By: Harris Amjad | Updated: 2024-09-18 | Comments | Related: More > Artificial Intelligence
Problem
Natural Language Processing (NLP) is currently all the rage in the current machine learning landscape. With technologies like ChatGPT, Gemini, Llama, and so many other state-of-the-art text generators getting popular with the mainstream public, many newcomers are pouring into the field of NLP. Unfortunately, before we delve into how these fancy chatbots work, we must understand how we are engineering and treating our data before we feed it to our model. In this tip, we will introduce and implement some basic text preprocessing and cleaning techniques with Python.
Solution
It is not a surprising revelation that the majority of the world's data we encounter daily is swathes of unstructured textual data. Although newspapers and books form one portion of it, most of the data is generated on the internet through web pages, social media apps, texting apps, and emails. Given the sheer volume of data available, businesses and other organizations can leverage this raw information source into various patterns and insights to help better achieve their goals.

Let's take a look at a few examples. A clothing brand is very likely to closely monitor the customer reviews they are getting on a new product line in the market. If the reviews are in thousands, automation becomes a necessity, and text processing techniques come into play. On the other hand, social media and messaging app moderators may want to ensure a safe and toxicity-free environment. This also presents a need for a text sentiment analysis system whereby the system flags texts and forms as abusive and toxic so they may be removed with ease.
A much more relevant example in our current landscape is related to chatbot development. Large language models like the GPT and Llama series have been trained on several terabytes of raw text sourced from all over the internet. This text undergoes various stages of preprocessing and cleaning before a model can be trained on it.
To sum up, text cleaning and preprocessing are essential steps in textual analysis and language processing tasks. In the language of machine learning, we are essentially prepping our raw text data into somewhat meaningful features that can be fed into a model. Just like we prep our numerical data by removing outliers, missing, and erroneous values, text-based data also requires processing and cleaning steps to curb inconsistencies, noise, and errors in the data.
Therefore, the need for text data cleaning stems from the fact that:
- With raw data containing irrelevant words, spelling mistakes, emojis, and unwanted punctuation, such noise can be removed to achieve more relevant features for our model.
- Sometimes, a similar word can be expressed in several forms. For instance, playing, playing, play, plays, played…and so many more variations. Depending on the application, sometimes all you need is the essence of the word 'play' in this case for further analysis. Therefore, some processing techniques can help uniformize the data and reduce computational complexity by compressing the dataset.
- In sentiment analysis, often just a few words form highly explainable features for your model. The rest of the irrelevant features are dropped from the dataset. Considering the previous example of analyzing customer reviews, think about the relevance of words like 'if,' 'a,' 'the,' 'an,' 'my,' and 'am' in deciding whether a customer review is positive or negative. It's not very clear, right? Now consider the following words: 'nice,' 'great,' good,' and 'recommended.' It is not difficult to see that the second set of words predict a positive customer sentiment. Therefore, in use cases like these, we often drop commonly used words (referred to as 'stop words') from the dataset that are likely to appear in both positive and negative customer reviews.
- Machine learning models employ complicated mathematical functions to make predictions. We can easily feed numerical datasets into our models, but what about words and sentences? Therefore, often with textual models, additional processing steps are required to convert text into numerical features. This preprocessing step is termed tokenization.
Lastly, in the context of machine learning, we should also discuss the distinction between textual classification and regression tasks. Simply enough, in classification models, our inputted text will be fed into the model, and the model will subsequently predict a certain class for our input data. The illustration below highlights this process. The model below accepts a string of SMS and then classifies whether the input text is spam or not.
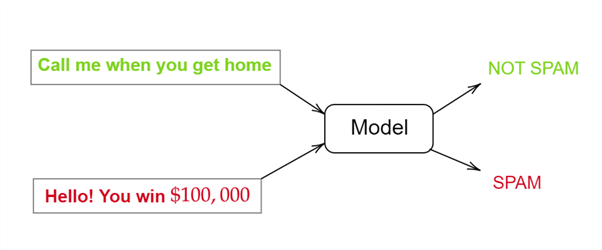
On the other hand, in regression-related tasks, our aim is to predict continuous numerical values associated with a text input to the model. Think of predicting a house price from a text description of a house.
Common Text Preprocessing Techniques
Now that we understand the need for text preprocessing and cleaning, let's take a look at some of the more typical standard techniques in detail and the rationale behind them.
Case Independence
This technique is used to uniformize text by treating words with different capitalization as the same entity. Therefore, words like 'Can,' 'CAN,' or even 'cAn' will all be converted to a single case (typically lowercase) as 'can.'
For certain use cases where text capitalization does not make sense, we resort to making all of the text lowercase. For instance, for the spam detection model we illustrated above, it does not make sense for the model to distinguish between 'win' or 'Win.' The model only needs semantic information of both words to make a prediction, which is completely the same for these words. Therefore, we avoid redundancy and simplify our data by this technique.
The function below provides a handy method to make the text case-independent.
#MSSQLTips.com
def lowercase(text):
return text.lower()
So, where does case independence not make sense? For the models meant to emulate natural language, we do not need to alter the case of our input training data.
Removing Punctuation
Punctuation removal process eliminates punctuation characters like periods, commas, question marks, exclamation points, colons, semicolons, quotation marks, parentheses, etc. Similar to the reasoning behind case independence, the primary goal is to simplify the text and reduce noise, making it easier for models to process and analyze the data.
However, in certain cases, punctuation removal is not relevant, or we do not remove all punctuation characters. For example, we might reserve periods and question marks to signify sentence boundaries. This can be important for translation models. Similarly, punctuation can alter the entire underlying meaning of sentences. As an example, the sentence, 'Let's eat, grandma' becomes 'Lets eat grandma' after punctuation removal. Just by removing a few characters, we have a very grim-sounding sentence on our hands.
Anyhow, here is an easy way to implement punctuation removal using the Python string library:
#MSSQLTips.com
import string
def remove_punctuation(text):
return ''.join(char for char in text if char not in string.punctuation)
Apart from normal punctuation, this function will also remove all non-alphabetic characters. In the case you need to remove only a certain type of character, we can design another function that makes use of regex. For instance, the function below removes all instances of periods, commas, question marks, and exclamation points from a given text.
#MSSQLTips.com
import re
def remove_specific_punctuation(text):
pattern = r'[.,!?]'
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
Removing Digits
As evident by the name, sometimes we need to remove all numeric characters (0-9) from our text data. We do this because sometimes numbers don't provide any vital information to our model. Thus, removing the digits helps remove unnecessary noise from our data and improves model performance. In sentiment analysis models, digits and numbers generally do not convey sentiment and thus can be removed. In topic modeling tasks where the goal is discovering topics within a collection of text documents, digits again may not form good descriptive features. Here's how we can do this in Python:
#MSSQLTips.com
def remove_dig(text):
return ''.join(char for char in text if not char.isdigit())
Removing Stopwords
Stopwords refer to the commonly used words in any given language that carry very little meaningful information on their own. This can include articles like 'a,' prepositions like 'in,' conjunctions, pronouns, and auxiliary words. More than often, for text classification tasks, stopwords are typically removed to reserve more meaningful and descriptive features in the text data. On the other hand, we really do not want to remove stopwords when dealing with training translation systems or conversational agents like ChatGPT.
Anyhow, the easier way to remove stopwords from your text dataset is to make use of the NLTK library in Python. It already contains a set of common English stopwords that we can conveniently use to process our dataset. The following function below does just that:
#MSSQLTips.com
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
def remove_stop_words(text):
return ' '.join(word for word in text.split() if word.lower() not in stop_words)
Removing Extra White Space
Sometimes people make mistakes. Sometimes, these mistakes are in the form of extra white spaces in your text dataset. Again, this induces unnecessary noise in the data and carries no meaningful information for the model to learn. The following function helps remove all of the extra white space from your dataset:
#MSSQLTips.com
def remove_space(text):
return ' '.join(text.split())
Generally, mistakes in text datasets are in the form of typos. Although fixing typos in a very extensive dataset feels like a chore, fortunately, some Python libraries use very efficient spell correction algorithms to replace typos with their correct spellings.
Removing URLs
URLs are another thing that does not contribute much information during model training. Although we are using URLs in this example, there can be a lot of other patterns, like emails or Twitter handles, that we do not want in our dataset.
In our case, we are again using regex to eliminate URLs using the following function:
#MSSQLTips.com
import re
def remove_url(text):
return re.sub(r'http\S+|www\S+|https\S+', '', text, flags=re.MULTILINE)
Stemming and Lemmatization
These are other important text normalization techniques in natural language processing. However, to understand these techniques better, we have to get a bit more familiar with linguistics–the science of language.
Sometimes, a word can take several forms without changing its grammatical category. These are known as inflectional words. For instance, 'write,' 'wrote,' 'written,' and 'writing' are all verbs with the same underlying sentiment. The words 'wrote,' 'written,' and 'writing' are inflected forms of the base word 'write.' On the other hand, when new words form from existing words, the new words are referred to as derivational words. The new words are sometimes a part of a new grammatical category altogether. We see that the word 'kind' is an adjective, but if we attach the suffix 'ness' to form 'kindness,' we get a new word entirely, a noun.
The goal of stemming and lemmatization is to convert all these word variations into their common root or base words. These techniques are particularly necessary in search retrieval systems to help them recognize different morphological variations of a single base word. Furthermore, as we have discussed before, these techniques allow us to reduce the dimensionality of data and group similar words, which can be useful for many text classification models.
Although stemming merely removes common suffixes from words to convert them to their base word, it is a rather crude process based on simple heuristics. Lemmatization algorithms, on the other hand, employ vocabulary and a proper morphological analysis of words to find the base word.
Both of these tasks are facilitated easily in Python by the NLTK library. Below is a function that helps us achieve stemming in Python:
#MSSQLTips.com
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
def stem_words(text):
return ' '.join(stemmer.stem(word) for word in text.split())
Tokenization
Text tokenization is a very fundamental technique in our current landscape, especially in the training of large language models. This technique is all about how we feed the text data to our model for training. The main goal here is to convert text in a manner that is meaningful for models without losing the underlying information. We do this by breaking text into smaller units. Paragraphs can be broken down into individual sentences, and the sentences themselves can be broken down into words. Advanced tokenizers can break down words into even smaller units. These subsequently smaller units are called tokens.
Tokenization, therefore, chunks unstructured textual data into smaller segments. These segments form a sequence that we can then pass into a model in an ordered arrangement for sequential processing of input data. We should also note that often the type of tokenization depends on the model we are employing.
Example Demonstration in Python
Now that we have a thorough understanding of text cleaning and preprocessing techniques, let's go through a practical demonstration where we prepare the Ecommerce Text Classification dataset for object classification.
To get started, we will first read our dataset into a Pandas dataframe. As we can see below there are two columns in the dataframe, but the one relevant to us is the 'text' column.
#MSSQLTips.com
import pandas as pd
header = ['category', 'text']
df = pd.read_csv('/content/ecommerceDataset.csv', header=None)
df.columns = header
df.head()

Now, we simply need to design a function that compiles all of our text cleaning and processing functions in a single place and apply that to the 'text' column. Also, note that we need to be careful about what steps we take before the other while implementing the preprocessing step.
#MSSQLTips.com def clean_text(text): lower = lowercase(text) no_URL = remove_url(lower) no_punc = remove_punctuation(no_URL) no_dig = remove_dig(no_punc) no_space = remove_space(no_dig) no_stop = remove_stop_words(no_space) stemwords = stem_words(no_stop) return stemwords
Now, we can implement this function to iterate over each row of the data frame for the 'text' column.
#MSSQLTips.com df['text'] = df['text'].apply(clean_text) df.head()

Now, we can observe the cleaned and processed text column above. Note any changes? Although at a glance, the tweets are now lowercase, the punctuation and stopwords are removed, and the URLs are also gone, some of the words, however, seemingly now have wrong spellings. Why is that? Remember that we used a stemming algorithm here; although it is fast, it is based on simple rules to remove suffixes from all words. As such, it is bound to make such mistakes. This problem can be mitigated by using a lemmatizer instead.
Regardless, our dataset is now prepared to be tokenized and passed into a machine learning model for the training step. Since we have labels in the above dataset, it is ideal for a supervised learning setup for a tweet sentiment analysis task.
Conclusion
In this tip, we explored the concept of text cleaning and processing techniques. We first established the reason and need for these techniques while working with text-based datasets. Then, we familiarized the readers with some of the most frequently used techniques for preparing text datasets, alongside various examples where these methodologies might be relevant. To solidify these concepts, we then provided a Python implementation of the techniques explained, alongside an example demonstration on a text dataset.
Next Steps
- The most obvious next step for interested readers is to explore lemmatization in the context of the example we explored above. It is important to note that although computer scientists or anyone else working with textual data do not require a deep understanding of linguistics, they should still have the basics prepped up.
- Furthermore, although we only presented a very brief overview of text tokenization, readers are advised to delve into this topic further and try it out for themselves using NLTK or any other library on the above dataset. Readers should also check out when the different types of tokenization schemes are relevant.
- Another cleaning step in the above dataset would have been to replace the typos with correct spellings. See how this can be achieved with different libraries.
- Lastly, while working with text, an intermediate knowledge of regex is an essential prerequisite. For readers who want to explore advanced text cleaning techniques, they are advised to brush up on their regex skills.
- For more AI related tips






About the author
 Harris Amjad is a BI Artist, developing complete data-driven operating systems from ETL to Data Visualization.
Harris Amjad is a BI Artist, developing complete data-driven operating systems from ETL to Data Visualization.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-09-18
