By: Temidayo Omoniyi | Updated: 2024-08-08 | Comments (1) | Related: > Python
Problem
We are in an era of fast-moving information, where decisions need to be made in seconds. To make end user information available this quickly is made possible by robust underlying pipeline designs that do all necessary ETL processes at the expected time and need.
Solution
A solution that helps data engineers perform the ETL process at a set time without the need for human interference is in high demand.
In this article, I will walk through how to automate an ETL pipeline in a Python script with a batch file on a Windows server.
Project Overview
As a data engineer, you have been tasked to move data from SQL Server to Azure Data Lake Gen 2, which will serve as your staging area. Then, you are expected to pick the latest file in the Azure Data Lake Gen 2 to perform the expected transformation and load it into an Azure SQL Database.
This process is expected to repeat daily, meaning data will be loaded to the SQL Server database incrementally. You will need to pick the new data inserted into the SQL Server database table, load it into Azure Data Lake Gen 2 as a new file, and perform the necessary transformation to Azure SQL Database.
Project Architecture
The project will be broken into five sections, each section aimed at achieving a significant goal:
- Section 1: Provision necessary resources such as Azure Data Lake Gen 2 and Azure Database SQL using Azure CLI.
- Section 2: Installation and write script to perform full load movement from SQL Server to Data Lake Gen 2 and Azure SQL Database.
- Section 3: Configure and get the necessary credentials for Azure Storage Account.
- Section 4: Write incremental script for both SQL Server to Azure Data Lake Gen 2 and Azure SQL Database.
- Section 5: Write a batch file to run both Python scripts based on the success of the first script. We will create a workflow in a batch file, and the file will be triggered daily using Task Scheduler.
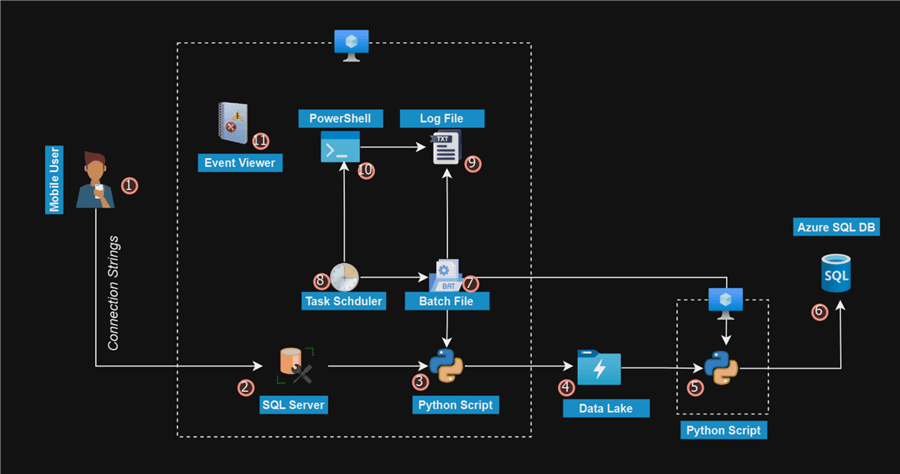
Project Architecture
Prerequisites
- Install Python IDLE (Integrated Development and Learning Environment) or Anaconda on Windows Server.
- Install the latest version of Azure CLI on Windows Server.
- Install SQL Server on Virtual Machine.
- Basic Python programming and SQL skills.
- Pip installs the necessary libraries:
- pandas
- azure-identity
- azure-storage-file-datalake
- sqlalchemy
- pyodbc
- python-dotenv
- Be open-minded, and let's build together.
Section 1: Provision Necessary Resources
What is Microsoft Azure CLI?
The Azure CLI, or Azure Command-Line Interface, is a cross-platform solution for managing Azure resources and services on Windows, MacOS, and Linux.
For this article, we will use Azure CLI to provision the necessary resources in Azure.
Provision Azure Data Lake Gen 2 using Azure CLI
Follow these steps to achieve this process:
Step 1: Log in to Azure
Open Azure CLI in your Windows server environment. Write the command below to log in to your Azure environment.
az login

The command will open your Windows browser. Select your Azure account.
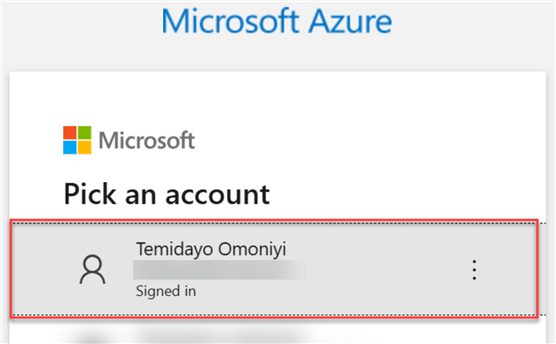
You should get a successful message if the authentication process works as expected.
Step 2: Select Subscription
In your Azure CLI, when multiple subscriptions are associated to a particular account, you need to select the subscription you want to use to perform this process.
To get your subscription ID, log into your Azure Portal and select the Subscription. You will see your Subscription ID in the Overview.
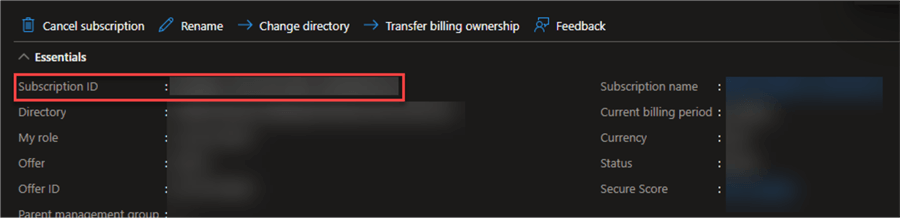
Write the following shell script in your Azure CLI on your Windows server. Ensure you put in your Subscription ID from the Azure Portal.
az account set --subscription "YourSubscriptionId"

Step 3: Create Resource Group (Optional)
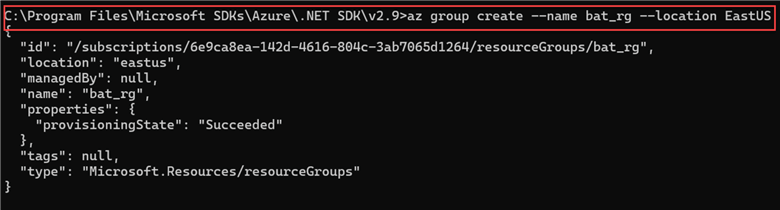
This step is optional. However, to organize the entire resource, I will use a single resource group. The Azure resource group is a container that helps organize and manage your related Azure resources. It functions similarly to a cloud folder for your digital assets.
az group create --name YourResourceGroupName --location YourLocation
Step 4: Create an Azure Storage Account
In your Azure CLI terminal, we will create an Azure Data Lake Gen 2 storage account in the same resource group created earlier. Use the shell script below to achieve this.
az storage account create --name YourStorageAccountName --resource-group YourResourceGroupName --location YourLocation --sku Standard_LRS --kind StorageV2 --hierarchical-namespace true
Step 5: Create a File System in Data Lake Gen 2
The file system in the Azure storage account is analogous to a container. To manage and arrange your data, think of it as a high-level organizational structure inside a storage account.
az storage fs create --name YourFileSystemName --account-name YourStorageAccountName
Provision Azure SQL Database using Azure CLI
We will follow the same approach we used to create the Azure Storage account for the Azure SQL Database.
Step 1: Create Server
With the shell script, we will first create a server for the SQL Database in the same resource group created earlier.
az sql server create --name YourSqlServerName --resource-group YourResourceGroupName --location YourLocation --admin-user YourAdminUsername --admin-password YourAdminPassword

Step 2: Create SQL Database
After successfully creating the SQL Server, let's create the Azure SQL Database with the following shell script.
az sql db create --resource-group YourResourceGroupName --server YourSqlServerName --name YourDatabaseName --service-objective S0
Step 3: Allow Other Azure Resource Access SQL Server (Optional)
To allow other Azure services to access your Azure SQL server, you need to configure the firewall with the following shell script. You can also activate this process from the Azure Portal using the GUI.
az sql server firewall-rule create --resource-group YourResourceGroupName --server YourSqlServerName --name AllowAzureIPs --start-ip-address 0.0.0.0 --end-ip-address 0.0.0.0
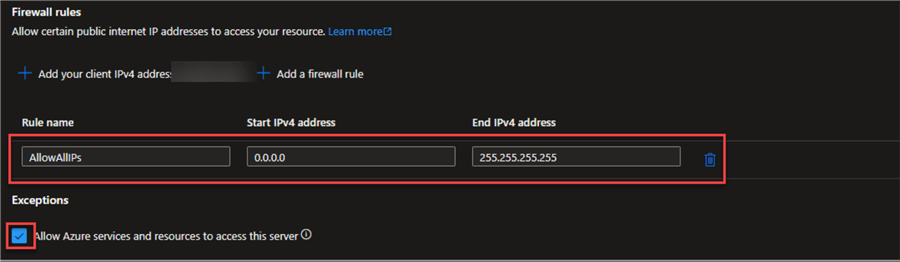
Step 4: Allow All IP Addresses to Access SQL Server (Not Recommended)
You can allow all IP address access to your SQL Server if you do not want to manually set the IP in your SQL Server security network.
Note: Because of security considerations, it is not advised to open access to all IP addresses in production situations. Restricting access to established and reliable IP addresses is a good idea. Think about adding restricted IP addresses or ranges for production, such as the public IP addresses of your company or a particular Azure virtual network. This example is just for educational purposes.
# Allow all IP addresses to access the SQL server (not recommended for production) az sql server firewall-rule create --resource-group $RESOURCE_GROUP_NAME --server $SQL_SERVER_NAME \ --name AllowAllIPs --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Login to your Azure Portal firewall to confirm that all the configurations are set as expected.
Section 2: Set Service Principal in Azure Active Directory
Using the Azure CLI, we can create a service principle that will have access to the Azure Data Lake Gen and retrieve the necessary credentials such as Client ID, Tenant ID, and Client Secret.
The shell script below will help generate the following credentials. Ensure you keep all information in a well-secure location.
az ad sp create-for-rbac --name "YourServicePrincipalName" --role "Contributor" --scopes /subscriptions/YourSubscriptionId/resourceGroups/YourResourceGroupName

Set Permission
After getting the necessary credentials, we need to set the following permission to the app created to have access to the Azure Storage.
For the service principal app, we need to assist the Storage Blob Data Contributor role. This will grant the necessary permissions to read, write, and delete blob data within Azure storage.
# Assign the Storage Blob Data Contributor role to the service principal az role assignment create --assignee <client-id> --role "Storage Blob Data Contributor" --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Storage/storageAccounts/<account-name>"
Section 3: Perform Full Load Operation for the Different Storage
Full Load from SQL Server On-premises to Azure Storage Account ADLS
Step 1: Import All Necessary Libraries
We need to import all the necessary libraries to be used for this project.
import pandas as pd from sqlalchemy import create_engine from azure.identity import ClientSecretCredential from azure.storage.filedatalake import DataLakeServiceClient import os import io from dotenv import load_dotenv, dotenv_values
Step 2: Set SQL Server On-premises Credentials and Security
To make our script more secure, we do not want to write blank code before pushing it to production. We will be using the dotenv library to achieve this process.
# Specify the directory where your .env file is located
env_dir = r'C:\Users\xxxxxxx\xxxxxxxxxxx\Production Full Load' #This is to specify where the env file is saved upon.
# Load environment variables from .env file in the specified directory
env_values = dotenv_values(os.path.join(env_dir, '.env'))
# SQL Server connection details
server = env_values.get("server")
database = env_values.get("database")
username = env_values.get("username")
password = env_values.get("password")
driver = 'ODBC Driver 17 for SQL Server'
Step 3: Connect to SQL Server
Create a connection string to be used to connect to SQL Server on your Windows server.
# Create a SQLAlchemy engine for SQL Server
connection_string = f"mssql+pyodbc://{username}:{password}@{server}/{database}?driver={driver}"
engine = create_engine(connection_string)
After successfully connecting, you can check to see if the data reads as expected.
# SQL query to read data query = "SELECT * FROM dbo.salesfull" # Read data from SQL Server into a panda DataFrame df = pd.read_sql(query, engine) df.info()
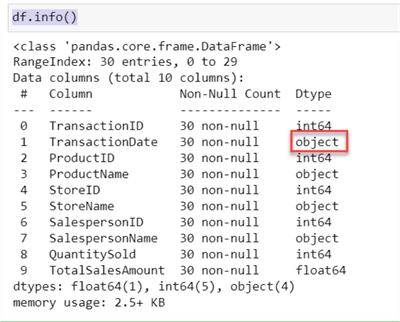
Perform the necessary transformation on the TransactionDate column to datetime and save the file in memory as CSV.
# Convert the 'Date' column from object to datetime df['TransactionDate'] = pd.to_datetime(df['TransactionDate']) # Save DataFrame as a CSV file in memory csv_buffer = io.StringIO() df.to_csv(csv_buffer, index=False)
Step 4: Connect to Azure Storage Account
Now, we need to connect to the Azure Storage account with the following credentials set up above.
#Upload CSV file to Azure Data Lake Gen2
# Azure Data Lake Details
account_name = env_values.get("account_name")
container_name = env_values.get("container_name")
directory_name = env_values.get("directory_name") # optional
csv_file_name = 'salesfull.csv'
# Authenticate to Azure Data Lake Gen 2
#Initialize DataLakeServiceClient
client_id = env_values.get("client_id")
client_secret = env_values.get("client_secret")
tenant_id = env_values.get("tenant_id")
After successfully connecting, create a service_client that is needed to upload the CSV file saved in memory to the directory in the Azure Data Lake Gen2 account.
#Connect to Azure Storage Account
credential = ClientSecretCredential(tenant_id, client_id, client_secret)
service_client = DataLakeServiceClient(account_url=f"https://{account_name}.dfs.core.windows.net", credential=credential)
# Get the file system client (container)
file_system_client = service_client.get_file_system_client(file_system=container_name)
# Get the directory client
if directory_name:
directory_client = file_system_client.get_directory_client(directory_name)
else:
directory_client = file_system_client.get_root_directory_client()
# Get the file client
file_client = directory_client.get_file_client(csv_file_name)
Step 5: Upload File to Azure Data Lake Directory
The code below uploads the file (CSV) to the Azure storage account.
# Upload the CSV file content
file_client.upload_data(csv_buffer.getvalue(), overwrite=True)
print(f"File {csv_file_name} uploaded to Azure Data Lake Gen 2 successfully.")

Confirm the file upload by checking your Azure Data Lake Gen 2 account.
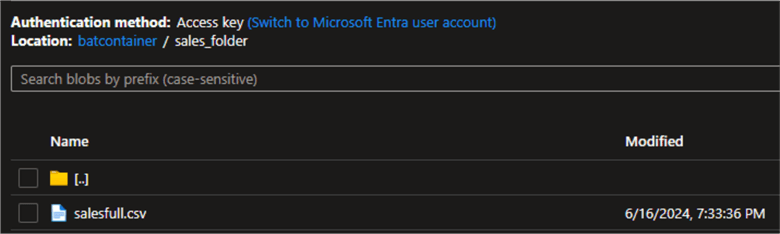
Execute Full Load from Azure Storage Account ADLS to Azure SQL Database
We have successfully moved the data from our on-premises SQL Server to the Azure Storage account. Next, we will perform the same process by moving the data from the Azure Storage account to the Azure SQL Database.
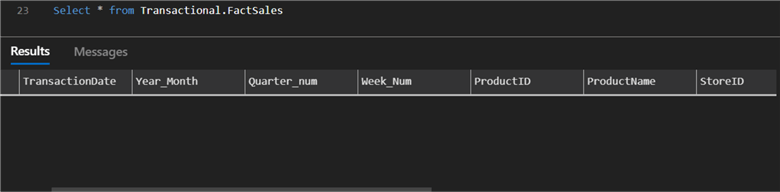
Step 1: Create a Table in Azure SQL Database
Firstly, let's create a table in our Azure SQL Database. Some transformation will be done before the files are written to the Azure SQL Database.
Create SCHEMA Transactional
GO
Create TABLE Transactional.FactSales (
TransactionID int PRIMARY KEY,
TransactionDate date,
Year_Month VARCHAR(30),
Quarter_num INT,
Week_Num VARCHAR(30),
ProductID INT,
ProductName VARCHAR(30),
StoreID INT,
StoreName VARCHAR(30),
SalespersonID INT,
SalespersonName VARCHAR(30),
QuantitySold INT,
TotalSalesAmount FLOAT,
Ingestion_Time DATETIME
)
GO
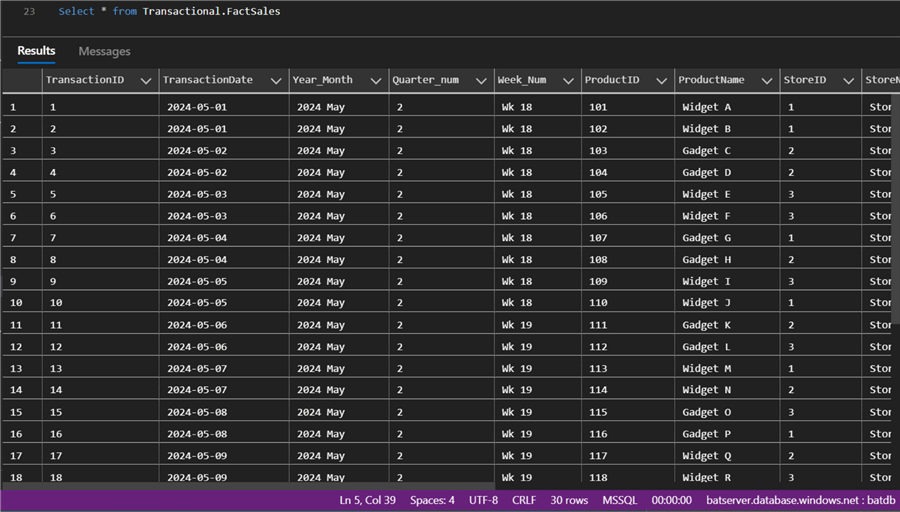
Select * from Transactional.FactSales
Step 2: Import All Necessary Libraries
In our Python notebook, we need to import all the necessary libraries for the migration and transformation process.
import os import pandas as pd from azure.identity import ClientSecretCredential from azure.storage.filedatalake import DataLakeServiceClient from sqlalchemy import create_engine, inspect import pyodbc import io from datetime import datetime from dotenv import load_dotenv, dotenv_values
Step 3: Set Credentials and Security
At this point, we need to import all necessary credentials needed for this project and set a security policy using the dotenv library in Python.
# Specify the directory where your .env file is located env_dir = r'C:\Users\Temidayo\xxxxxxxxxx\xxxxxxxxx\MSSQLTips_Folder_BAT' #This is to specify where the env file is saved upon. # Load environment variables from .env file in the specified directory env_values = dotenv_values(os.path.join(env_dir, '.env'))
Step 4: Authenticate ADLS and Read File
Verify the connection to the Azure Storage account to get a service client variable to authenticate the connection to Azure Data Lake Gen2.
# Authenticate to Azure Data Lake Gen 2
credential = ClientSecretCredential(tenant_id, client_id, client_secret)
service_client = DataLakeServiceClient(account_url=f"https://{account_name}.dfs.core.windows.net", credential=credential)
After connecting, we need to read the file in the storage account and save it to memory.
# Get the file system client (container)
file_system_client = service_client.get_file_system_client(file_system=container_name)
# List the files in the specified directory and get the latest file
paths = file_system_client.get_paths(path=directory_name)
latest_file = max(paths, key=lambda x: x.last_modified).name
# Download the latest file into memory
file_client = file_system_client.get_file_client(latest_file)
download = file_client.download_file()
downloaded_bytes = download.readall()
# Load the CSV data into a pandas DataFrame
csv_data = downloaded_bytes.decode('utf-8')
df = pd.read_csv(io.StringIO(csv_data))
Step 5: Transformation
Perform the needed transformation before loading the data to Azure SQL Database. The business users will use the transformed table system to generate insight and make decisions.
# Convert 'Date' column from object to datetime
df['TransactionDate'] = pd.to_datetime(df['TransactionDate'])
# Create a new column 'Year_Month' with the desired format
df['Year_Month'] = df['TransactionDate'].dt.strftime('%Y %B')
# Create a new column 'Quarter' with the quarter of the year
df['Quarter_num'] = df['TransactionDate'].dt.quarter
# Create a new column 'Week_Number' with the week number prefixed by 'Wk'
df['Week_Num'] = df['TransactionDate'].dt.isocalendar().week
df['Week_Num'] = df['Week_Num'].apply(lambda x: f'Wk {x}')
# Get the current UTC time
utc_now = datetime.utcnow()
# Add a new column 'ingestion_Time' with the current UTC time
df['Ingestion_Time'] = utc_now
After the needed transformations are done, we need to rearrange the columns to the correct format before loading it to the Azure Database table.
# Rearrange the columns
desired_order = [
'TransactionID', 'TransactionDate', 'Year_Month', 'Quarter_num',
'Week_Num', 'ProductID', 'ProductName', 'StoreID',
'StoreName', 'SalespersonID', 'SalespersonName', 'QuantitySold',
'TotalSalesAmount', 'Ingestion_Time'
]
df = df[desired_order]
Step 6: Write to Azure SQL Database and Verify Data Load
At this point, we need to verify the connection and create a connection string based on the login details.
# Create a SQLAlchemy engine for Azure SQL Database
connection_string = f"mssql+pyodbc://{sql_username}:{sql_password}@{sql_server}/{sql_database}?driver={sql_driver}"
engine = create_engine(connection_string)
After connecting, load the transformed file into the Azure SQL Database table.
# Write the transformed DataFrame to the Azure SQL Database table
df.to_sql(sql_table, engine, schema=sql_schema, if_exists='append', index=False)
print(f"Latest file {latest_file} uploaded to Azure SQL Database table {sql_table} successfully.")

To verify the writing process, log in to your SQL Server Management Studio and run the select query.
Section 4: Writing Incremental Script for both SQL Server to Azure Data Lake Gen 2 and Azure SQL Database
Logic Used for SQL Server On-premises to Azure Storage
We want to pick new rows of data incrementally as they are inserted into the SQL Server database. We will take the max value of the TransactionID column, then get the last modified file (latest file) in the ADLS, read through the file, and then get the max value of the TransactionID column of the latest file.
We then set a logic: if the max value of the SQL Server Database Table TransactionID is greater than the latest file (LastModified) in the ADLS TransactionID, then it should move the new values as a new file with the time stamp to ADLS. If both are equal in max value, then nothing should happen.
Step 1: Import All Necessary Libraries
Import all necessary files for this project.
import os import pandas as pd from azure.identity import ClientSecretCredential from azure.storage.filedatalake import DataLakeServiceClient from sqlalchemy import create_engine import io from datetime import datetime from dotenv import load_dotenv, dotenv_values
Step 2: Set Security and Credentials for Both SQL Server and Azure Storage Account
We need to set all the necessary credentials for both the SQL Server and ADLS using the dotenv library.
# Specify the directory where your .env file is located
env_dir = r'C:\Users\Temidayo\Documents\Medium Airflow\MSSQLTips_Folder_BAT' #This is to specify where the env file is saved upon.
# Load environment variables from .env file in the specified directory
env_values = dotenv_values(os.path.join(env_dir, '.env'))
# Azure Data Lake Gen 2 details
account_name = env_values.get("account_name")
container_name = env_values.get("container_name")
directory_name = env_values.get("directory_name") # The directory where the files are stored
# Azure AD credentials
client_id = env_values.get("client_id")
client_secret = env_values.get("client_secret")
tenant_id = env_values.get("tenant_id")
# SQL Server connection details
server = env_values.get("server")
database = env_values.get("database")
username = env_values.get("username")
password = env_values.get("password")
driver = 'ODBC Driver 17 for SQL Server'
table = 'dbo.salesfull'
Step 3: Get the Latest File in Azure Storage
Start by verifying the connection and get the max file from the Azure Storage Account.
# Authenticate to Azure Data Lake Gen 2
credential = ClientSecretCredential(tenant_id, client_id, client_secret)
service_client = DataLakeServiceClient(account_url=f"https://{account_name}.dfs.core.windows.net", credential=credential)
# Get the file system client (container)
file_system_client = service_client.get_file_system_client(file_system=container_name)
# List the files in the specified directory and get the latest file
paths = file_system_client.get_paths(path=directory_name)
latest_file = max(paths, key=lambda x: x.last_modified).name
latest_file
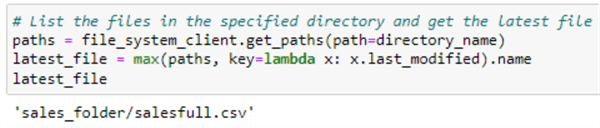
Notice: The same file is there since we have not inserted a new value in the ADLS.
Step 4: Get Max Row for Transaction ID for Both ADLS and SQL Server
Now that we know the latest file in the ADLS, we will read through to get the max value for the transaction ID column from the CSV file.
# Download the latest file into memory
file_client = file_system_client.get_file_client(latest_file)
download = file_client.download_file()
downloaded_bytes = download.readall()
# Load the CSV data into a pandas DataFrame
csv_data = downloaded_bytes.decode('utf-8')
df_existing = pd.read_csv(io.StringIO(csv_data))
# Get the maximum TransactionID from the existing data
max_existing_transaction_id = df_existing['TransactionID'].max()
max_existing_transaction_id
Repeat the same process to get the maximum value of the Transaction ID in the SQL Server.
# Create a SQLAlchemy engine for Azure SQL Database
connection_string = f"mssql+pyodbc://{username}:{password}@{server}/{database}?driver={driver}"
engine = create_engine(connection_string)
# SQL query to read data
query = "SELECT * FROM dbo.salesfull"
# Read data from SQL Server into a pandas DataFrame
df = pd.read_sql(query, engine)
df.shape
# Get the maximum TransactionID from the SQL Server table
query_max_transaction_id = f"SELECT MAX(TransactionID) as max_transaction_id FROM {table}"
max_transaction_id_sql = pd.read_sql(query_max_transaction_id, engine).iloc[0]['max_transaction_id']
max_transaction_id_sql

Step 5: Perform Movement Logic
The logic set is that if the max value for the transactional ID column is greater than that of the latest file transactional ID column, then the new rows of data should be moved from the SQL Server to ADLS as a new file.
# Check if there are new rows in the SQL Server table
if max_transaction_id_sql > max_existing_transaction_id:
# SQL query to read new data
query_new_data = f"SELECT * FROM {table} WHERE TransactionID > {max_existing_transaction_id}"
# Read new data from SQL Server into a pandas DataFrame
df_new = pd.read_sql(query_new_data, engine)
# Generate the file name with the current timestamp
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
incremental_file_name = f"sales_{timestamp}.csv"
# Convert the DataFrame to CSV in memory
csv_buffer = io.StringIO()
df_new.to_csv(csv_buffer, index=False)
csv_data = csv_buffer.getvalue()
# Upload the CSV file to Azure Data Lake Gen 2
file_client = file_system_client.get_file_client(f"{directory_name}/{incremental_file_name}")
file_client.upload_data(csv_data, overwrite=True)
print(f"Incremental file {incremental_file_name} uploaded to Azure Data Lake Gen 2 successfully.")
else:
print("No new data found. No file was created.")

You will notice the output indicates no new file are found because both the ADLS and SQL Server have the same amount of values for their storage.
Logic Used for Azure Storage and Azure SQL Database
We will use the same logic as the one above, where we compare the max value of the column from the latest file in ADLS and that of the Azure SQL Database
Step 1: Import All Necessary Libraries
Import all libraries needed for this project.
import os import pandas as pd from azure.identity import ClientSecretCredential from azure.storage.filedatalake import DataLakeServiceClient from sqlalchemy import create_engine import pyodbc import io from datetime import datetime from dotenv import load_dotenv, dotenv_values
Step 2: Set Security and Credentials
Set the needed security using the dotenv file to store security information.
# Specify the directory where your .env file is located
env_dir = r'C:\Users\Temidayo\Documents\Medium Airflow\MSSQLTips_Folder_BAT' #This is to specify where the env file is saved upon.
# Load environment variables from .env file in the specified directory
env_values = dotenv_values(os.path.join(env_dir, '.env'))
# Azure Data Lake Gen 2 details
account_name = env_values.get("account_name")
container_name = env_values.get("container_name")
directory_name = env_values.get("directory_name") # The directory where the files are stored
# Azure AD credentials
client_id = env_values.get("client_id")
client_secret = env_values.get("client_secret")
tenant_id = env_values.get("tenant_id")
# Azure SQL Database details
sql_server = env_values.get("sql_server")
sql_database = env_values.get("sql_database")
sql_username = env_values.get("sql_username")
sql_password = env_values.get("sql_password")
sql_driver = 'ODBC Driver 17 for SQL Server'
sql_table = 'FactSales'
sql_schema = 'Transactional'
Step 3: Authenticate and Get the Max Column Value from the Latest File in ADLS
Using the given credentials, create a service_client and get the max value of the transactional column of the latest file in ADLS. Then, save the file to memory.
# Authenticate to Azure Data Lake Gen 2
credential = ClientSecretCredential(tenant_id, client_id, client_secret)
service_client = DataLakeServiceClient(account_url=f"https://{account_name}.dfs.core.windows.net", credential=credential)
# Get the file system client (container)
file_system_client = service_client.get_file_system_client(file_system=container_name)
# List the files in the specified directory and get the latest file
paths = file_system_client.get_paths(path=directory_name)
latest_file = max(paths, key=lambda x: x.last_modified).name
# Download the latest file into memory
file_client = file_system_client.get_file_client(latest_file)
download = file_client.download_file()
downloaded_bytes = download.readall()
# Load the CSV data into a pandas DataFrame
csv_data = downloaded_bytes.decode('utf-8')
df_adls = pd.read_csv(io.StringIO(csv_data))
# Get the max TransactionID from the ADLS file
max_transaction_id_adls = df_adls['TransactionID'].max()
max_transaction_id_adls
Step 4: Connect to Azure SQL Database and Get Max Value of Transaction ID Column
Create a connection string to the Azure SQL Database and get the max value of the Transaction Column.
# Create a SQLAlchemy engine for Azure SQL Database
connection_string = f"mssql+pyodbc://{sql_username}:{sql_password}@{sql_server}/{sql_database}?driver={sql_driver}"
engine = create_engine(connection_string)
# Get the max TransactionID from the Azure SQL Database
query_max_transaction_id = f"SELECT MAX(TransactionID) FROM {sql_schema}.{sql_table}"
max_transaction_id_sql = pd.read_sql(query_max_transaction_id, engine).iloc[0, 0]
max_transaction_id_sql
Step 5 Perform Logic and Transformation
At this point, we need to perform all necessary transformations and arrange the columns. Then, we perform the logic to compare the values in the ADLS to those of the Azure SQL Database table.
# Compare the max TransactionID values
if max_transaction_id_adls > max_transaction_id_sql:
# Filter the new data
new_data = df_adls[df_adls['TransactionID'] > max_transaction_id_sql]
# Perform any required transformation
new_data['TransactionDate'] = pd.to_datetime(new_data['TransactionDate'])
new_data['Year_Month'] = new_data['TransactionDate'].dt.strftime('%Y %B')
new_data['Quarter_num'] = new_data['TransactionDate'].dt.quarter
new_data['Week_Num'] = new_data['TransactionDate'].dt.isocalendar().week.apply(lambda x: f'Wk {x}')
utc_now = datetime.utcnow()
new_data['Ingestion_Time'] = utc_now
# Rearrange the columns to match the SQL table
desired_order = [
'TransactionID', 'TransactionDate', 'Year_Month', 'Quarter_num',
'Week_Num', 'ProductID', 'ProductName', 'StoreID',
'StoreName', 'SalespersonID', 'SalespersonName', 'QuantitySold',
'TotalSalesAmount', 'Ingestion_Time'
]
new_data = new_data[desired_order]
# Append the new data to the Azure SQL Database table
new_data.to_sql(sql_table, engine, schema=sql_schema, if_exists='append', index=False)
print(f"New data successfully appended to the table {sql_schema}.{sql_table}.")
else:
print("No new data to insert.")

Section 5: Batch File to Create a Workflow Process
What are Windows Batch Files?
Batch files are a type of script used in the Windows operating system known as .bat. They are used for automating tasks, usually in plain text with a list of commands that, when you double-click the file, the Command Prompt runs through, line by line.
Now, let's save the two incremental scripts as a .py file and create a .bat file to run both scripts simultaneously based on the success of the first script. This way, we create a workflow approach using the .bat file.
Create Workflow with Batch File
The following steps should be followed to achieve this process:
Step 1: Echo Command and Necessary File Path
The @echo off is used to turn off the command prompt echoing, which means the command will not display in the command prompt.
We also define the various file paths for the different Python scripts we want to run in sequence.
@echo off REM Define the paths to the Python interpreter and scripts set python_path="C:\Users\Temidayo\anaconda3\python.exe" set script1_path="C:\Users\MSSQLTips_Folder_BAT\MSSQLTips_Incremental_Load_Between_SQL_Server_and_ADLS.py" set script2_path="C:\MSSQLTips_Folder_BAT\MSSQLTips_Incremental_Transformation_ADLS2_ Azure_SQL_Database.py"
Then, log all information to a log.txt file in the same directory.
REM Define the path for log files set log_path="C:\Users\Temidayo\Documents\Medium Airflow\MSSQLTips_Folder_BAT\log.txt"
Step 2: Get Data Time for Python Script Run
Add the date and time for each script. This will help with tracking for further purposes.
REM Get current date and time
for /f "tokens=1-4 delims=/ " %%a in ('date /t') do (set mydate=%%c-%%b-%%a)
for /f "tokens=1-4 delims=:. " %%a in ('time /t') do (set mytime=%%a:%%b:%%c)
Step 3: Run the Script and Log to a Log.txt File
This line of code is used to run the individual Python scripts and record the information to a log file.
REM Run script 1 and log output with date and time echo %mydate% %mytime% Running script 1 > %log_path% 2>&1 %python_path% %script1_path% >> %log_path% 2>&1 set script1_exit_code=%errorlevel%
Step 4: Check Success Logic
This block of code is used to check if the first Python script ran successfully. If it does, it gives an exit of 0 and then runs the second Python script. With this approach, we have achieved the workflow process based on the success of the first script.
REM Check if script 1 was successful
if %script1_exit_code% equ 0 (
REM Script 1 was successful, now run script 2 and log output with date and time
echo %mydate% %mytime% Running script 2 >> %log_path% 2>&1
%python_path% %script2_path% >> %log_path% 2>&1
set script2_exit_code=%errorlevel%
REM Optionally, you can check script 2 exit code here if needed
) else (
echo %mydate% %mytime% Script 1 failed. Script 2 will not be executed. >> %log_path%
)
echo %mydate% %mytime% Task completed. Check log at %log_path%
Now, ensure you save the file with a .bat extension and run it by double-clicking on the file.
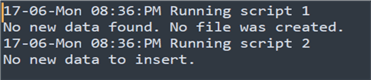
This will automatically run both scripts and log the information into the log.txt file.
Create CRON Job with Task Scheduler
In our last article, I provided a well-detailed step on how to configure Windows Task Scheduler for your Python script. This time, we will repeat this same process but for a batch file.
Step 1: Add New Rows of Data to the SQL Server On-premises
Write the SQL query below to insert new records into the SQL Server database table.
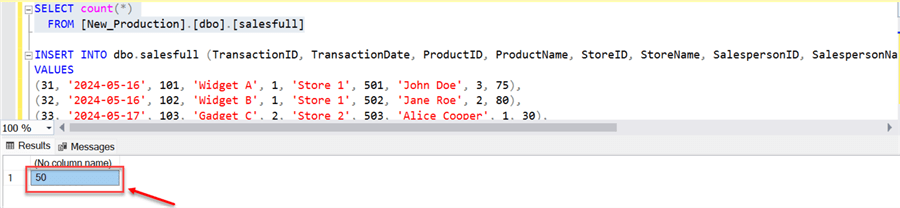
INSERT INTO dbo.salesfull (TransactionID, TransactionDate, ProductID, ProductName, StoreID, StoreName, SalespersonID, SalespersonName, QuantitySold, TotalSalesAmount) VALUES (31, '2024-05-16', 101, 'Widget A', 1, 'Store 1', 501, 'John Doe', 3, 75), (32, '2024-05-16', 102, 'Widget B', 1, 'Store 1', 502, 'Jane Roe', 2, 80), (33, '2024-05-17', 103, 'Gadget C', 2, 'Store 2', 503, 'Alice Cooper', 1, 30), (34, '2024-05-17', 104, 'Gadget D', 2, 'Store 2', 504, 'Bob Marley', 4, 120), (35, '2024-05-18', 105, 'Widget E', 3, 'Store 3', 505, 'Charlie Brown', 2, 60), (36, '2024-05-18', 106, 'Widget F', 3, 'Store 3', 506, 'David Smith', 3, 75), (37, '2024-05-19', 107, 'Gadget G', 1, 'Store 1', 507, 'Eve Adams', 2, 50), (38, '2024-05-19', 108, 'Gadget H', 2, 'Store 2', 508, 'Frank White', 1, 25), (39, '2024-05-20', 109, 'Widget I', 3, 'Store 3', 509, 'Grace Lee', 4, 100), (40, '2024-05-20', 110, 'Widget J', 1, 'Store 1', 510, 'Hank Green', 3, 75), (41, '2024-05-21', 111, 'Gadget K', 2, 'Store 2', 511, 'Ivy Blue', 2, 70), (42, '2024-05-21', 112, 'Gadget L', 3, 'Store 3', 512, 'Jack Black', 1, 35), (43, '2024-05-22', 113, 'Widget M', 1, 'Store 1', 513, 'Karl Marx', 3, 90), (44, '2024-05-22', 114, 'Widget N', 2, 'Store 2', 514, 'Leon Trotsky', 2, 60), (45, '2024-05-23', 115, 'Gadget O', 3, 'Store 3', 515, 'Maggie Simpson', 1, 30), (46, '2024-05-23', 116, 'Gadget P', 1, 'Store 1', 516, 'Nina Williams', 4, 100), (47, '2024-05-24', 117, 'Widget Q', 2, 'Store 2', 517, 'Oscar Wilde', 3, 75), (48, '2024-05-24', 118, 'Widget R', 3, 'Store 3', 518, 'Pablo Picasso', 2, 50), (49, '2024-05-25', 119, 'Gadget S', 1, 'Store 1', 519, 'Quincy Jones', 1, 25), (50, '2024-05-25', 120, 'Gadget T', 2, 'Store 2', 520, 'Rachel Ray', 4, 120);
Confirm the new values; you will notice the number of rows has increased from 30 to 50.
Step 2: Orchestrate Batch File with Task Scheduler
In your Windows server, search for Task Scheduler, then set the following parameters.
General Settings
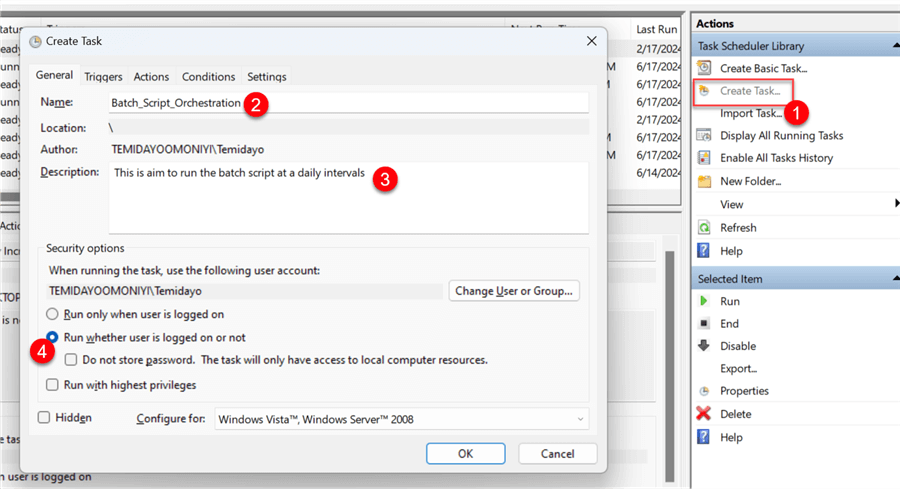
Click Create Task in the right corner and fill in the following information.
Triggers
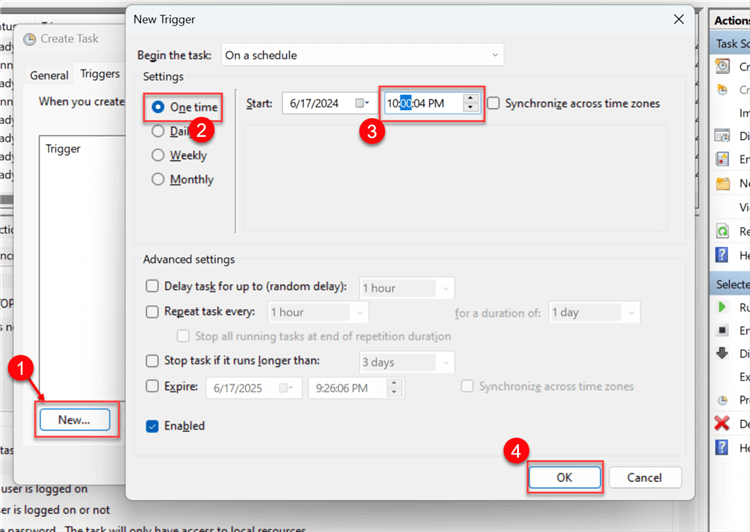
From the Trigger pane, click New and configure as shown in the image. We are conducting a test so we will be running the trigger just one time. But for a production environment, the schedule should be daily with the right time interval.
Action
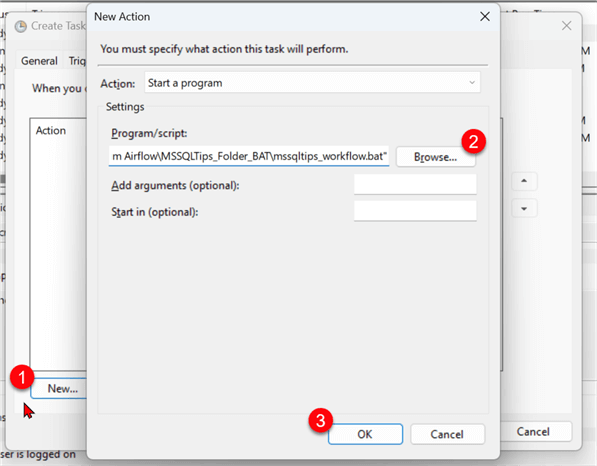
For the Action pane, browse and select the mssqltips_workflow.bat file, then click OK.
Now, wait for the scheduled time for the Batch file to run.
Confirm CRON JOB
Now that the Task Scheduler ran successfully, let's check the log file to confirm the run and then check the ADLS and Azure SQL Database.
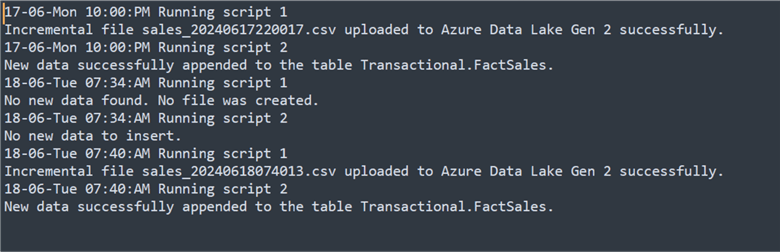
In the Azure Storage Account, we will see different files serving as incremental loads from the SQL Server that have been partitioned with the different timestamps added.

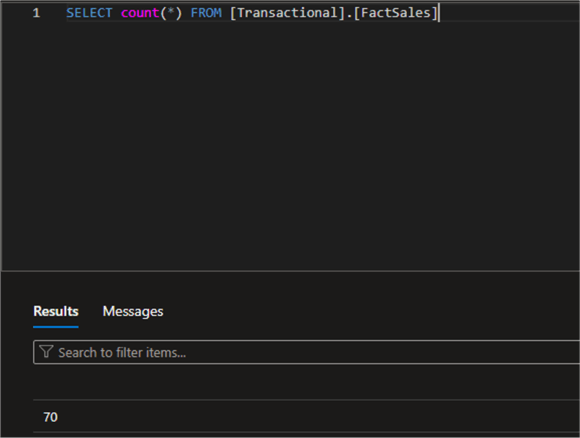
Also, confirm the data in the Azure SQL Database. You will notice the number of rows is 70. This is because more data was loaded to the SQL Server on-premises database.
Conclusion
In this article, we have covered how to automate an ETL data pipeline in a Windows Server using a batch file to run multiple Python scripts based on the success of the first. In this approach, we created a workflow like most modern data orchestration tools. We also provisioned most Azure resources used in this project using the Azure CLI on our Windows machine.
This project is a continuous series, where further improvements would be made to make it fully functional. You will notice I didn't cover the Connection String aspect to SQL Server database. Our future articles in the series will demonstrate how to push data from an application based on the connection string to SQL Server.
Next Steps
- Connecting PostgreSQL with SQLAlchemy in Python
- Connecting to SQL Database using SQLAlchemy in Python
- How to Create SQL Server Objects Programmatically with SQL Alchemy for Python
- Using Python with T-SQL
- Download code for this article






About the author
 Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience.
Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-08-08
