By: Sebastiao Pereira | Updated: 2024-09-10 | Comments | Related: > XML
Problem
Extensible Markup Language (XML) is widely used in applications to share data between users. As more information is stored, exchanged, and presented in XML, it's crucial to have the ability to query XML data effectively. XML's strength lies in its versatility to represent various types of information from different sources. To make the most of this flexibility, an XML query language needs features that allow us to retrieve and understand data from these diverse sources.
How do you deal with XML data using T-SQL?
Solution
XML Terms and Definitions
Let's take into consideration the following XML example:
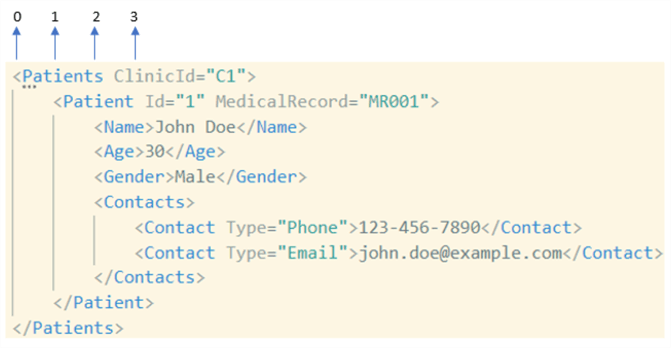
Nodes
- Root: The top-most ancestor for all nodes, in our case <Patients>.
- Element: A start tag and an end tag, like <Name>…</Name>.
- Attribute: Represents an attribute of an element, providing additional information about it, like "Id" and "MedicalRecord" for <Patient>.
- Text: Contains the text within an element, like "30" is the text node of <Age>.
- Parent: Directly connected to another node as its predecessor, like <Contacts> is the parent node of <Contact>.
- Child: Directly connected to another node as its successor, like <Name> is the child node of <Patient>.
- Sibling: Share the same parent node, like <Name> and <Age>.
- Ancestor: Any node that is higher up in the hierarchy and connected through one or more parent nodes, like <Patient> and <Patients> are ancestor nodes of <Name>.
- Descendant: Any node lower down in the hierarchy and connected through one or more child nodes, like the two <Contact> in <Contacts>.
Singleton
In SQL Server XML querying, a singleton is a single node. The value method requires the XPath expression to select just one node, and if it selects multiple nodes, you must use predicates to limit the result to one node, or the method will throw an error. For example, using singleton will return only the selected singleton, like the first, second, etc.
Namespaces
An XML namespace is a collection of names that can be used as element or attribute names in an XML document. Namespaces are used to avoid conflicts between elements with the same name, which can happen when developers define element names and documents from different applications are mixed. For example, if two XML fragments contain a <table> element, but the elements have different content and meaning, there will be a name conflict. To simplify, prefixes are added to the element name, like for Countries <countries:name>, and another one for Persons <persons:name>, etc.
Schema
An XML schema describes the structure of an XML document, and the XML schema language is referred to as XML Schema Definition (XSD).
Working with Examples
Querying an XML Variable
Let's use the XML below as an example to work with:
DECLARE @Records xml
SET @Records = '<Patients ClinicId="C1">
<Patient Id="1" MedicalRecord="MR001">
<Name>John Doe</Name>
<Age>30</Age>
<Gender>Male</Gender>
<Contacts>
<Contact Type="Phone">123-456-7890</Contact>
<Contact Type="Email">[email protected]</Contact>
</Contacts>
</Patient>
</Patients>
';
Run the following query to extract the name of the patients:
SELECT Rec.Pat.value('(Name)[1]', 'nvarchar(50)') AS PatientName
FROM @Records.nodes('Patients/Patient') AS Rec(Pat);
Explaining the code:
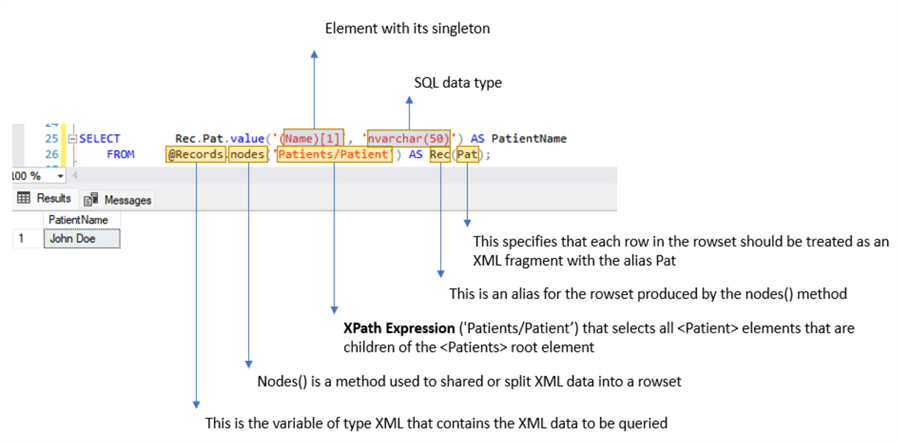
Now, we will retrieve the remaining data:
SELECT Pat.value('(../@ClinicId)[1]', 'nvarchar(50)') AS ClinicId
,Pat.value('(@Id)[1]', 'nvarchar(50)') AS PatientId
,Pat.value('(@MedicalRecord)[1]', 'nvarchar(50)') AS MedicalRecord
,Pat.value('(Name)[1]', 'nvarchar(50)') AS PatientName
,Pat.value('(Age)[1]', 'int') AS PatientAge
,Pat.value('(Gender)[1]', 'nvarchar(10)') AS PatientGender
,Pat.value('(Contacts/Contact)[1]', 'nvarchar(50)') AS PatientPhoneOkBut
,Pat.value('(Contacts/Contact)[2]', 'nvarchar(50)') AS PatientEmailOkBut
,Pat.query('Contacts/Contact[@Type="Phone"]').value('.', 'nvarchar(50)') AS PatientPhone
,Pat.query('Contacts/Contact[@Type="Email"]').value('.', 'nvarchar(50)') AS PatientEmail
FROM @Records.nodes('Patients/Patient') AS Rec(Pat);

Let's pay attention to these details:
- Attributes of a node can be read using the character @AttibuteName, like for Patient Id and Medical Record in the <Patient> element.
- I introduced two ways to retrieve <Contact> data, the method value using singleton, for the first [1] and the second [2] occurrences, which is ok if we can ensure that all phone data will come first; otherwise, it is better to query the PAT alias for the correct value using the contact attribute @Type.
- Observe that the attribute ClinicId of <Patients> is at the root element. Once the XPATH expression starts in the path Patients/Patient to read the record, we use the notation "../", which means one node above. In some cases, if you need to go further, use "../../" for two nodes above, and so on.
Querying an XML Table
Let's create a table to store the XML data:
CREATE TABLE [dbo].[Patients]( [RecordId] [int] IDENTITY(1,1) NOT NULL, [RecordData] [xml] NULL, PRIMARY KEY CLUSTERED ( [RecordId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO
Once we already have the data stored in the variable @Records, let's insert it into the Patients table:
INSERT INTO [dbo].[Patients]
([RecordData])
VALUES (@Records);
To retrieve the data, we only need to make one modification to the SELECT statement to add the table name and use CROSS APPLY with the XML column in the FROM clause:
SELECT Pat.value('(../@ClinicId)[1]', 'nvarchar(50)') AS ClinicId
,Pat.value('(@Id)[1]', 'nvarchar(50)') AS PatientId
,Pat.value('(@MedicalRecord)[1]', 'nvarchar(50)') AS MedicalRecord
,Pat.value('(Name)[1]', 'nvarchar(50)') AS PatientName
,Pat.value('(Age)[1]', 'int') AS PatientAge
,Pat.value('(Gender)[1]', 'nvarchar(10)') AS PatientGender
,Pat.value('(Contacts/Contact)[1]', 'nvarchar(50)') AS PatientPhoneOkBut
,Pat.value('(Contacts/Contact)[2]', 'nvarchar(50)') AS PatientEmailOkBut
,Pat.query('Contacts/Contact[@Type="Phone"]').value('.', 'nvarchar(50)') AS PatientPhone
,Pat.query('Contacts/Contact[@Type="Email"]').value('.', 'nvarchar(50)') AS PatientEmail
FROM [dbo].[Patients] AS Records CROSS APPLY
Records.RecordData.nodes('Patients/Patient') AS Rec(Pat);
The only issue is that the XML column in the Patients table currently accepts any XML content. This means it is recommended that we proceed to the next step, which is to include new items.
XML Validation
To validate an XML, we use the XSD schema, and there are several ways to create an XSD for an XML. I will use Visual Studio Code as an example to create it. Open an XML file with the data of the @Record variable, and click the mouse over the dots in <Patients and choose:
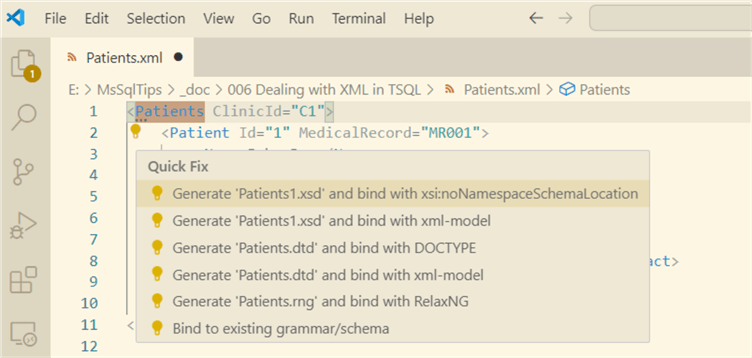
The XML respective XSD is created at the folder where the XML file resides. With the mouse over the Patient.xsd, click on Follow link:
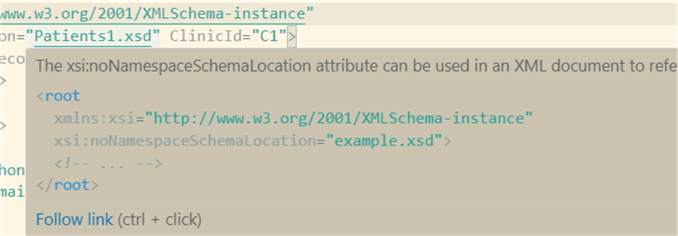
This will open the created schema, copy it, and apply the following code to
add to our database XML Schema collection. Disregard the code "<?xml
version="1.0" encoding="UTF-8"?>".
CREATE XML SCHEMA COLLECTION PatientSchema AS
N'<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Patients">
<xs:complexType>
<xs:sequence>
<xs:element name="Patient">
<xs:complexType>
<xs:sequence>
<xs:element name="Name" type="xs:string" />
<xs:element name="Age" type="xs:string" />
<xs:element name="Gender" type="xs:string" />
<xs:element name="Contacts">
<xs:complexType>
<xs:sequence>
<xs:element name="Contact" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="Type" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="Id" type="xs:integer" use="required" />
<xs:attribute name="MedicalRecord" use="required" />
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="ClinicId" use="required" />
</xs:complexType>
</xs:element>
</xs:schema>
';
To see what schemas are stored in our schema collection, execute the following:
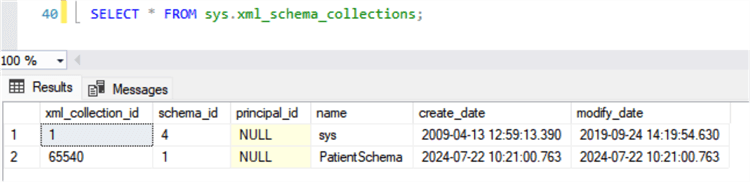
Once the XSD schema is available we can check if a record can be inserted in our table using the following:
DECLARE @NewRecord XML(PatientSchema);
BEGIN TRY
SET @NewRecord = '<Patients ClinicId="C1">
<Patient Id="1" MedicalRecord="MR001">
<SurName>John Doe</SurName>
<Age>30</Age>
<Gender>Male</Gender>
<Contacts>
<Contact Type="Phone">123-456-7890</Contact>
<Contact Type="Email">[email protected]</Contact>
</Contacts>
</Patient>
</Patients>
';
INSERT INTO [dbo].[Patients]
([RecordData])
VALUES (@NewRecord);
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END
-- Print error information.
PRINT 'Error: ' + CONVERT(varchar(50), ERROR_NUMBER()) +
', Severity: ' + CONVERT(varchar(5), ERROR_SEVERITY()) +
', State: ' + CONVERT(varchar(5), ERROR_STATE()) +
', Procedure: ' + ISNULL(ERROR_PROCEDURE(), '-') +
', Line: ' + CONVERT(varchar(5), ERROR_LINE());
PRINT ERROR_MESSAGE();
END CATCH;
This results in an error once I did not supply the element <Name> but <SurName>.

I aim to cover the basics of XML handling in T-SQL, but there are numerous possibilities. Each scenario requires adapting the code to meet your specific needs.
Next Steps
- A complete technical W3C guide can be found at XML Query Language (Second Edition).
- There are good examples in W3 Schools, including XSD schemas, at XML Tutorial.
- You can find more information about schema collections in Microsoft XML schema collections (SQL Server).






About the author
 Sebastiao Pereira has over 38 years of healthcare experience, including software development expertise with databases.
Sebastiao Pereira has over 38 years of healthcare experience, including software development expertise with databases.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-09-10
