By: Jared Westover | Updated: 2024-06-19 | Comments (8) | Related: > Indexing
Problem
Have you ever needed to prevent duplicate rows from popping up in a table, but the built-in unique constraint in SQL Server falls short? I ran into a table with duplicate rows, but we couldn't delete them, at least for now. Ideally, you would delete all the duplicates and call it a day. If life were this simple, it would be boring. We needed to prevent new ones from showing up and keep the existing ones. The problem with a unique constraint is that it applies to all the rows in a column.
Solution
In this article, I'll share how a filtered index solved the problem of preventing duplicates for only new rows in a table. First, we'll look at why using a unique constraint doesn't work for our problem, even though there appears to be an option to not check existing rows. Then, you'll see how I used a filtered index to solve this problem. By the end of this article, you'll discover a new use for a little-known index that doesn't get the love it deserves.
Keeping a Column Unique
If you asked me how to keep a column unique that's not the primary key, for example, employee email, purchase order Id, or username, my first thought would be to add a unique constraint.
Microsoft defines a unique constraint as an object that ensures no duplicate values are entered in specific columns that don't participate in a primary key. To add a unique constraint to an existing table, use the code below.
-- mssqltips.com ALTER TABLE dbo.Duplicates ADD CONSTRAINT UX_SecondId UNIQUE (SecondId)
You can add multiple columns to a unique constraint, such as the combination of sales order and line item. For the most part, I've always used UX or UQ as the prefix in the name. I know naming conventions are essential to some people, but I'm good with them if you are consistent.
Demo Dataset
It's time to build a simple dataset for the rest of our demo. I'll use the code below to create a single table and a unique constraint on the email column.
-- mssqltips.com
DROP TABLE IF EXISTS dbo.Characters;
GO
CREATE TABLE dbo.Characters
(
Id INT,
Name VARCHAR(100),
Email VARCHAR(100),
CreatedDate DATETIME,
CONSTRAINT PK_Characters_Id PRIMARY KEY (Id),
CONSTRAINT UX_Characters_Email
UNIQUE (Email)
);
GO
INSERT INTO dbo.Characters (Id, Name, Email, CreatedDate)
VALUES
(1, 'Luke Skywalker', '[email protected]', SYSDATETIME()),
(2, 'Han Solo', '[email protected]', SYSDATETIME()),
(3, 'Chewbacca', '[email protected]', SYSDATETIME()),
(4, 'Owen Lars', '[email protected]', SYSDATETIME());
GO
After running the code above, check
sys.indexes and notice that
SQL Server adds a unique index behind the scenes.
-- mssqltips.com
SELECT t.name as TableName,
i.name AS IndexName,
i.index_id AS IndexId,
ColumnName = col.name
FROM sys.indexes i
INNER JOIN sys.index_columns ic
ON i.object_id = ic.object_id
and i.index_id = ic.index_id
INNER JOIN sys.columns col
ON ic.object_id = col.object_id
and ic.column_id = col.column_id
INNER JOIN sys.tables t
ON i.object_id = t.object_id
WHERE t.is_ms_shipped = 0
AND t.name = 'Characters';

Next, when I try to insert a duplicate email, SQL throws an error message. Since we added a unique constraint, I expected the error.
-- mssqltips.com
INSERT INTO dbo.Characters
(
Id,
Name,
Email,
CreatedDate
)
VALUES
(5, 'Owen Lars', '[email protected]', SYSDATETIME());
Results:
Violation of UNIQUE KEY constraint 'UX_Characters_Email'. Cannot insert duplicate key in object 'dbo.Characters'. The duplicate key value is ([email protected]).
Existing Duplicates
What if I have an existing table with duplicate rows? Let's run the code below to recreate our Characters table with a duplicate row already present.
-- mssqltips.com
DROP TABLE IF EXISTS dbo.Characters;
CREATE TABLE dbo.Characters
(
Id INT,
Name VARCHAR(100),
Email VARCHAR(100),
CreatedDate DATETIME,
CONSTRAINT PK_Characters_Id
PRIMARY KEY (Id),
);
GO
INSERT INTO dbo.Characters
(
Id,
Name,
Email,
CreatedDate
)
VALUES
(1, 'Luke Skywalker', '[email protected]', SYSDATETIME()),
(2, 'Han Solo', '[email protected]', SYSDATETIME()),
(3, 'Chewbacca', '[email protected]', SYSDATETIME()),
(4, 'Owen Lars', '[email protected]', SYSDATETIME()),
(5, 'Owen Lars', '[email protected]', SYSDATETIME());
GO
Since we have our table with existing data, let's alter it and try to add the constraint.
-- mssqltips.com
ALTER TABLE dbo.Characters
ADD CONSTRAINT UX_Characters_Email
UNIQUE (Email);
GO
Results:
The CREATE UNIQUE INDEX statement terminated because a duplicate key was found for the object name 'dbo.Characters' and the index name 'UX_Characters_Email'. The duplicate key value is ([email protected]).
As expected, SQL returns an error message saying we can't insert duplicate rows.
What about using the WITH NOCHECK
option? Doesn't it ignore data that already exists?
-- mssqltips.com
ALTER TABLE dbo.Characters WITH NOCHECK
ADD CONSTRAINT UX_Characters_Email
UNIQUE (Email);
GO
Results:
The CREATE UNIQUE INDEX statement terminated because a duplicate key was found for the object name 'dbo.Characters' and the index name 'UX_Characters_Email'. The duplicate key value is ([email protected]).
The answer is yes if it's part of a foreign key relationship and not a unique constraint. You run into the same problem if you add a unique constraint only to a Nullable column. In that instance, you can only have one NULL. To test this out, run the script below.
-- mssqltips.com
CREATE TABLE dbo.DuplicateTest
(
Id INT NOT NULL,
Id2 INT NULL,
CONSTRAINT UX_DuplicateTest_Id2
UNIQUE (id2)
);
GO
INSERT INTO dbo.DuplicateTest
(
Id,
Id2
)
VALUES
(1, NULL),
(2, NULL);
GO
Since we can't delete the duplicate rows in our table, what options do we have? I've outlined the options I considered in the following two sections.
Add a New Column
I toyed with adding a new column to deduplicate the existing rows. The code below shows what it looks like. The duplicate column defaults to 1 for any new records, thus enforcing the uniqueness for new rows. I also assume there's no funny business with someone changing the duplicate column values.
-- mssqltips.com
ALTER TABLE dbo.Characters
ADD Duplicate INT CONSTRAINT DF_Dupliate
DEFAULT 1;
GO
;WITH dups
AS (SELECT Id,
ROW_NUMBER() OVER (PARTITION BY Email ORDER BY Id) rn,
Duplicate
FROM dbo.Characters
)
UPDATE dups
SET Duplicate = rn;
GO
ALTER TABLE dbo.Characters
ADD CONSTRAINT UX_Characters_Email
UNIQUE
(
Email,
Duplicate
);
GO
SELECT * FROM dbo.Characters;
GO
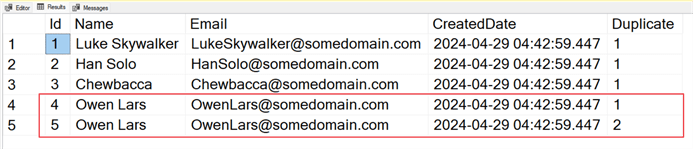
When you try and insert a new record for Owen Lars, SQL returns an error message.
INSERT INTO dbo.Characters
(
Id,
Name,
Email,
CreatedDate
)
VALUES
(6, 'Owen Lars', '[email protected]', SYSDATETIME());
GO
Results:
Violation of UNIQUE KEY constraint 'UX_Characters_Email'. Cannot insert duplicate key in object 'dbo.Characters'. The duplicate key value is ([email protected], 1).
The statement has been terminated.
Given the table size, I didn't want to add a new column. Plus, I wanted a temporary solution because we plan on deleting the duplicates, and adding a column feels permanent. However, I wouldn't hold it against someone using this method. Before moving on, let's drop the new column and unique constraint.
-- mssqltips.com ALTER TABLE dbo.Characters DROP CONSTRAINT UX_Characters_Email; GO ALTER TABLE dbo.Characters DROP CONSTRAINT DF_Dupliate; GO ALTER TABLE dbo.Characters DROP COLUMN Duplicate; GO
Adding a Filtered Index
An index (nonclustered) is a smaller copy of the data, smaller in that you ideally have fewer columns in a nonclustered index than your table or clustered. A filtered index allows you to take that one step further and exclude rows based on a WHERE clause. Filtered indexes are easy to add. For example, the code below creates a filtered index that excludes NULL rows.
-- mssqltips.com CREATE NONCLUSTERED INDEX IX_Filtered ON dbo.FilteredIndex (Name) WHERE Name IS NOT NULL;
Several restrictions apply to what you can include in your WHERE clause. Brent Ozar created an article outlining many of them, and Microsoft published a detailed list.
Below are a couple of use cases for filtered indexes. Both examples assume you're working with big tables, millions if not tens of millions of rows.
- Only include hot data based on a date range. Imagine having a table where your queries usually only return the current year's data. A filtered index can reduce the amount of data SQL reads.
- Sometimes, you don't want to delete a record permanently, so you introduce a soft delete process. You add a column indicating the row is marked for deletion. With a filtered index, you can filter out any soft deletes with a 1 (true) value.
I want to add a filtered index based on the maximum ID or CreateDate column for my use case. This data point lets me know when we introduced the new index. You could guess either of these values. However, I want to check the ID and create the index via dynamic SQL. The code below is an example of what will work.
-- mssqltips.com
DECLARE @maxId NVARCHAR(1000) = (
SELECT MAX(Id) FROM dbo.Characters
);
DECLARE @sql NVARCHAR(1000)
= CONCAT(N'CREATE UNIQUE NONCLUSTERED INDEX IX_Filtered_Dups
ON dbo.Characters (Name)
WHERE Id > ', @maxId);
EXECUTE (@sql);
GO

Now that we have our index in place, let's insert a duplicate record using the code below.
-- mssqltips.com
INSERT INTO dbo.Characters
(
Id,
Name,
Email,
CreatedDate
)
VALUES
(6, 'Owen Lars', '[email protected]', SYSDATETIME());
GO
Results:
What gives? Why were we able to insert another Owen Lars record? When you add the filter index, you draw a line in the sand based on the value of the filter predicate. Since the statement above sets the value to 5, SQL ignores anything before it. This means we can still get one extra record. However, if we try to insert another, what happens?
-- mssqltips.com
INSERT INTO dbo.Characters
(
Id,
Name,
Email,
CreatedDate
)
VALUES
(7, 'Owen Lars', '[email protected]', SYSDATETIME());
GO
Results:
Cannot insert duplicate key row in object 'dbo.Characters' with unique index 'IX_Filtered_Dups'. The duplicate key value is (Owen Lars).
The statement has been terminated.
This was a win for us. We worked around the drawback of one more duplicate. If you can't live with it, look at the other option. We kept the duplicate records but couldn't insert any new ones. In this situation, the filtered index is a band-aid. We plan to delete them later once certain things are sorted out.
Finally, let's run the scripts below to clean up after ourselves.
DROP TABLE IF EXISTS dbo.DuplicateTest; DROP TABLE IF EXISTS dbo.Characters; GO
Key Points
- Filtered indexes help limit the number of rows in an index. Yet, sometimes, getting SQL Server to use them is tricky. As with unfiltered indexes, make sure to cover your queries adequately.
- I recommend using filtered indexes on large tables; by large, I mean million-plus rows. Also, the green hint on your actual execution plan never recommends adding one.
- Consider constraints as tools in SQL Server to enforce data integrity, while indexes exist to improve performance. I advise against using an index to enforce integrity in almost every situation, but life sometimes gets in the way.
Next Steps
- Do you find that SQL Server ignores your filtered indexes? Check out the article, Overlooked Reason SQL Server Ignores Your Filtered Indexes, to learn more.
- Looking for another reason why your filtered index is being ignored? I wrote the article, Evaluating SQL Server Filtered Indexes in a Multi Table SQL Join, exploring this topic in depth.
- Sergey Gigoyan outlined the differences between a unique constraint and a unique index in the article, Difference between SQL Server Unique Indexes and Unique Constraints.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-06-19
