By: Jared Westover | Updated: 2024-07-31 | Comments (6) | Related: > Performance Tuning
Problem
Often, developers use local variables when writing ad hoc queries or stored procedures for many reasons. You might hear "never repeat code" or "avoid using magic numbers." While writing a lengthy stored procedure, I might include a few. However, did you know that local variables can hurt the performance of your queries? How can you keep local variables from negatively affecting performance? Keep reading to find those answers and more.
Solution
In this article, I'll examine the effect of local variables on your T-SQL queries. The primary questions I'll answer are: what's causing the performance issue, and how can you tell it's happening? We'll also examine a few ways to work around it. By the end of this article, you'll better understand how local variables affect your queries' performance. Share this article the next time someone notices a performance problem with local variables and is left scratching their head.
Exploring Local Variables
If you've been in the SQL game for any time, I'm sure you've
used a variable.
Microsoft defines a variable as an object that can hold a specific data value
of a specific type. The code below declares a variable and populates it with a string
value. The SELECT statement
then returns the value.
-- mssqltips.com DECLARE @message VARCHAR(100) = 'Hello! World'; SELECT @message; -- Using SET to declare the variable DECLARE @message2 NVARCHAR(100) SET @message2 = 'Hello World!' SELECT @message2;
Results:
---------------- Hello! World (1 row affected) ---------------- Hello World! (1 row affected)
Unlike a temporary table, a variable only exists until the batch completes. If you use a GO command, the variable vanishes. The code below returns an error stating the variable doesn't exist, plus the second reference to the variable has a red squiggly line, which is never a good sign of things to come.
-- mssqltips.com DECLARE @message NVARCHAR(100) = 'Hello! World'; SELECT @message; GO SELECT @message;
Results:
Msg 137, Level 15, State 2, Line 7 Must declare the scalar variable "@message".
Also, a variable can exist inside and outside a BEGIN/END block. For example, when executing the code below, the second statement still returns the value.
-- mssqltips.com BEGIN DECLARE @varMessage NVARCHAR(100) = 'Hello! World'; SELECT @varMessage; END SELECT @varMessage;
I add a variable in a stored procedure or ad hoc query when calling the
GETDATE() function. Instead
of calling GETDATE() multiple
times in the query body, I'll declare it once and then use the variable. One
reason to do this is so the date and time are consistent.
-- mssqltips.com
DECLARE @varDemoTable TABLE (Id INT, CreatedDate DATETIME);
DECLARE @varCurrentDate DATETIME = GETDATE();
INSERT INTO @varDemoTable (Id, CreatedDate)
VALUES
(1, @varCurrentDate),
(2, @varCurrentDate),
(3, @varCurrentDate);
SELECT Id,
CreatedDate
FROM @varDemoTable;
Results:
Id CreatedDate ----------- ----------------------- 1 2024-06-21 03:18:29.980 2 2024-06-21 03:18:29.980 3 2024-06-21 03:18:29.980
The Downside
It's common for developers to use variables instead of literal values in
a WHERE clause. Overall,
this practice is a great idea. You start by declaring the variable and then populate
it towards the top of the query. This method is handy if you reference the variable
multiple times and if you populate the variable based on a row value.
-- mssqltips.com
DECLARE @colors TABLE
(
Id INT,
Name VARCHAR(20)
);
INSERT INTO @colors
(
Id,
Name
)
VALUES
(1, 'Red'),
(2, 'Blue'),
(3, 'Green')
DECLARE @color VARCHAR(20) = (SELECT 'Blue')
SELECT Id
FROM @colors
WHERE Name = @color;
GO
Results:
Id --- 2
However, as we'll see in the following sections, this practice can cause performance problems. Now, I'll say upfront that the downside is related to a specific pattern and shouldn't cause anyone to write out the utility of variables.
Demo Dataset
To illustrate the negative impact of variables, we need to build a larger dataset. The code below creates a database called LocalVariablesDemo, along with two tables. The first numbers table populates the Colors table.
-- mssqltips.com
USE master;
IF DATABASEPROPERTYEX('LocalVariablesDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE LocalVariablesDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE LocalVariablesDemo;
END;
GO
CREATE DATABASE LocalVariablesDemo;
ALTER DATABASE LocalVariablesDemo SET RECOVERY SIMPLE;
GO
USE LocalVariablesDemo;
GO
DECLARE @upperBound INT = 5000000;
;WITH cteN (Number)
AS (SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number]
INTO dbo.Numbers
FROM cteN
WHERE [Number] <= @UpperBound;
GO
CREATE TABLE dbo.Colors
(
Id INT IDENTITY(1, 1),
FavoriteColor VARCHAR(200) NOT NULL,
SomeRandomNumber DECIMAL(10, 2) NOT NULL,
Person VARCHAR(10) NOT NULL,
IsActive BIT NOT NULL
CONSTRAINT PK_ColorValue
PRIMARY KEY CLUSTERED (Id)
)
INSERT INTO dbo.Colors
(
FavoriteColor,
Person,
SomeRandomNumber,
IsActive
)
SELECT CASE
WHEN n.Number % 2 = 0 THEN
'Green'
WHEN n.Number % 1 = 0 THEN
'Blue'
END AS FavoriteColor,
CASE
WHEN n.Number % 2 = 0 THEN
'Henry'
WHEN n.Number % 1 = 0 THEN
'Liam'
END AS Person,
(ABS(CHECKSUM(NEWID()) % (100 - 1 + 1)) + 1) AS SomeRandomNumber,
CASE
WHEN n.Number % 100000 = 0 THEN
0
ELSE
1
END AS IsActive
FROM dbo.Numbers n;
CREATE NONCLUSTERED INDEX IX_IsActive
ON dbo.Colors (IsActive)
INCLUDE
(
SomeRandomNumber,
Person
);
GO
SELECT COUNT(1) AS ColorCount,
FavoriteColor,
Person,
IsActive
FROM dbo.Colors
GROUP BY FavoriteColor,
Person,
IsActive;
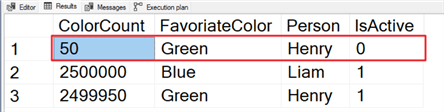
Let's look at the spread of data in our table. Notice in the screenshot below that we only have 50 records where IsActive equals 0. Large skews toward specific values are when things fall apart.
Now, let's run the query below without using a local variable and with the actual execution plan enabled.
-- mssqltips.com
SELECT COUNT(1) AS ColorCount,
Person,
FavoriteColor
FROM dbo.Colors
WHERE IsActive = 0
GROUP BY FavoriteColor,
Person;
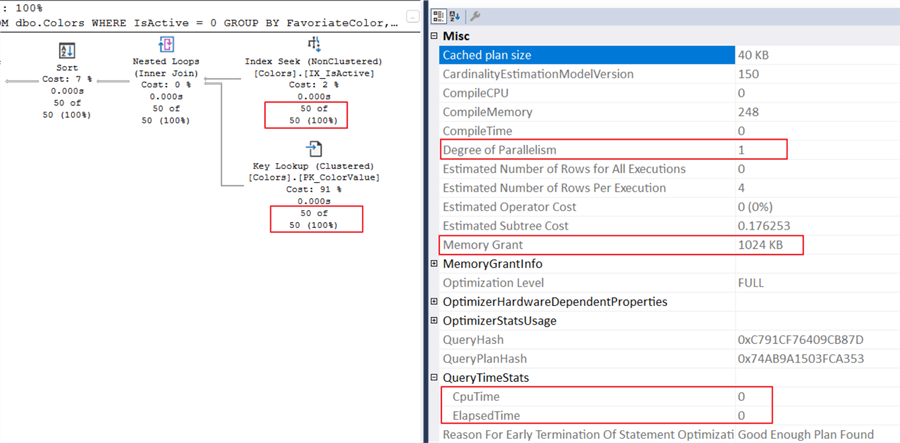
Given the query and indexes, I anticipated the plan above. Below are three points to highlight:
- SQL estimates 50 rows, which matches the actual count.
- SQL performs a standard small memory grant. I set the minimum memory per query to 1024KB.
- The query takes no time at all, according to the QueryTimeStats.
It's time for things to get interesting. I'll rerun the query, but this time with a local variable.
-- mssqltips.com
DECLARE @inactive BIT = 0
SELECT COUNT(1),
Person,
FavoriteColor
FROM dbo.Colors
WHERE IsActive = @inactive
GROUP BY FavoriteColor,
Person;
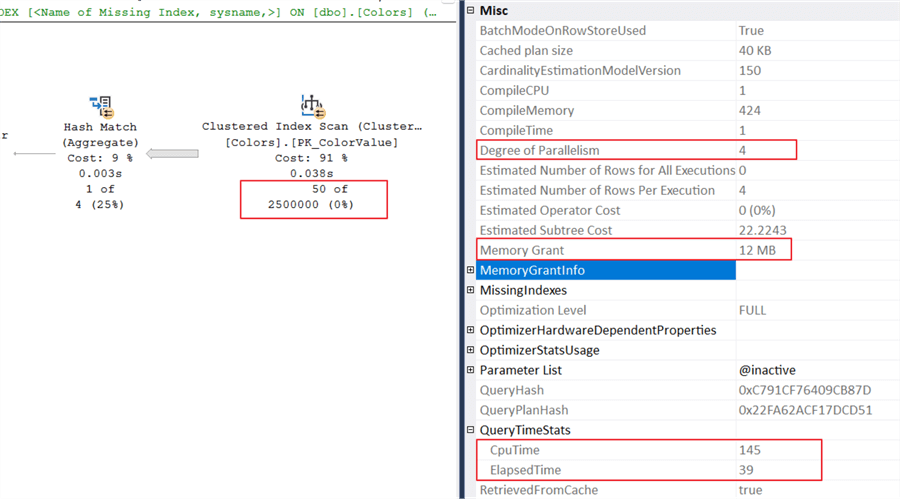
Several new things are happening in the plan:
- SQL estimates there are 2.5 million rows where IsActive equals 0.
- The CPU and elapsed time increased.
- The memory grant is 12MB versus 1024KB as in the first execution.
- Finally, the cost increased and caused parallelism. I set the cost threshold for parallelism to 20 on this server.
Why does SQL estimate 2.5 million rows when we use a local variable? It's simple. SQL doesn't know the variable's value when compiling the execution plan. So, it guesses. You can figure out the guess by looking at the statistics. Run the statement below.
-- mssqltips.com
DBCC SHOW_STATISTICS ('dbo.Colors', 'IX_IsActive');
GO
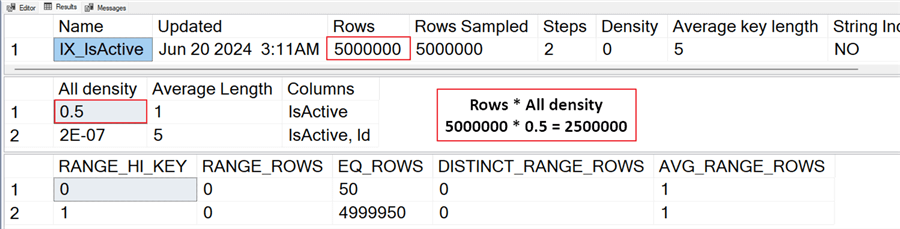
From the screenshot above, SQL takes the total rows multiplied by all density, which turns out to be 2.5 million. Using this sort of guess falls apart when the data in your table is skewed to one value, as in our example of only 50 out of 5 million records. Also, updating statistics will not fix this issue. If you don't believe me, run the command below to update all statistics on the Colors table. After updating stats, run the query with the local variable, and you'll notice no difference.
-- mssqltips.com UPDATE STATISTICS dbo.Colors; GO
Workarounds
If local variables cause you problems, a few solutions exist. The first is to skip using local variables. You may not have that option, but it would be the easiest way to avoid falling victim. It's like the old joke about a person going to the doctor and saying it hurts when I do this, and the doctor says then don't do that.
OPTION (RECOMPILE)
The second option is to recompile the execution plan each time the statement executes. Placing the option at the end of the statement only recompiles the single statement. For example, if you run 10 or 15 different statements in a query or stored procedure, you might only need this option performed for one of them.
-- mssqltips.com
DECLARE @inactive BIT = 0;
SELECT COUNT(1),
Person,
FavoriteColor
FROM dbo.Colors
WHERE IsActive = @inactive
GROUP BY FavoriteColor,
Person
OPTION (RECOMPILE);
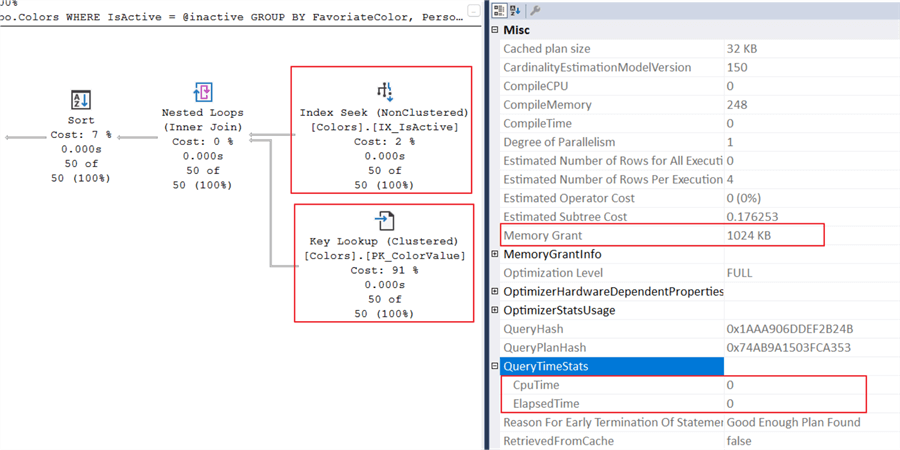
The plan looks much better now. From the screenshot above, SQL returns an accurate estimate of 50 rows. What else can you try?
Dynamic SQL
Another option worth mentioning is dynamic SQL. However, I find this option more trouble than it's worth. The code is difficult to write and maintain. Maybe you've had a better experience. The example below provides an accurate estimate of the IsActive column distribution using the system stored procedure sp_executesql.
-- mssqltips.com
DECLARE @inputVariable BIT = 0;
DECLARE @sqlStatement NVARCHAR(500) = N'';
DECLARE @parmDefinition NVARCHAR(500) = N'';
SET @sqlStatement
= N'SELECT COUNT(1),
Person,
FavoriteColor
FROM dbo.Colors
WHERE IsActive = @isActive
GROUP BY FavoriteColor,
Person';
SET @parmDefinition = N'@isActive BIT';
EXEC sys.sp_executesql @sqlStatement,
@parmDefinition,
@isActive = @inputVariable;
GO
However, when you change the input variable to 1, we fall victim to parameter sniffing. That's about as bad as the inaccurate statistics.
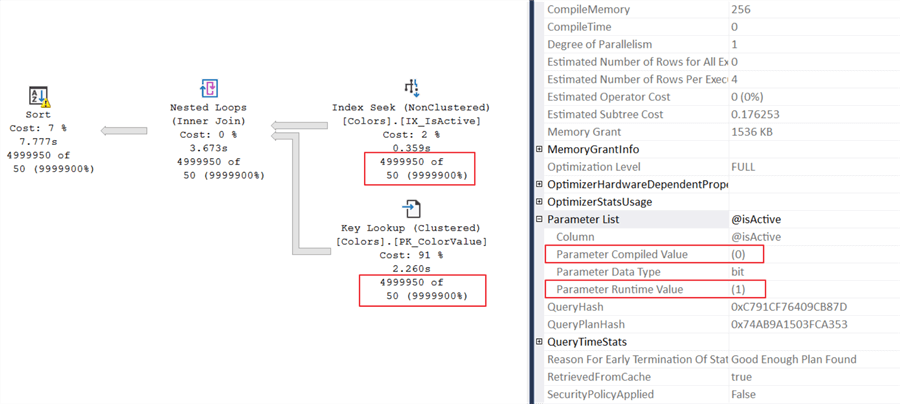
Parameter sniffing is another reason I prefer the recompile option in situations like this.
Clean Up
Don't forget to run the script below to drop the demo database.
-- mssqltips.com
USE master;
IF DATABASEPROPERTYEX('LocalVariablesDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE LocalVariablesDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE LocalVariablesDemo;
END;
GO
Wrapping Up
More options exist than the two outlined above. Erik Darling wrote an article titled "Yet Another Post About Local Variables In SQL Server," which covers a few more, and I highly recommend you check it out. I don't suggest avoiding local variables because of this issue since it's specific to skewed data distribution unless all your data is skewed, then I would avoid them. But it's nice to know you have options when it shows up in your environment. I prefer the recompile option or removing variables since the code changes are minimal and easy to maintain.
Key Points
- Local variables are a great way to eliminate redundancy in code. For example, create a local variable with the date and time and assign it to one at the beginning of your script.
- As with everything great in SQL Server, there tends to be a downside. Local variables are no different, but the above workarounds should help resolve the issue.
- Try the other options and see if they work better than a recompile. Let us know in the comments if you have a better method.
Next Steps
- Would you like to learn more about writing dynamic SQL? Greg Robidoux wrote the article "Execute Dynamic SQL commands in SQL Server" to get you started.
- For a comprehensive overview of statistics, check out Erin Stellato's presentation on the CSharp YouTube channel "Understanding Statistics in SQL Server."
- If you're looking for a comprehensive overview of parameter sniffing and the various recompile options, check out Paul White's article "Parameter Sniffing, Embedding, and the RECOMPILE Options."






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-07-31
