By: Koen Verbeeck | Updated: 2024-05-29 | Comments | Related: > Microsoft Fabric
Problem
We have a couple of source databases hosted in Azure SQL Database (DB). We want to analyze data from several tables in our Microsoft Fabric environment. However, we don't want to load the data using batch jobs (with either pipelines or Spark notebooks) but rather have the data (near) real-time available. KQL databases don't seem to be the right option for us. Are there any alternatives?
Solution
A new feature was released in public preview at the inaugural Fabric Community Conference 2024: mirroring. The feature was already announced in November 2023 but is now available to the public to try out. At the time of writing, this feature is still in public preview.
Mirroring provides an easy-to-set-up data replication of a source database into Microsoft Fabric. The process is made as simple as possible, resulting in a near real-time duplication of your source tables into Fabric. Inside Fabric, the data will be stored in Parquet files with the delta format, as pretty much everything in OneLake.
This means you don't have to write complicated ETL; pipelines do the replication for you. An initial snapshot will be created, and once loaded, the data will be kept in sync using the source database's change data capture (CDC) technology. The process is also intelligent enough to detect when changes are made, so there's no wasted Fabric compute capacity. Currently, the following databases are supported as a source:
- Azure SQL Database
- Snowflake
- Azure Cosmos DB
In the future, other databases will be added to this list. Don't confuse the new mirroring feature of Microsoft Fabric with database mirroring in SQL Server (now deprecated and replaced with Always-On Availability Groups) or with SQL Server replication. Both features are more intended for high-availability and disaster recovery scenarios, while mirroring in Microsoft Fabric intends to be a low-code, no-ETL solution to get source data into an analytical environment. The Fabric mirroring feature is similar to the Azure Synapse Link features but not identical.
To illustrate the concept, we will mirror an Azure SQL DB into Fabric in this tip.
How to Set Up Mirroring for Azure SQL Database
The tip, How to Install the AdventureWorks Sample Database in Azure SQL Database, explains how to configure a new instance of Azure SQL DB with some sample data. To make mirroring possible in Azure SQL DB, we need either a vCore purchasing model or a service tier of at least 100 DTUs (see the documentation for more information). Currently, the source database must also allow public network access, and the Allow Azure Services option must be enabled (located in the Networking tab of the logical SQL Server hosting the Azure SQL DB).

The system-assigned managed identity of the logical SQL Server needs to be enabled as well. This can be found in the Identity section.
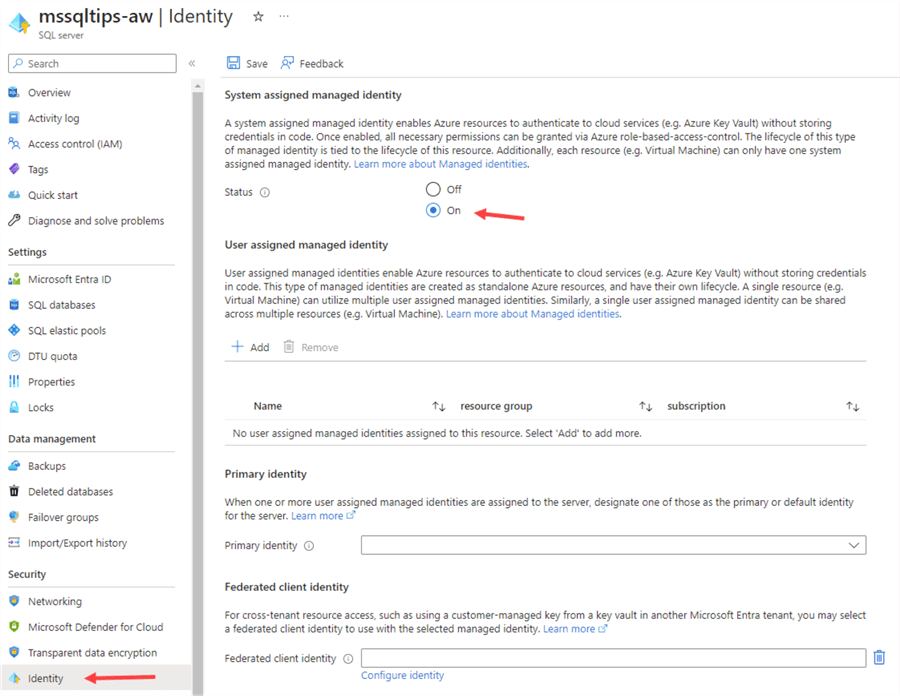
Before we start configuring the mirroring, we need to make sure the mirroring feature is enabled in the tenant settings. In the top right corner, select the gear icon and choose Admin portal.
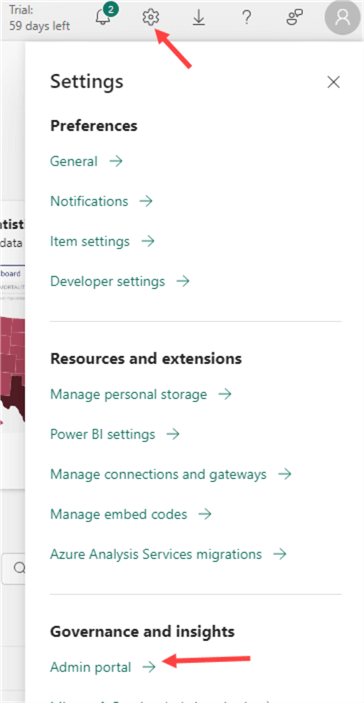
In the Admin portal, go to Tenant settings and then to the settings for Database Mirroring.
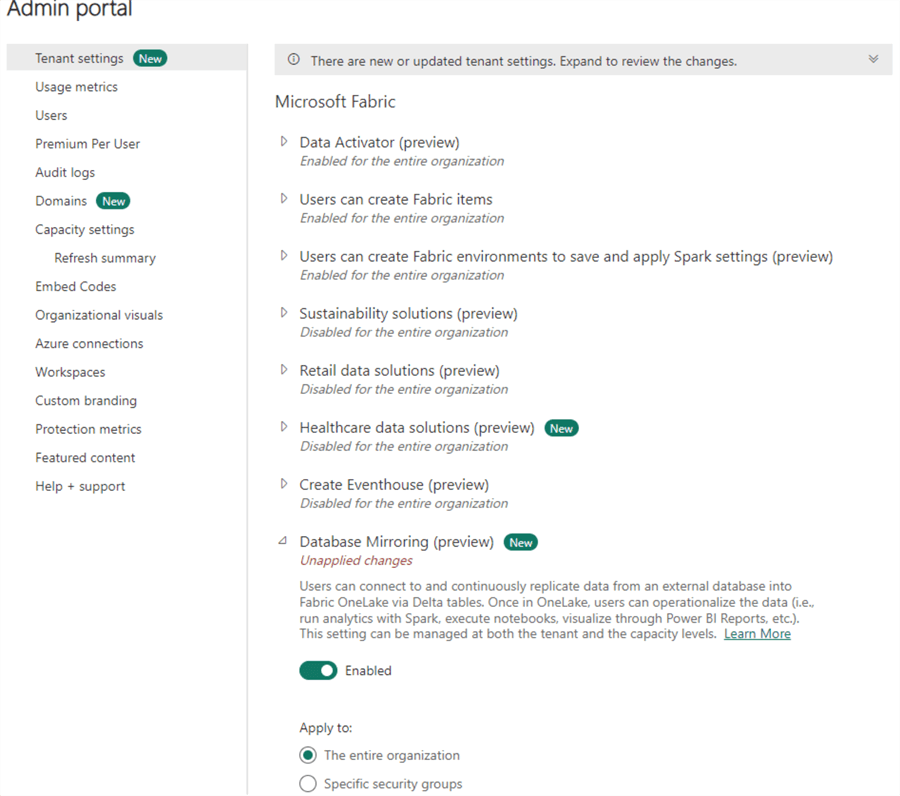
You can enable mirroring for the entire organization or give specific security groups access to the feature (recommended). The documentation also mentions the setting Allow service principals to user Power BI APIsneeds to be enabled, but it is unclear what purpose this serves.
After saving the settings, exit the Admin portal. In the bottom-left corner of the Power BI service, choose the Data Warehouse persona.

In the New section, you can select the option to create a Mirrored Azure SQL Database.
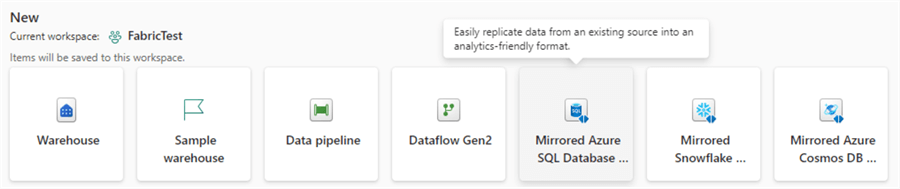
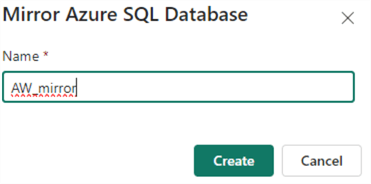
Give the new mirrored database a name:
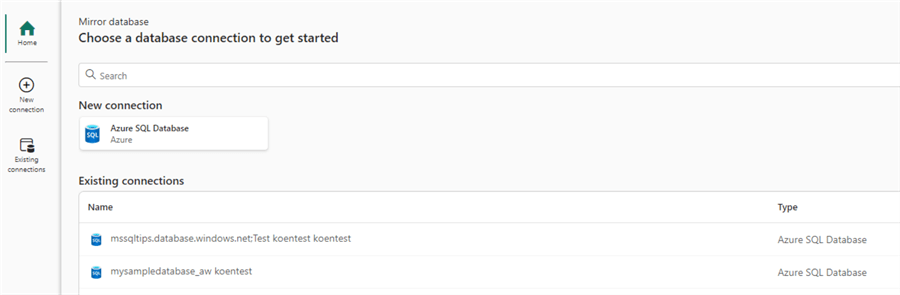
The next step is to create the source connection. You can either create a new one or choose from existing connections.
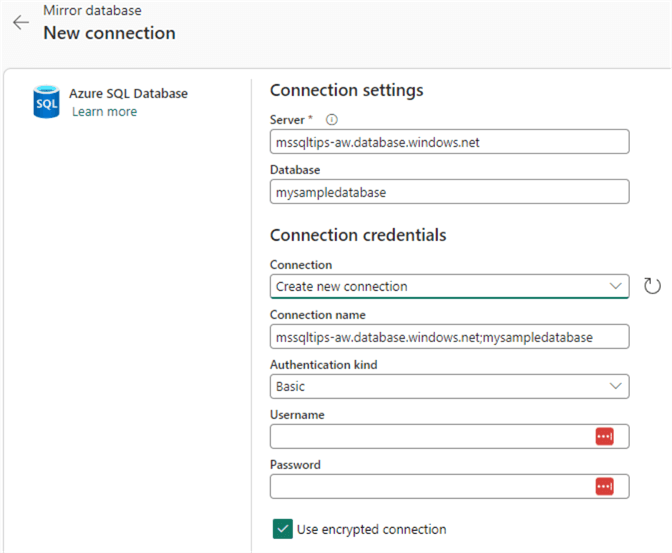
When you create a new connection, enter the server and database name:
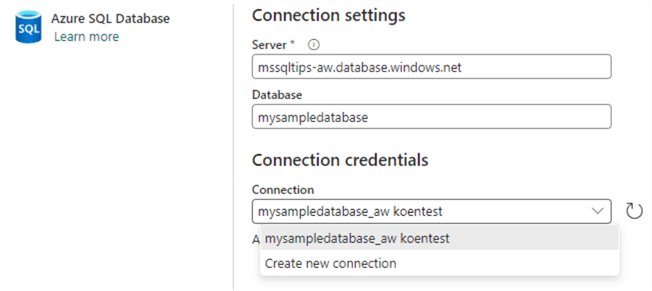
If someone in your organization has already created a connection to the same database, Fabric will detect this and reuse the credentials used by that connection. However, you can override this by using the dropdown to select Create new connection.
This might be useful if you want to use your own set of credentials: you might have more privileges on the database or want to use another authentication method. The different authentication methods are:
- Basic – This is SQL Server authentication with a username and password. You'll need to create a login on the master database and then create a user from that login on the database you want to mirror. The login needs to be assigned to the ##MS_ServerStateReader## server role (this is required in order to check if the managed identity exists). The minimum permissions needed for the user are CONTROL or db_owner, so the principle of least privilege doesn't really apply here.
- Organizational Account – Here, you use your Azure Entra ID to log in. You can use your own, but this is not recommended. You can create a specific Azure Entra ID user and give this user the necessary permissions.
- Service Principal – You'll need to create an app registration in Azure Entra ID and a secret for it.
The following script will add a login named [fabric-service-principal] to the master database and assign the necessary permissions. The user can either be a service principal or an actual Azure Entra ID user. It will also create a user called [fabric-user] in the source database (don't forget to switch context) and assign the CONTROL permission.
-- master CREATE LOGIN [fabric-service-principal] FROM EXTERNAL PROVIDER -- source db CREATE USER [fabric-user] FOR LOGIN [fabric-service-principal] -- master ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [fabric-service-principal]; -- source db GRANT CONTROL TO [fabric-user];
Once you've established the connection, you can advance to the next screen to configure the mirroring. Choose to either Mirror all data or Mirror only a subset of tables. When you disable Mirror all data, a list of tables will appear to choose from. If a table cannot be mirrored, an error indicator will be shown:
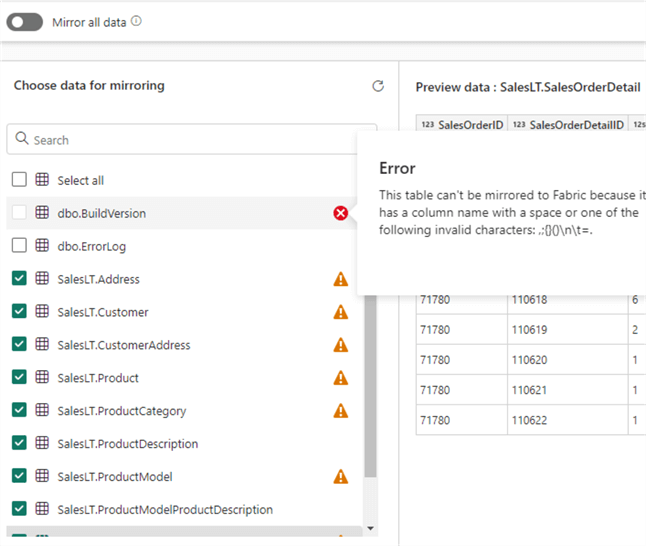
If a table contains columns that cannot be mirrored, a warning indicator will be shown. In this example, some columns have unsupported data types:

Unsupported columns will not be replicated to Fabric. The list of current limitations can be found here. Keep in mind that only a maximum of 500 tables can be replicated.
After selecting the items to mirror, start the replication.
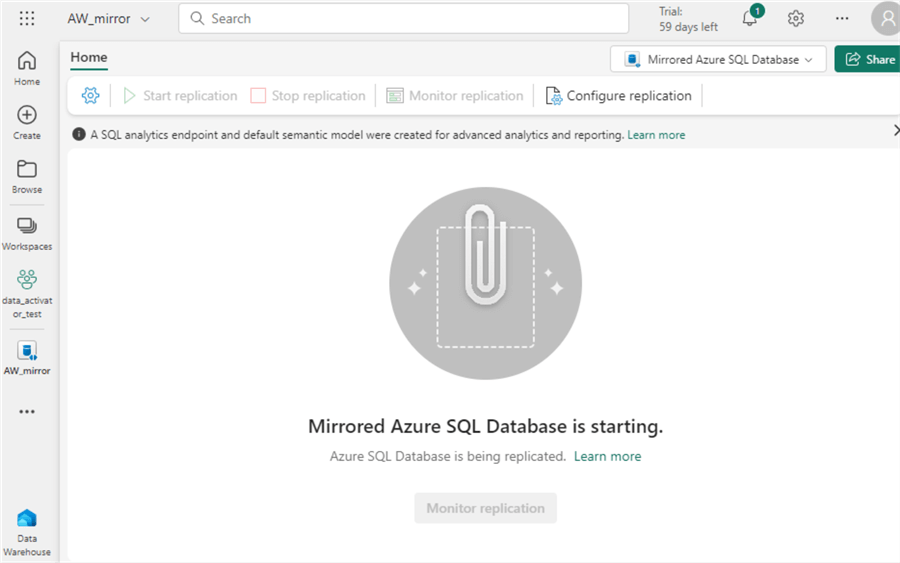
Once replication starts, you can monitor its status by clicking Monitoring replication. It might take a while for the initial snapshot to load.
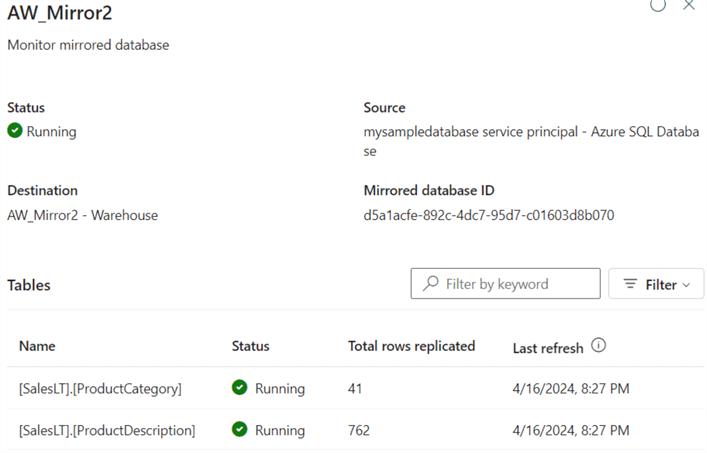
By default, Fabric has provisioned a semantic model and a SQL Analytics Endpoint for the mirrored database, just like in the lakehouse. With the SQL endpoint, you can query the replicated tables using T-SQL. You can switch to this endpoint by selecting it from the dropdown in the top right corner:
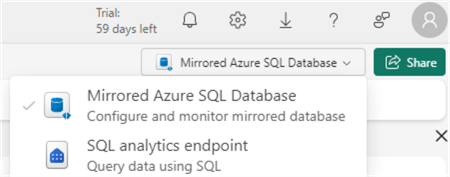
Another option is to select it from within the workspace:
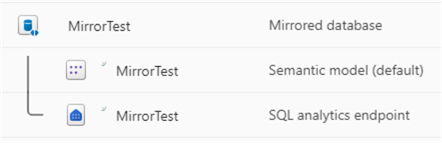
In the SQL endpoint, we can write read-only queries:
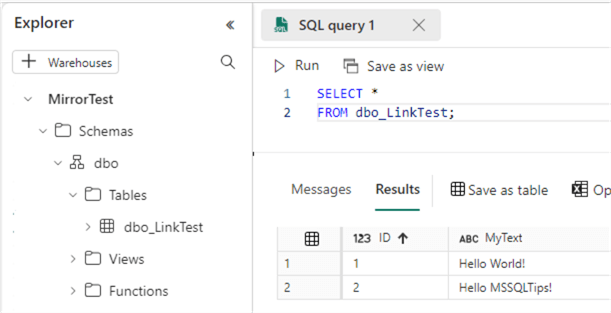
You also have the option to create views, table-valued functions, and stored procedures and manage permissions on the tables in the endpoint.
If data is added or changed in the source table, it should be replicated with low latency to the mirrored table.
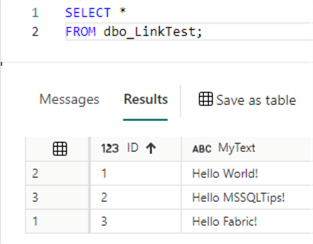
In the OneLake storage layer, you can see two folders are created: Files and Tables.
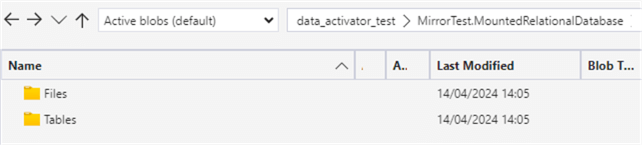
Data from the source database will first be copied to a landing zone in the Files section, where it is stored as Parquet files. Then, it will be copied to the Tables section as a delta table, where it will be optimized using V-Order and compaction (see Automatic Table Maintenance in Microsoft Fabric Warehouse part 1 and part 2 for more info).
Using the same menu as before, you can also stop the replication. When replication is stopped, the data is still available in OneLake. Restarting replication results in all tables being replicated from the start again.
If something goes wrong during replication, the following queries might be useful when troubleshooting:
SELECT * FROM sys.dm_change_feed_log_scan_sessions SELECT * FROM sys.dm_change_feed_errors; EXEC sp_help_change_feed;
If you want to completely remove mirroring from the source database, you can execute the following stored procedure:
EXEC sp_change_feed_disable_db;
Typically, stopping replication from the Fabric side should have the same effect.
Next Steps
- To learn more about the Azure Synapse Link feature, check out the following tips:
- More Microsoft Fabric tips can be found in this overview.
- Make sure to check the limitations of database mirroring in Fabric.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-05-29
