By: Jared Westover | Updated: 2024-09-30 | Comments | Related: > TSQL
Problem
A few weeks ago, I helped someone combine multiple integer columns into a single column. The common term for this process is unpivoting or transposing. The table they worked with had millions of rows, so they needed the most efficient method to accomplish this task. If you search online, you'll find several suggestions for doing this. But which performs best? Is one easier to maintain than the others?
Solution
In this tutorial, we'll look at how to combine multiple columns from a table into one column. I'll show three methods and review their syntax. Then, you can see which is the fastest and uses the least resources. By the end, you'll know how to combine columns in the most efficient way possible.
Why Combine Multiple Columns?
Why do you need to swap columns for rows? It's often because of the table's design. Sometimes, developers create tables in a wide format, where multiple columns represent similar attributes. For example, imagine a table with survey questions. Each column is a different question. In the table below, we store people's answers to questions about their favorite things in life.
| SurveyId | Person | Food | Movie | Song |
|---|---|---|---|---|
| 1 | Susan | Chocolate | Star Wars | Come As You Are |
| 2 | Neal | Coffee Toffee | Enter the Dragon | Take On Me |
| 3 | Aarav | Cotton Candy | Spider-Man | Creep |
I'm not saying that designing a table this way is ideal, but sometimes you work with what you have. In the example above, there's not much to unpivot, so let's look at another one.
The example below shows a contract table where each column represents a type of form used to create the contract. We need a way to transpose all the form columns into one without aggregating or worrying about the ContractId column.
| ContractId | SignedFormId | UnsignedFormId | PendingFormId | SupportingFormId |
|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 4 |
| 2 | 5 | 6 | 7 | 8 |
| 3 | 9 | 10 | 11 | 12 |
I want the results to look like the table below:
| FormId |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5….. |
Demo Data
Now, it's time to put together a dataset in SQL Server so we can explore how to combine the four columns into one. The code below creates a database with one table and 250,000 rows. Since performance is important, we need a dataset larger than just a few rows.
-- mssqltips.com
USE master;
IF DATABASEPROPERTYEX('ComboDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE ComboDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE ComboDemo;
END;
GO
CREATE DATABASE ComboDemo;
ALTER DATABASE ComboDemo SET RECOVERY SIMPLE;
GO
USE ComboDemo;
GO
DECLARE @UpperBound INT = 250000;
;WITH cteN (Number)
AS (SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number]
INTO dbo.Numbers
FROM cteN
WHERE [Number] <= @UpperBound;
GO
CREATE TABLE dbo.MegaTable
(
Id INT IDENTITY(1, 1) NOT NULL,
SignedFormId INT NULL,
UnsignedFormId INT NULL,
PendingFormId INT NULL,
SupportingFormId INT NULL
CONSTRAINT PK_MegaTable_Id
PRIMARY KEY CLUSTERED (Id)
);
INSERT INTO dbo.MegaTable
(
SignedFormId,
UnsignedFormId,
PendingFormId,
SupportingFormId
)
SELECT 4 * (Number - 1) + 1 AS SignedFormId,
4 * (Number - 1) + 2 AS UnsignedFormId,
4 * (Number - 1) + 3 AS PendingFormId,
4 * (Number - 1) + 4 AS SupportingFormId
FROM Numbers;
GO
Here is what our table looks like:
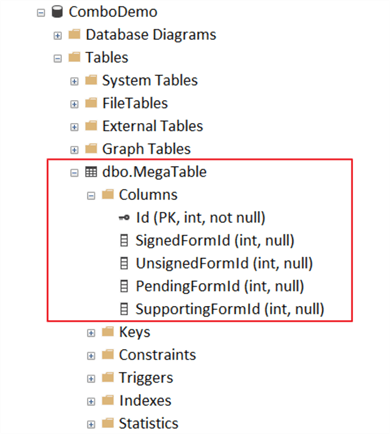
Exploring Options
Now that our dataset is in place, let's explore a few options and compare their performance. I'll measure performance by the total elapsed time and CPU time. Additionally, we'll compare logical page reads. For me, the time it takes for something to run is the ultimate performance measure, especially for the user experience. No one has ever told me, "Hey, this query takes 50ms but is doing 100K logical reads." However, there is a strong correlation between execution time and page reads.
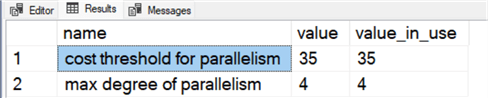
In case you're curious, I've included a screenshot with my lab settings for parallelism and MAXDOP.
-- mssqltips.com
SELECT name,
value,
value_in_use
FROM sys.configurations
WHERE name IN ( 'cost threshold for parallelism', 'max degree of parallelism' );
GO
As part of this experiment, we'll insert the results into a temporary table. I don't want to return a million rows to the user because my computer struggles to copy and paste that many into Excel.
You'll notice I'm running the following commands between each experiment:
-- mssqltips.com DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; CHECKPOINT; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO
Here's a brief synopsis of what each command does. I've included links to detailed descriptions.
- DBCC DROPCLEANBUFFERS: Removes all clean pages from the buffer pool that are already on disk.
- CHECKPOINT: Writes all dirty pages to disk.
- DBCC FREEPROCCACHE: Removes all execution plans from the plan cache.
UNPIVOT
First, we'll explore the UNPIVOT operator. It doesn't get as much love as its more popular sibling, PIVOT. Microsoft defines UNPIVOT as an operator that does the opposite task of PIVOT by rotating columns of a table-valued expression into column values.
The code below pivots the four columns into one and inserts them into a temporary table.
-- mssqltips.com
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
CHECKPOINT;
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
GO
DROP TABLE IF EXISTS #FormHolder;
CREATE TABLE #FormHolder (FormId INT NOT NULL);
GO
SET STATISTICS TIME, IO ON;
INSERT INTO #FormHolder
(
FormId
)
SELECT FormId
FROM
(
SELECT SignedFormId,
UnsignedFormId,
PendingFormId,
SupportingFormId
FROM dbo.MegaTable m
) m UNPIVOT(FormId FOR Forms IN(SignedFormId, UnsignedFormId, PendingFormId, SupportingFormId)) AS unpvt;
SET STATISTICS TIME, IO OFF;
GO
Results:
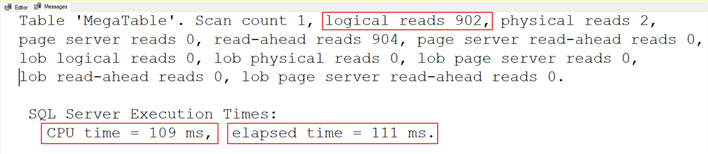
The results above are good for UNPIVOT. I always struggle with remembering the syntax for both PIVOT and UNPIVOT, but a quick search refreshes my memory.
UNION ALL
Our next contender is the UNION ALL operator. UNION ALL combines the results of multiple queries into a single result set. If you don't need to worry about duplicates, skip UNION since the optimizer adds a Sort operator. My first instinct to solve this problem was to use UNION ALL, mainly because the syntax is simple, and I like simple syntax.
-- mssqltips.com
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
CHECKPOINT;
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
GO
DROP TABLE IF EXISTS #FormHolder;
CREATE TABLE #FormHolder (FormId INT NOT NULL);
GO
SET STATISTICS TIME, IO ON;
INSERT INTO #FormHolder
(
FormId
)
SELECT SignedFormId AS FormId
FROM dbo.MegaTable
UNION ALL
SELECT UnsignedFormId
FROM dbo.MegaTable
UNION ALL
SELECT PendingFormId
FROM dbo.MegaTable
UNION ALL
SELECT SupportingFormId
FROM dbo.MegaTable;
SET STATISTICS TIME, IO OFF;
GO
Results:

It's easy to see that UNION ALL incurred significantly more logical reads, mainly because the optimizer chose a scan for each UNION ALL operation.
CROSS APPLY
Our last option—or at least the ones I look at—is CROSS APPLY. Even though SQL Server added CROSS APPLY nearly 20 years ago, people often shy away from using it. The APPLY operator comes in two forms: OUTER APPLY and CROSS APPLY. With a CROSS APPLY, SQL joins two table expressions like an INNER JOIN. The CROSS APPLY operator returns rows from the left table expression (in its final output) if they match the right table expression.
In the code below, I'm adding the VALUES clause, which takes rows and converts them into a table constructor.
-- mssqltips.com
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
CHECKPOINT;
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
GO
DROP TABLE IF EXISTS #FormHolder;
CREATE TABLE #FormHolder (FormId INT NOT NULL);
GO
SET STATISTICS TIME, IO ON;
INSERT INTO #FormHolder
(
FormId
)
SELECT FormId
FROM dbo.MegaTable
CROSS APPLY
(
VALUES
(SignedFormId),
(UnsignedFormId),
(PendingFormId),
(SupportingFormId)
) AS Combined (FormId);
SET STATISTICS TIME, IO OFF;
GO
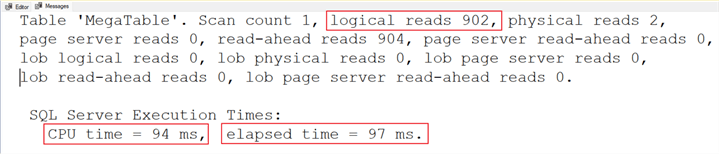
Results:
The Final Tally
The table below contains a tabulation of each method's performance results.
| Method | CPU time | Elapsed time | Logical Reads |
|---|---|---|---|
| UNPIVOT | 109ms | 111ms | 902 |
| UNION ALL | 125ms | 121ms | 3608 |
| CROSS APPLY | 94ms | 97ms | 902 |
For me, the clear winner is CROSS APPLY. It finishes faster, and the syntax is simpler than UNPIVOT. As with anything you read beyond pure facts, this is only my opinion. Some may prefer using UNPIVOT, and if you do, keep at it. Also, if this query is a one-time operation and performance isn't a concern, then UNION ALL might be a good choice.
Clean Up
My kids love singing the cleanup song, but I often forget to drop test tables and databases. Once you're done, run the statement below to drop the database.
-- mssqltips.com
USE master;
IF DATABASEPROPERTYEX('ComboDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE ComboDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE ComboDemo;
END;
GO
Key Points
- Sometimes, you don't have the perfect table design or the foresight to see how the application will grow over time. I've encountered several large tables with a wide column pattern throughout my career. It reminds me of the Jim Korkis quote, "It's what you do with what you got."
- Understand the trade-offs between the different methods. Each method, whether CROSS APPLY, UNION ALL, or UNPIVOT, has strengths and weaknesses.
- Ultimately, several methods lead to the same outcome. Pick one and try it out; maybe you'll prefer UNION ALL over CROSS APPLY because of the simpler syntax.
Next Steps
- Would you like to learn more about the APPLY operator? Check out the article "SQL Server CROSS APPLY and OUTER APPLY" for helpful examples.
- Do you find the PIVOT operator syntax confusing? I wrote the article "SQL Pivot Like a Pro" to demystify the code and encourage you to see it as a solid solution.
- For a deep dive into using SET STATISTICS TIME, please check out the article "Set Statistics Time Examples for Tuning SQL Server Queries" by Rick Dobson.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-09-30
