By: Hadi Fadlallah | Updated: 2024-10-17 | Comments | Related: > Python
Problem
In a bid to make decisions, obtain knowledge, or build applications, major institutions and individuals often have to retrieve and analyze large amounts of data from various websites, a gut-wrenching and siloed task that equally wastes time. Collecting and treating that data is tedious, prone to inaccuracies, and inefficient, especially when it comes to dynamic or extensive data.
Solution
Web scraping is the process of automatic data extraction from websites, turning unstructured web data into a structured format for sentiment analysis or machine learning. It enables efficient collection of large-scale data from multiple online sources, saving time and effort compared to manual data gathering.
This technique is important for obtaining real-time information, conducting market research, competitive analysis, or building data-driven applications. By automating the data collection process, web scraping tools provide valuable insights and supports informed decision-making across various industries.
In this tutorial, we will cover the basics of web scraping by providing a step-by-step tutorial using the Scrapy Python framework to collect and visualize data from the web.
Scrapy Framework
Scrapy is by far the most complex and freely available framework written in Python for web scraping and web crawling while facilitating the extraction and processing of data from web pages. It operates through spiders, a user-defined class that provides the method of spidering and scraping a particular webpage. Spiders issue GET requests to the web pages, generate HTML responses, and then extract specified details using CSS selectors or XPath. Extracted datasets are stored inside the specified formats (for instance, XML or CSV) or in databases.
Analyzing the Page Source Before Starting
First, visit the web page and visually analyze the page source. For this tip, we will read data from the MSSQLTips authors page.
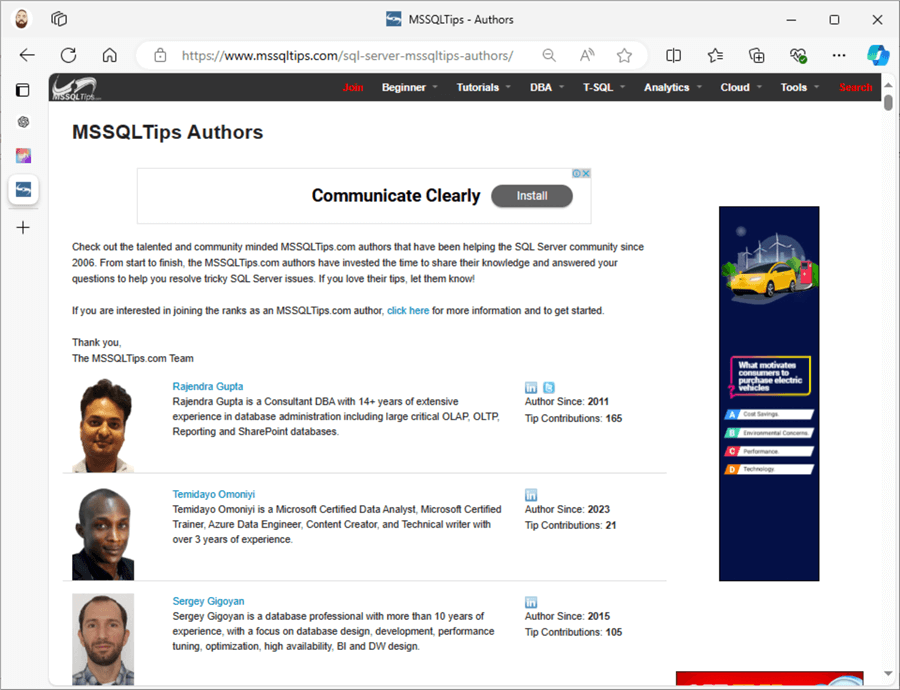
We can see that the authors' information is listed on the Authors page. Let's dive deep into the structure of each author card.
As shown below, we can see that each author card is mainly composed of a profile picture, author name, author biography, social accounts, and author details (starting year, number of contributions, and Microsoft MVP badge).

Let's check out the page source. Right-click on any of the elements of a card, i.e., the profile picture, and then click Inspect.
This will open the web browser developer tools, showing the page's HTML code and focusing on the selected element.
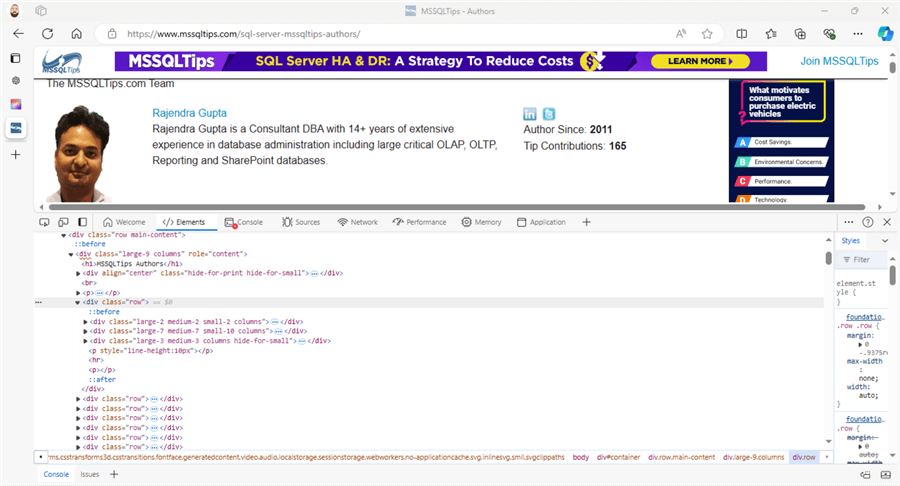
After analyzing the code, we can conclude the HTML tags attributes (class, name, etc.) for each element we need to extract. We will deep dive into this code in the web scraper configuration section.
It is crucial to note that the page source may change from one device to another or based on the screen resolution. Also, the website may be updated frequently, which means we need to update our web scraper accordingly.
Preparing the Environment
To begin, we should install the Scrapy framework from the command line.
Pip install scrapy
Next, at the beginning of our Python script, import the libraries we will use for this tutorial. We need four libraries from the Scrapy framework to crawl the website and some other libraries for data manipulation and visualization.
Libraries needed for scraping:
import scrapy as sc from scrapy import signals from scrapy.crawler import CrawlerProcess from scrapy.signalmanager import dispatcher
Libraries needed for data manipulation:
import pandas as pd import re import datetime Libraries needed for data visualization: import seaborn as sns import matplotlib.pyplot as plt
Configuring the Web Scraper
The following code defines a Scrapy spider called AuthorSpider. The intention of this spider is to collect information about authors from the MSSQLTips website, such as the Author Name, Profile URL, Author LinkedIn URL (if it exists), years the Author has been writing, number of tips contributed by the Author, and if he/she is Microsoft MVP.
- name and start_urls: These attributes define the name of the spider (author_spider) and the URL(s) from which the spider will start crawling.
- extract_author_info function: This function is used to extract specific information about authors from the HTML content. It takes the author_details as input, which represents the HTML content of the author's details, and returns the extracted information: author_since, tip_contributions, and mvp_status.
- parse method: This method is responsible for parsing the HTML content of the response. It extracts author information from each row of the webpage and yields a dictionary containing that information.
- It first selects all the rows containing author information using CSS selector .row.
- For
each row, it extracts:
- image_url: URL of the author's image.
- author_name: Name of the author.
- profile_url: URL of the author's profile.
- linkedin_url: URL of the author's LinkedIn profile (if available).
- author_details: HTML content of the third column containing additional author details.
- description: Author biography. We select the appropriate HTML element, convert it into a string, and strip any leading or trailing whitespaces.
- It then calls the extract_author_info function to extract author_since, tip_contributions, and mvp_status from the author_details.
- Finally, it yields a dictionary containing all the extracted information.
class AuthorSpider(sc.Spider):
name = "author_spider"
start_urls = ["https://www.mssqltips.com/sql-server-mssqltips-authors/"]
def extract_author_info(self, author_details):
# Initialize variables
author_since = ""
tip_contributions = ""
mvp_status = False
# Use regex to extract numeric values for "Author Since" and "Tip Contributions"
author_since_match = re.search(r'Author Since: <strong>(\d+)</strong>', author_details)
tip_contributions_match = re.search(r'Tip Contributions: <strong>(\d+)</strong>', author_details)
# Extract Author Since value
if author_since_match:
author_since = int(author_since_match.group(1))
# Extract Tip Contributions value
if tip_contributions_match:
tip_contributions = int(tip_contributions_match.group(1))
# Check if "Microsoft MVP" tag exists
if "Microsoft MVP" in author_details:
mvp_status = True
return author_since, tip_contributions, mvp_status
def parse(self, response):
author_rows = response.css(".row")
for row in author_rows:
# Extract author information
image_url = row.css("img::attr(src)").get()
if image_url:
image_url = response.urljoin(image_url) # Join relative URL with base URL
author_name = row.css("a[rel='author']::text").get()
profile_url = row.css("a[rel='author']::attr(href)").get()
# Extract LinkedIn profile URL
linkedin_url = row.css("a[href*='linkedin.com']::attr(href)").get()
# Extract additional details from the third column
third_column = row.css(".large-3.medium-3.columns.hide-for-small")[0]
author_details = third_column.css("p").get()
author_since, tip_contributions, mvp_status = self.extract_author_info(author_details)
# Description
description = row.css(".large-7.medium-7.small-10.columns").xpath("string()").get().strip()
# Follow the link to the author's profile page
yield sc.Request(url=response.urljoin(profile_url), callback=self.parse_author_profile,
meta={'image_url': image_url,
'name': author_name,
'profile_url': response.urljoin(profile_url),
'linkedin_url': response.urljoin(linkedin_url) if linkedin_url else None,
'description': description,
'starting_date': author_since,
'contributions': tip_contributions,
'mvp_status': mvp_status})
def parse_author_profile(self, response):
# Extract information from the author's profile page
image_url = response.meta.get('image_url')
author_name = response.meta.get('name')
profile_url = response.meta.get('profile_url')
linkedin_url = response.meta.get('linkedin_url')
description = response.meta.get('description')
starting_date = response.meta.get('starting_date')
contributions = response.meta.get('contributions')
mvp_status = response.meta.get('mvp_status')
yield {
"image_url": image_url,
"name": author_name,
"profile_url": profile_url,
"linkedin_url": linkedin_url,
"description": description,
"starting_date": starting_date,
"contributions": contributions,
"mvp_status": mvp_status
}
Starting the Web Scraper and Collecting Data
After defining and configuring the web scraper, we need to start it and store the results within a data file.
The following code defines a function author_spider_result() that runs a Scrapy spider (AuthorSpider) and collects the scraped results into a list. Here's a breakdown of the code:
- author_results list: This list is initialized to store the results of scraping. It will hold the data scraped by the spider.
- crawler_results function: This is an inner function defined within author_spider_result(). It takes a single argument item, which represents the data scraped by the spider for each item. Inside this function, the scraped item is appended to the author_results list.
- dispatcher.connect(): This function connects a signal from the Scrapy framework to a callback function. In this case, it connects the item_scraped signal to the crawler_results function. This means that every time an item is scraped by the spider, the crawler_results function will be called with the scraped item as an argument.
- crawler_process object: This creates an instance of the CrawlerProcess class, which is responsible for running the spider.
- crawler_process.crawl(AuthorSpider): This line instructs the crawler_process to crawl the spider AuthorSpider. It initializes and starts the spider.
- crawler_process.start(): This method starts the crawling process. It will run until all requests are processed and all items are scraped.
- return author_results: Finally, the function returns the author_results list, which contains the scraped data after the spider has finished crawling.
def author_spider_result():
author_results = []
def crawler_results(item):
author_results.append(item)
dispatcher.connect(crawler_results, signal=signals.item_scraped)
crawler_process = CrawlerProcess()
crawler_process.crawl(AuthorSpider)
crawler_process.start()
return author_results
After defining the crawling function, we need to use it to create a pandas data frame to store the crawled data.
df = pd.DataFrame(author_spider_result())
After storing the data within a Pandas data frame, we can save the data into a CSV file using the to_csv() function.
df.to_csv("mssqltips.csv", sep='|', encoding='utf-8')
Data Preprocessing
At this stage, we need to do some computations. This is where the average contribution per year for every author should be worked out.
- Convert Columns to Numeric: It converts the tip_contributions and author_since columns to numeric data type using pd.to_numeric(). This ensures these columns contain numbers, which will be needed in further calculations.
- Calculate Current Year: It determines the current year through datetime.date.today().year. This helps to obtain the present year and will be useful in the following computations.
- Calculate Years Since Author Started: It computes the years when a particular author started, using the formula current_year - df['author_since'] + 1. This shows the current year minus the year an author started and adds one to account for the present year.
- Calculate Contributions per Year: It gives the average contributions count to be per year over the years that particular author has been writing, using the formula df[‘tip_contributions'] / df[‘years_since_start']. This takes the number of contributions and divides it by the number of years the author has been writing.
# Convert tip_contributions and author_since to numeric df['contributions'] = pd.to_numeric(df['contributions']) df['starting_date'] = pd.to_numeric(df['starting_date']) # Calculate the current year current_year = datetime.date.today().year # Calculate the number of years since the author started df['years_since_start'] = current_year - df['starting_date'] + 1 # Calculate the average contributions per year df['contributions_per_year'] = df['contributions'] / df['years_since_start']
Data Visualization
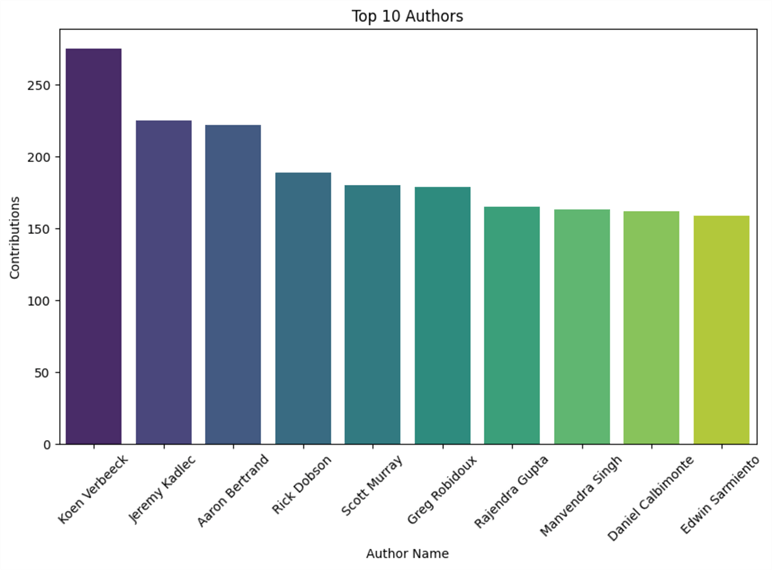
The final step is to visualize our crawled data. For instance, we can visualize the top 10 authors based on the number of contributions.
top_10_authors = df.nlargest(10, 'contributions')
plt.figure(figsize=(10, 6))
sns.barplot(x='name', y='contributions', data=top_10_authors, palette='viridis')
plt.title('Top 10 Authors')
plt.xlabel('Author Name')
plt.ylabel('Contributions')
plt.xticks(rotation=45)
plt.show()
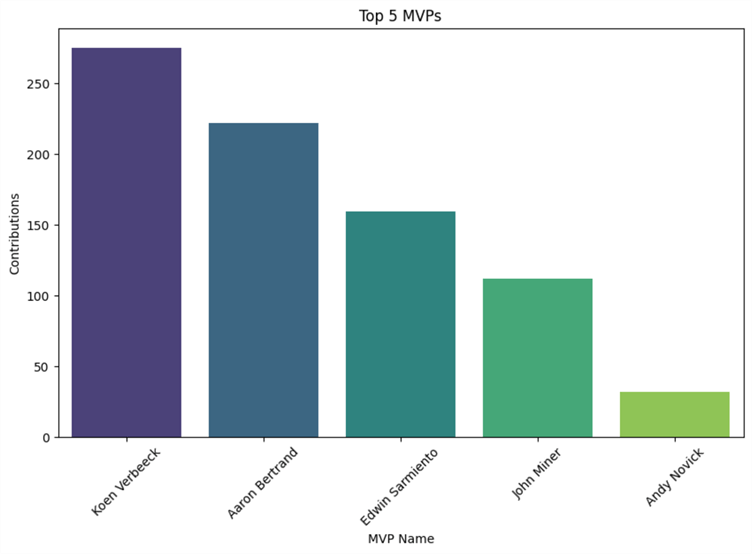
Also, we can visualize the top 5 MVPs based on the number of contributions:
top_5_MVPs = df[df['mvp_status']].nlargest(5, 'contributions')
plt.figure(figsize=(10, 6))
sns.barplot(x='name', y='contributions', data=top_5_MVPs, palette='viridis')
plt.title('Top 5 MVPs')
plt.xlabel('MVP Name')
plt.ylabel('Contributions')
plt.xticks(rotation=45)
plt.show()
Summary
This tip focused on installing and using Scrapy as a tool for web scraping, what to do with the scraped data, and how to use pandas with seaborn / matplotlib for data visualization.
Next Steps
- After you have set up and refined this part, start doing small projects that require you to scrape small portions of data from one simple website. Concentrate on learning the basics: items, spiders, pipelines, and Scrapy commands.
- Make attempts at crawling different websites, especially those with e-commerce, blogs, and news portal pages that are of a different composition. This will help you learn about and practice working with different HTML, pagination, AJAX, etc.
- Know how to work with the data that has been collected. Use Scrapy pipelines and learn how to save the collected data in different formats (CSV or JSON file), to a formal database (SQL, NoSQL), or other similar storage.






About the author
 Hadi Fadlallah is an SQL Server professional with more than 10 years of experience. His main expertise is in data integration. He's one of the top ETL and SQL Server Integration Services contributors at Stackoverflow.com. He holds a Ph.D. in data science focusing on context-aware big data quality and two master's degrees in computer science and business computing.
Hadi Fadlallah is an SQL Server professional with more than 10 years of experience. His main expertise is in data integration. He's one of the top ETL and SQL Server Integration Services contributors at Stackoverflow.com. He holds a Ph.D. in data science focusing on context-aware big data quality and two master's degrees in computer science and business computing. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-10-17
