By: Levi Masonde | Updated: 2024-09-02 | Comments | Related: More > Artificial Intelligence
Problem
You are a software developer witnessing the AI revolution, just like everyone. Most developers are at a crossroads: do you join the revolution or hope it's a phase that won't affect you and your work in the long run? With the introduction of new technologies like ChatGPT4o and all the industry-leading companies having AI incorporated into their businesses, it is safe to admit that we have reached a point of no return, and AI will only increase in popularity and influence in all businesses.
So, how do you get involved with AI as a developer? Where do you start?
Solution
Natural language AIs like ChatGPT4o are powered by Large Language Models (LLMs). You can look at the overview of this topic in my previous article. As much as theory and reading about concepts as a developer is important, learning concepts is much more effective when you get your hands dirty doing practical work with new technologies.
In this tutorial, we will build an LLM application using LangChain to show you how to start implementing AI in your applications. We will create a question-answer chatbot using the retrieval augmented generation (RAG) and web-scrapping techniques.
Prerequisites
- Visual Studio Code
- Python
- LangChain
What are LLMs?
LLMs are natural language machine learning models built using neural networks pre-trained with trillions of tokens (text data). LLMs split sentences into tokens, or groups of characters, before sending the prompt to the model using a tokenization method. You can learn more about LLMs in this article: Large Language Models (LLMs) to train artificial intelligence (AI) tools such as ChatGPT.
What is LangChain and How It Works
LLMs, by default, have been trained on a great number of topics and information based on the internet's historical data. If you want to build an AI application that uses private data or data made available after the AI's cutoff time, you must feed the AI model the relevant data. The process of bringing and inserting the appropriate information into the model prompt is known as retrieval augmented generation (RAG). We will use this technique to enhance our AI Q&A later in this tutorial.
LangChain is a Python framework built to enable developers to feed custom data to LLMs and to interact with LLMs in the following ways:
- Chains: Creates a chain of operations within a workflow. LangChain enables you to link actions like calling APIs, querying multiple LLMs, or storing data into one operation.
- Agents: Makes decisions based on the output of the LLM.
- Memory: Maintains the state and history of context across different interactions.
- Indexes: Uses tools that manage and create indexes to be queried by LLMS using vector stores.
- Retrievers: Fetches relevant information from various sources, such as databases, APIs, document collections, or retrieval augmented generation, based on queries generated by LLMs.
Text Embedding Models and Vector Stores
Text embedding is a way to represent pieces of text using arrays of numbers. This transformation is essential for Natural Language Processing because computers understand numeric representation better than raw text. Once the text is transformed, it exists on a specific coordinate in a vector space where similar texts are stored close to each other.
Vector stores are responsible for storing vectors and running vector searches for you. First, you must get data from your source and embed it into a vector store. When you want to send a query, the query is embedded and then the vector store searches for similar vectors from the vector store, sending the results back as the answer:
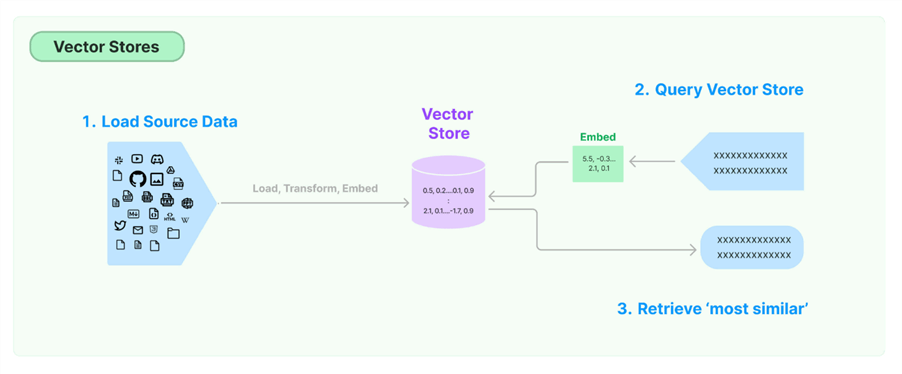
Source: https://python.langchain.com/v0.1/docs/modules/data_connection/vectorstores/
Large Language Model Providers
Different LLM providers in the market mainly focus on bridging the gap between established LLMs and your custom data to create AI solutions specific to your needs. Essentially, you can train your model without starting from scratch, building an entire LLM model. You can use licensed models, like OpenAI, that give you access to their APIs or open-source models, like GPT-Neo, which give you the full code to access an LLM.
Creating an LLM Application
In this section, you will create the base for a Q&A application. This is when you send a question to the LLM and get an answer. As discussed earlier, you can use the RAG technique to enhance your answers from your LLM by feeding it custom data.
First, you must install LangChain on your environment. To do this, open your terminal on Visual Studio Code and run this pip command:
pip install langchain
Next, use the following pip command for the dotenv module:
pip install python-dotenv
Then, create a .env file and add the following code:
LANGCHAIN_API_KEY=<Your_API_Key>
Keep in mind that you might have to add your API keys to your system's environment variables.
Then create a new file named LLM_App.py and add the following code to check if your environment can pick up your variables:
from dotenv import load_dotenv
import os
load_dotenv() # This loads environment variables from the .env file
tracing = os.getenv('LANGCHAIN_TRACING_V2')
api_key = os.getenv('LANGCHAIN_API_KEY')
print(f'Tracing Enabled: {tracing}')
print(f'API Key: {api_key}')
When running this code, you should see this output:

Then, let's add Cohere as our LLM provider. Login to Cohere, use the default API key, and add it to your .env file:
Once done, install the LangChain Cohere using this pip command:
pip install -U langchain-cohere
Let's start writing code for a Q&A application with no custom external data. Using the default RAG class on your LLM_app.py file, add the following code:
from dotenv import load_dotenv
import os
from langchain_cohere import CohereRagRetriever,ChatCohere
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
# Load environment variables from the .env file
load_dotenv()
# Retrieve environment variables
tracing = os.getenv('LANGCHAIN_TRACING_V2')
langchain_api_key = os.getenv('LANGCHAIN_API_KEY')
cohere_api_key = os.getenv('COHERE_API_KEY')
# Check if environment variables are loaded properly
if not cohere_api_key:
raise ValueError("COHERE_API_KEY environment variable not set.")
# User query we will use for the generation
user_query = "what is MSSQLTIPS and who created it"
# Load the cohere chat model
cohere_chat_model = ChatCohere(cohere_api_key=cohere_api_key)
# Create the cohere rag retriever using the chat model
rag = CohereRagRetriever(llm=cohere_chat_model, connectors=[])
# Get the cohere generation from the cohere rag retriever
docs = rag.invoke(user_query)
# Print the documents
for doc in docs[:-1]:
print(doc.metadata)
print("\n\n" + doc.page_content)
print("\n\n" + "-" * 30 + "\n\n")
# Print the final generation
answer = docs[-1].page_content
print(answer)
This will provide an answer to be displayed on your terminal:
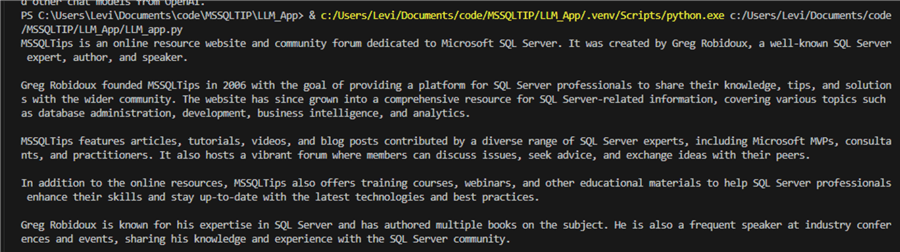
The results seem great. But, if we run the function again, these are the results:
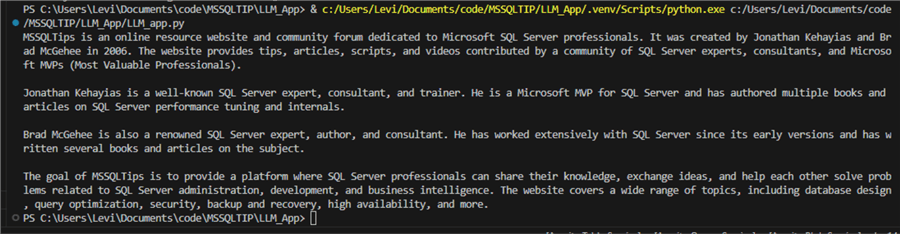
As you can see, the results are now different and incorrect this time. Unfortunately, nobody can technically explain why this happens. It is all part of AI “hallucination.”
One way of increasing the accuracy of your LLM search results is by setting the temperature parameter to 0 when declaring your LLM on the LLM_app.py file. This is on line 55:
cohere_chat_model = ChatCohere(cohere_api_key=cohere_api_key, temperature=0)
This ensures that your results do not change too much when re-run.
Using Web Scrappers with LLMs
Another way of increasing the accuracy of your LLM search results is by declaring your custom data sources. This way, your LLM can answer questions based mainly on your provided data source. Using a tool like Apify, you can create an automated web-scrapping function that can be integrated with your LLM application. This will enable you to choose a web data source for your LLM queries.
To avoid mixing the two codes prematurely, create another Python file named ApifyQA_app.py and add the following code:
from dotenv import load_dotenv
import os
import cohere
from apify_client import ApifyClient
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
from langchain_community.vectorstores import FAISS
from langchain_cohere import CohereEmbeddings
from langchain_cohere import CohereRagRetriever,ChatCohere
# Load environment variables from the .env file
load_dotenv()
# Retrieve environment variables
cohere_api_key = os.getenv('COHERE_API_KEY')
# Check if environment variables are loaded properly
if not cohere_api_key:
raise ValueError("COHERE_API_KEY environment variable not set.")
# Initialize Apify client
apify = ApifyWrapper()
# Define the function to map dataset items to Document objects
def dataset_mapping_function(item):
return Document(
page_content=item.get("text", ""),
metadata={"source": item.get("url", "")}
)
# Start URL for the crawler (using a full URL instead of a relative path)
start_url = "https://www.mssqltips.com/about/#:~:text=About%20MSSQLTips%20MSSQLTips.com%20was%20started%20in%202006%20by,a%20different%20approach%20to%20learning%20about%20SQL%20Server."
# Call the Apify actor to crawl the website content
loader = apify.call_actor(
actor_id="apify/website-content-crawler",
run_input={"startUrls": [{"url": start_url}]},
dataset_mapping_function=dataset_mapping_function,
)
# Define the embedding function using Cohere
embedding_function = CohereEmbeddings(cohere_api_key=cohere_api_key)
# Create the Vectorstore index
index_creator = VectorstoreIndexCreator(embedding=embedding_function)
index = index_creator.from_loaders([loader])
# Define the Cohere LLM
llm = ChatCohere(temperature=0)
# Query the vector store
query = "what is MSSQLTIPS and who created it"
result = index.query(query, llm=llm)
print(result)
Running this query, which is the same query we ran on the previous script, you get this result:

This is a result that reflects the website's content:
As you can see, the results are heavily influenced by the data source we feed our LLM.
This tutorial covers an LLM that uses a default RAG technique to get data from the web, which gives it more general knowledge but not precise knowledge and is prone to hallucinations. We also covered web-scrapping retrievers added to an LLM. This ensures that the LLM outputs have controlled and precise content.
Conclusion
LLMs played a huge role in pushing AI to the spotlight, especially today, as most companies want to eventually have custom AI systems. Starting an AI system from scratch can only be done by companies with huge pockets; most will have to settle for existing LLM models and customize them to their organization's requirements.
This tutorial teaches you the basic concepts of how LLM applications are built using pre-existing LLM models and Python's LangChain module and how to feed the application your custom web data.
Next Steps
- Learn how to use LangChain Prompt Templates with OpenAI LLMs.
- You can also learn more about how LLMs work.
- Learn how to Create AI Models with T-SQL to Buy or Sell Financial Securities.
- Learn more about Artificial Intelligence Features in Power BI for Report Development.
- Learn how they use Large Language Models (LLMs) to train artificial intelligence (AI) tools such as ChatGPT.






About the author
 Levi Masonde is a developer passionate about analyzing large datasets and creating useful information from these data. He is proficient in Python, ReactJS, and Power Platform applications. He is responsible for creating applications and managing databases as well as a lifetime student of programming and enjoys learning new technologies and how to utilize and share what he learns.
Levi Masonde is a developer passionate about analyzing large datasets and creating useful information from these data. He is proficient in Python, ReactJS, and Power Platform applications. He is responsible for creating applications and managing databases as well as a lifetime student of programming and enjoys learning new technologies and how to utilize and share what he learns.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-09-02
