just analyzed. In this case, we can tie two tables hierarchically. In past versions of PostgreSQL (until version 10), it was also used to implement table partitions instead of the actual declarative partitioning. Let's do a quick example of table inheritance using the invoice table that we moved to the Finance schema
First, let's take a look at the list of tables under the Finance schema in pgAdmin:
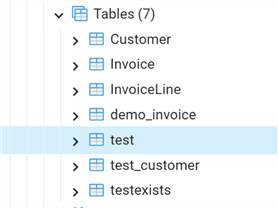
Then run this script:
--MSSQLTips.com
create table if not exists "Finance".demo_invoiceline (order_delivered timestamp)
inherits ("Finance"."InvoiceLine");
Now, let's refresh the list:
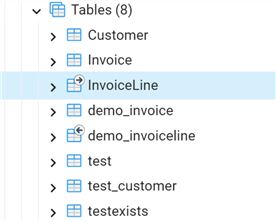
Notice above, the table InvoiceLine has an arrow going away from it, and the new table, demo_invoiceline, has an arrow coming in. This is how pgAdmin graphically represents the inheritance between parent and child tables.
Now, let's take a look at the demo_invoiceline table:
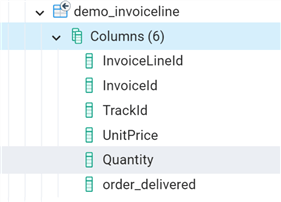
We see the columns are the same as the InvoiceLine table plus the order_delivered table that we explicitly declared.
Now, we can try to query this table:
--MSSQLTips.com select * from "Finance".demo_invoiceline

As expected, it is empty.
Let's try to insert a row in it:
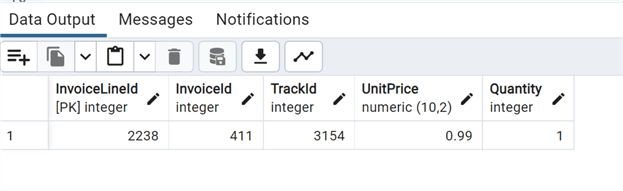
--MSSQLTips.com insert into "Finance".demo_invoiceline values (2239,411,3163,0.99,1,now());
Now, let's query the demo_invoiceline table again:
--MSSQLTips.com select * from "Finance".demo_invoiceline;
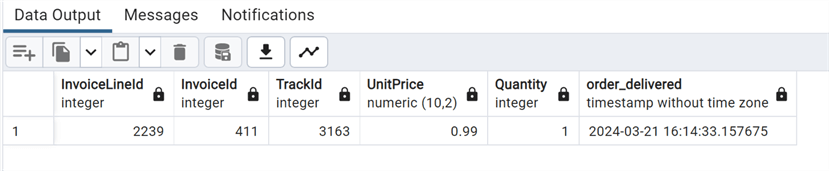
As expected, we see the row that we have inserted. So far, all is normal.
Let's query the parent table InvoiceLine where table demo_invoiceline was inherited:
--MSSQLTips.com select * from "Finance"."InvoiceLine" where "InvoiceLineId">=2238;
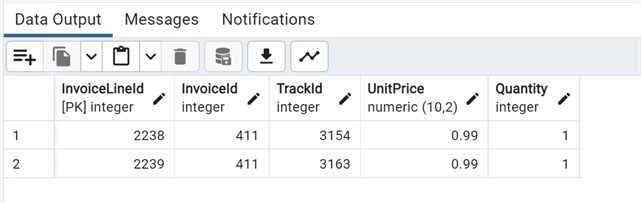
We can see that the same row is also present in the parent table (minus the column we added), as the use of Inheritance creates a persistent relationship between the child table and its parent table. Any schema modifications to the parent table propagates to the child table as well, and by default, the data of the child table is included in queries on the parent.
If we want to obtain only the rows of the parent table with a select query, we must specify the ONLY clause:
--MSSQLTips.com select * from only "Finance"."InvoiceLine" where "InvoiceLineId">=2238;
PARTITION BY
Another important feature of the CREATE TABLE is the ability to make a partitioned table using the PARTITION BY clause. See my previous tip, PostgreSQL Partitioning Tables - Learn the Syntax, Features and Options, , for more details.
UNLOGGED TABLE
Last but not least, there is a feature that can transform one of our tables into a NoSQL table: the unlogged table!
Creating a table with the option UNLOGGED means that all data written to it is not written to the write-ahead log (WAL), also known as the transaction log in PostgreSQL. Thus, they are extremely fast but not safe; in a crash, we can lose all data in an unlogged table. So, this type of table is to be used carefully and for data that does not need persistence.
Here's an example creating a new unlogged table:
--MSSQLTips.com create unlogged table test_unlogged (idun bigint generated always as identity, description1 text, description2 text);

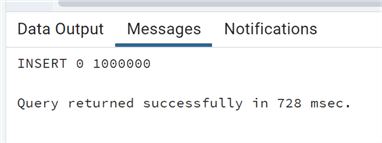
Let's insert 1 million rows into this table:
--MSSQLTips.com insert into test_unlogged (description1,description2) select 'test'||generate_series(1, 1000000), 'test2'||generate_series(1, 1000000);
Let's try the same with a normal table:
--MSSQLTips.com create table test_logged (idun bigint generated always as identity, description1 text, description2 text); insert into test_logged (description1,description2) select 'test'||generate_series(1, 1000000), 'test2'||generate_series(1, 1000000);
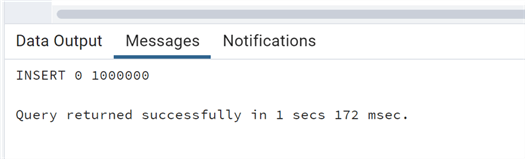
For 1 million rows, we can see that the time spent by the insert is almost doubled.
But let's see what happens with an update of all the rows and the WAL. First,
we check the actual size of the WAL with the query below on the system function
pg_ls_waldir() that returns
the list of files in the pg_wal directory with their size:
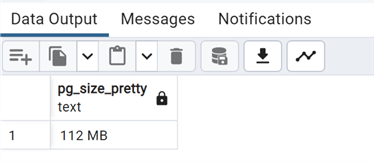
--MSSQLTips.com select pg_size_pretty(sum(size)) from pg_ls_waldir();
Now, we can update all rows on the logged table:
--MSSQLTips.com update test_logged set description1=description1||'a', description2=description2||'b';
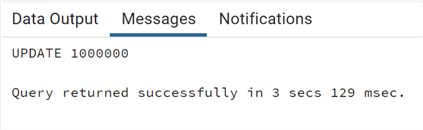
And now, let's take a look at the WAL size with the same query as before:
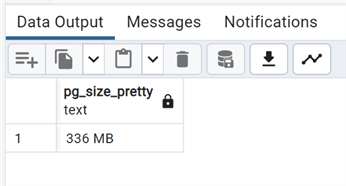
We can see a substantial increase in the WAL, from 112 to 336 MB. Now we'll repeat with the unlogged table:
--MSSQLTips.com update test_unlogged set description1=description1||'a', description2=description2||'b';
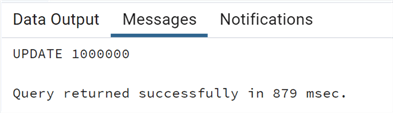
We already see that the time used is less than a third of what was used before. Now let's see the WAL:
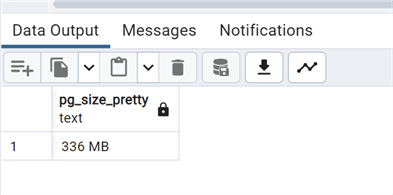
As expected, the WAL has not grown.
We have seen substantial performance improvements by using an unlogged table. The drawbacks are also significant as we trade speed for durability: not writing in the WAL means there is no point in time recovery, and the table cannot be rebuilt in case of a crash. Thus, it is automatically truncated. If the database crashes and we restart it gracefully, the unlogged table is not truncated. Other drawbacks are the inability to backup an unlogged table or have it replicated with a logical replica (not writing to the WAL makes that impossible).
Summary
This tip has demonstrated the most important features and syntax of the CREATE TABLE statement, as well as some other system queries and features.
Next Steps
- PostgreSQL Official Documentation
- SQL SELECT INTO Examples
- DROP TABLE IF EXISTS Examples for SQL Server
- SQL Server and Oracle Create Table Comparison






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-05-23
