By: Jared Westover | Updated: 2024-06-26 | Comments | Related: > Indexing
Problem
You add indexes to speed up queries, but what about deleting data? Has someone told you that indexes slow down deletes? The rationale is that the more copies of the data exist via indexes, the more data SQL Server must remove when cleaning up. But does this claim hold up when testing?
Solution
In this article, we'll examine the importance of indexes in improving DELETE statements. Also, many developers assume that adding a foreign key creates an index, which means they're typically missing. How can you identify which foreign keys are missing indexes? Don't worry. A handy DMV helps find them. Starting today, you'll have the skills to make your DELETE statements faster.
Deleting Data
Over the years, I've come to value the mindset of creating a table with the certainty of deleting data. When you build a fresh new table, it's easy to forget at some point; you'll need to delete records. Your company may have a record retention policy in place. For example, you only keep client data for 10 years. At that point, you must purge it from the system or face the wrath of your legal team. Also, end users will likely delete data from the application by clicking a button. No matter the reason for deleting, you want your DELETE statements to perform optimally, just like SELECT statements.
What's the most common way to improve the lookup performance of SELECT statements? But all things being equal, adding proper indexes.
Adding Indexes
You've likely heard that adding a non-clustered index to a table forces SQL to delete the index's data. The same idea applies to updates and inserts. It's true. Since an index is a copy of the table, ideally with fewer columns, SQL cleans up the index when deleting data from the base table or clustered index if the column lives in the index. Yet, similar to how non-clustered indexes make SELECT statements faster, they can make deleting data faster.
Demo Dataset
Let's build a dataset to demonstrate the effect indexes have on deleting data. Using the script below, I'll create three tables:
- Table1 contains 1,000 rows.
- Table2 contains 10,000 rows.
- Table3 contains 10,000,000 rows.
Notice I'm adding foreign key relationships between each table. The script below takes about 20 seconds to run on my server.
-- mssqltips.com
USE master;
IF DATABASEPROPERTYEX('DeleteDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE DeleteDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE DeleteDemo;
END;
GO
CREATE DATABASE DeleteDemo
ALTER DATABASE DeleteDemo SET RECOVERY SIMPLE;
GO
USE DeleteDemo;
GO
CREATE TABLE dbo.Table1 (
Id INT IDENTITY(1, 1),
String1 VARCHAR(200),
CONSTRAINT PK_Table1_Id
PRIMARY KEY CLUSTERED (Id));
CREATE TABLE dbo.Table2 (
Id INT IDENTITY(1, 1),
Id2 INT NOT NULL,
CONSTRAINT PK_Table2_Id
PRIMARY KEY CLUSTERED (Id),
CONSTRAINT FK_Table1_Id2
FOREIGN KEY (Id2)
REFERENCES dbo.Table1 (Id));
CREATE TABLE dbo.Table3 (
Id INT IDENTITY(1, 1),
Id3 INT NOT NULL
CONSTRAINT PK_Table3_Id
PRIMARY KEY CLUSTERED (Id),
CONSTRAINT FK_Table3_Id3
FOREIGN KEY (Id3)
REFERENCES dbo.Table2 (Id));
GO
;WITH cteN (Number)
AS (SELECT TOP 1000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2)
INSERT INTO dbo.Table1 (String1)
SELECT TOP 1000 SUBSTRING(
REPLICATE('abcdefghijklmnopqrstuvwxyz', 4),
(ABS(CHECKSUM(NEWID())) % 26) + 1,
(ABS(CHECKSUM(NEWID()) % (90 - 50 + 1)) + 50)) AS SomeString
FROM cteN n;
;WITH cteN (Number)
AS (SELECT TOP 10000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2)
INSERT INTO dbo.Table2 (Id2)
SELECT (ABS(CHECKSUM(NEWID()) % (1000 - 1 + 1)) + 1) AS Id2
FROM cteN n;
;WITH cteN (Number)
AS (SELECT TOP 10000000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2)
INSERT INTO dbo.Table3 (Id3)
SELECT (ABS(CHECKSUM(NEWID()) % (10000 - 1 + 1)) + 1) AS Id2
FROM cteN n;
GO
Foreign Keys
Foreign keys help ensure the database's referential integrity. If you're new to SQL Server, you might assume SQL creates a non-clustered index when you add a foreign key relationship. I've got some bad news: SQL does not. We created two foreign key relationships above and can run the script below to check which indexes exist for our tables.
-- mssqltips.com
SELECT DB_NAME(DATABASE_ID) AS DATABASENAME,
SCHEMA_NAME(C.SCHEMA_id) AS SCHEMANAME,
OBJECT_NAME(B.OBJECT_ID) AS TABLENAME,
INDEX_NAME = ( SELECT NAME
FROM SYS.INDEXES A
WHERE A.OBJECT_ID = B.OBJECT_ID
AND A.INDEX_ID = B.INDEX_ID)
FROM SYS.DM_DB_INDEX_USAGE_STATS B
INNER JOIN SYS.OBJECTS C
ON B.OBJECT_ID = C.OBJECT_ID
WHERE DATABASE_ID = DB_ID(DB_NAME())
AND C.TYPE = 'U';

The demo database contains zero non-clustered indexes for Table2 and Table3.
Deleting Without Indexes
Now, it's time to delete some data. We'll start with zero non-clustered indexes on the foreign keys. After looking at a few performance markers, we'll roll back the transaction to prevent rebuilding our dataset. Also, I'll turn on my actual execution plan.
-- mssqltips.com
BEGIN TRANSACTION;
DELETE t3
FROM dbo.Table3 t3
INNER JOIN dbo.Table2 t2
ON t2.Id = t3.Id3
WHERE t2.Id2 = 101;
DELETE t2
FROM dbo.Table2 t2
WHERE Id2 = 101;
DELETE t1
FROM dbo.Table1 t1
WHERE t1.Id = 101;
We could look at the messages tab and add up the elapsed and CPU times, but I'll look at the QueryTimeStats under each of the three execution plans.
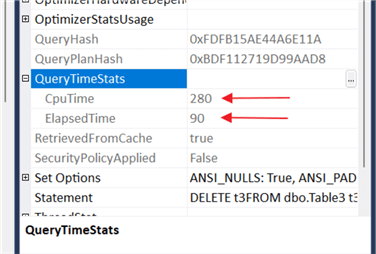
The table below represents the CPU and elapsed time from each execution plan.
| Table | CPU (ms) | Elapsed (ms) | Records Deleted |
|---|---|---|---|
| Table3 | 280 | 90 | 9075 |
| Table2 | 2044 | 2044 | 9 |
| Table1 | 2 | 2 | 1 |
| Total | 2326 | 2136 | 9085 |
The higher CPU times for Table3 indicate that the plan went parallel with a cost of about 20. The cost threshold on my server is set to 10, and MAX DOP is set to 4.
Locking
Allow me to highlight something else. If I run Adam Machanic's sp_whoisactive in another session with the get_locks parameter turned on, we take an exclusive lock on Table3. When you delete ~5000 rows in SQL Server, SQL issues an exclusive lock on the table or object. Also, the request_count=1 is a good indicator.
EXECUTE sp_whoisactive @get_locks = 1;

SQL holds the exclusive lock until the transaction finishes. Imagine if we performed multiple statements after the deletes; the exclusive lock remains. Depending on your isolation level and if you enable READ_COMMITTED_SNAPSHOT, even reads might be blocked the entire time.
Run the code below to roll back the transaction to avoid recreating the entire dataset.
-- mssqltips.com ROLLBACK TRANSACTION;
Deleting With Indexes
Let's add two non-clustered indexes on Table2 and Table3 with the code below.
-- mssqltips.com CREATE NONCLUSTERED INDEX IX_Table2_Id2 ON dbo.Table2 (Id2); CREATE NONCLUSTERED INDEX IX_Table3_Id3 ON dbo.Table3 (Id3); GO
With our indexes in place, let's execute the original DELETE statements without committing the transaction.
-- mssqltips.com
BEGIN TRANSACTION;
DELETE t3
FROM dbo.Table3 t3
INNER JOIN dbo.Table2 t2
ON t2.Id = t3.Id3
WHERE t2.Id2 = 101;
DELETE t2
FROM dbo.Table2 t2
WHERE Id2 = 101;
DELETE t1
FROM dbo.Table1 t1
WHERE t1.Id = 101;
Below are the captured execution times.
| Table | CPU (ms) | Elapsed (ms) | Records Deleted |
|---|---|---|---|
| Table3 | 31 | 33 | 9075 |
| Table2 | 0 | 0 | 9 |
| Table1 | 2 | 2 | 1 |
| Total | 32 | 32 | 9085 |
Even with added indexes, SQL takes an exclusive lock on Table3. Yet, it's held for a fraction of the time. The statements went from 2136ms to 32ms, a massive difference in my book. The indexes' benefits for looking up data outweighed the cost of removing records from them.
In this article, I'm not saying you should add the maximum number of indexes and expect deletes to be faster. Indexes cost when it comes to deleting data. In this instance, the lookup benefits outweighed the cost.
Clean Up
Since we're done, let's roll back the transaction and then drop the database.
-- mssqltips.com
ROLLBACK TRANSACTION;
GO
USE master;
IF DATABASEPROPERTYEX('DeleteDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE DeleteDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE DeleteDemo;
END;
GO
Key Points
- When you add a foreign key, SQL doesn't automatically create a non-clustered index. To find all foreign keys without an index, check out Eli Leiba's article, Script to identify all non-indexed foreign keys in a SQL Server database.
- The longer transactions take, the longer SQL holds the locks. Strive to make transactions tiny. Also, consider whether you need all those SELECT statements at the end.
- When updating or deleting 5,000 or more rows, SQL issues an exclusive lock on the object. Since reads won't require a shared lock, you can lessen the impact on other sessions using READ_COMMITED_SNAPSHOT.
Next Steps
- One of the tools I used in this article was Adam Machanic's sp_whoisactive. If you're interested in learning how to collect the data results, Jeffrey Yao wrote SP_WhoIsActive Data Collection and Analysis to get you started.
- Do you have a big table with lots of rows to delete and want to reduce the impact on a production server? Aaron Bertrand's article, Fastest way to Delete Large Number of Records in SQL Server, will put you on the right path.
- Are you thinking about enabling READ_COMMITED_SNAPSHOT but need some more answers? Check out READ_COMMITTED_SNAPSHOT and SNAPSHOT_ISOLATION levels in SQL Server by Sergey Gigoyan to learn more.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-06-26
