By: Andrea Gnemmi | Updated: 2024-10-11 | Comments (2) | Related: > PostgreSQL
Problem
PostgreSQL has a unique way of dealing with deletes, marking rows as obsolete. It also manages concurrency using Multi-Version Concurrency Control (MVCC) differently than Oracle or SQL Server. For the management to work properly, it has unique features and processes, such as VACUUM and AUTOVACUUM.
Solution
In this two-part tip, we will learn what VACUUM and AUTOVACUUM processes are in PostgreSQL, how to properly tune them, and how concurrency is implemented in PostgreSQL with MVCC, including insight about how PostgreSQL memorizes data in memory pages. At the same time, we will look at the ANALYZE process.
VACUUM
A VACUUM procedure is used for recovering space occupied by "dead tuples" in a table. A dead tuple is created when a record is either deleted or updated (a delete followed by an insert). PostgreSQL doesn't physically remove the old row from the table but adds a "marker" to it so that queries do not return that row.
With time, this row space becomes obsolete and causes fragmentation and bloating. When a vacuum process runs, the space occupied by these dead tuples is marked reusable by other tuples, thus helping to shrink the data file size when required.
The VACUUM command does multiple things, not just recover or reuse the disk space occupied by obsolete rows. In fact, it:
- Updates data statistics with ANALYZE
- Updates the visibility map, which speeds up index-only scans (more on this later)
- Protects against loss of very old data due to transaction ID wraparound (again more on this later)
The VACUUM command can be run with various options, with the two usual modes being VACUUM and VACUUM FULL.
VACUUM only removes dead rows and marks the space available for future reuse. To be clear, this action does not return the space to the operating system; the recovery of space using normal VACUUM happens only if obsolete rows are at the end of a table.
VACUUM FULL instead uses a more aggressive algorithm as compared to VACUUM. Similar to SHRINK in SQL Server, it compacts tables by writing a completely new version of the table file with no dead space. Obviously, this takes more time and requires extra disk space for the new copy of the table until the operation completes. Exclusive access to the table is also required, thus blocking the table for DML operations. This is done through an explicit exclusive lock of the table for the duration of the VACUUM FULL operation.
Now, it is time for practical examples of manual VACUUM. First, we need to ensure that the extension PAGEINSPECT is created in our database, as we will need it to check the memory pages:
--MSSQLTips.com CREATE EXTENSION pageinspect;
Next, we can create a new table and insert some data:
--MSSQLTips.com create table test_vacuum_0 (id bigint, descrizione varchar(20)); insert into test_vacuum_0 values (1,'Test Vacuum');
Let's take a look at its size:
--MSSQLTips.com
select pg_size_pretty
(pg_relation_size('test_vacuum_0'));
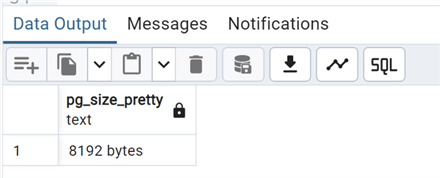
8Kb is just a memory page on disk. Now, let's do an update of this row to create a dead tuple:
--MSSQLTips.com update test_vacuum_0 set descrizione='Test' where id=1;
We then check the size again:
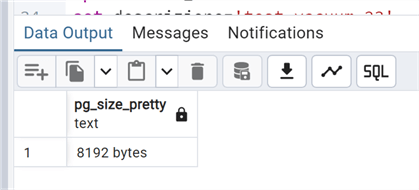
The size is the same as above. Let's do some more work in the table with both INSERT and DELETE:
--MSSQLTips.com insert into test_vacuum_0 values (2,'Test Vacuum'); delete from test_vacuum_0 where id=2;
Let's take a look directly at the memory page:
--MSSQLTips.com
SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('test_vacuum_0', 0));
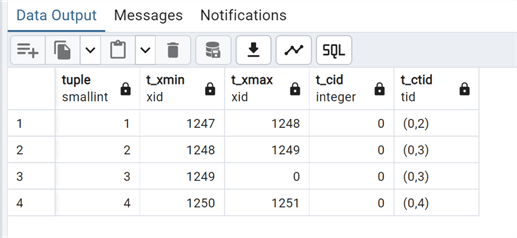
As you can see, we have an identifier of each row (tuple), as well as a t_xmin and a t_xmax, or values of transaction id between which this tuple is visible. Each transaction that is executed against the database increases a transaction number txid. Each transaction has its own identifier; in this case, tuple number 3 has no t_xmax, so it is visible starting from transaction id 1249. All the others have a min and max value, so the tuple is visible with a select only between these two transaction ids. (Note: A simple select is increasing the txid.) In practice, t_xmax is set to the transaction number that deleted or updated this tuple. If it has not been deleted or updated, it is set to 0. I will explain this in more detail later in the MVCC concurrency section.
Here is a quick look at the meaning of the other two columns:
- t_cid holds the command id (cid), which is the number of SQL commands that were executed before the actual one with this transaction. For example, assume that we execute four INSERT commands within a single transaction: 'BEGIN; INSERT; INSERT; INSERT; INSERT; COMMIT;'. If the first command inserts this tuple, t_cid is set to 0. If the second command inserts this tuple, t_cid is set to 1, and so on.
- t_ctid has the tuple identifier (tid) that points to itself or a new tuple. It is used to identify a tuple within a table. When this tuple is updated, the t_ctid of this tuple points to the new tuple; otherwise, the t_ctid points to itself.
These four data are the main part of the Header Data of how a tuple (row) is memorized inside a table page. To have a complete picture of the page layout, check out the official documentation.
Let's go back to VACUUM. We can now manually vacuum this table:
--MSSQLTips.com vacuum test_vacuum_0;
Take another look at the table page:
--MSSQLTips.com
SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('test_vacuum_0', 0));
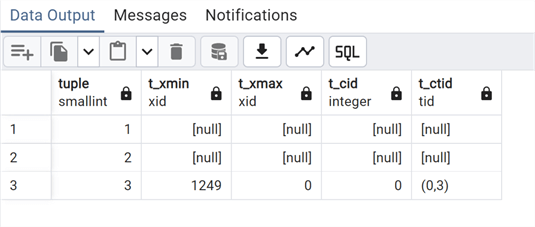
As expected, we only have the "live" tuple; all the dead tuples have been deleted from the memory page on disk.
Now, we can do an example with more data in more than one table page. Create a new table and fill it with more data:
--MSSQLTips.com create table test_vacuum (id bigint, descrizione varchar(20)); insert into test_vacuum values (generate_series(1,100000), 'Test vacuum');
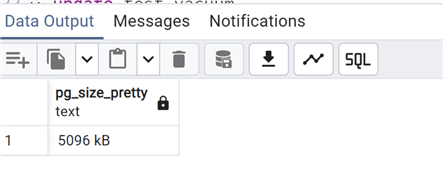
Take a look at the size:
--MSSQLTips.com
select pg_size_pretty
(pg_relation_size('test_vacuum'));
With a table and more data, we can perform some updates to create a few dead tuples:
--MSSQLTips.com update test_vacuum set descrizione='test_vacuum 23' where (id % 2) = 0;
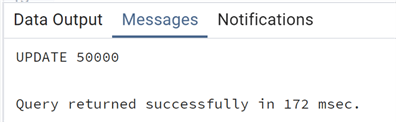
A quick note on the code: With
where (id % 2) = 0, we have
filtered only the even numbers that are divisible by 2. We have updated half of
the total rows in the table.
Look again at the size. It should now take into account all the dead tuples we created with the update:
--MSSQLTips.com
select pg_size_pretty
(pg_relation_size('test_vacuum'));
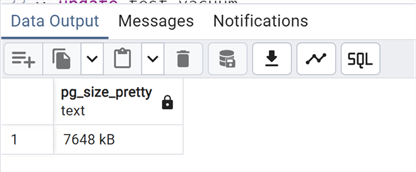
We can see the growth. Let's perform a simple VACUUM:
--MSSQLTips.com vacuum test_vacuum;
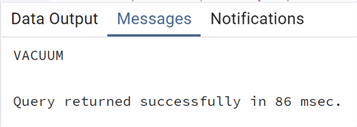
Check the size again:
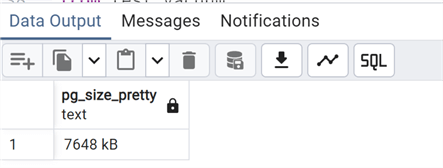
The size has not changed since we have not used the FULL option, which can also recover the disk space. Let's try it:
--MSSQLTips.com vacuum full test_vacuum;
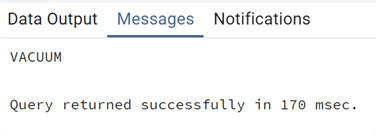
Has the space on the disk decreased?
--MSSQLTips.com
select pg_size_pretty
(pg_relation_size('test_vacuum'));
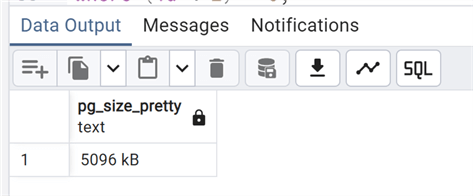
As expected, the size has returned to what it was at the beginning of the test.
Note: The FULL option should be used with caution. It will take an exclusive lock on the table for the whole duration of the VACUUM (plus additional space temporarily).
VACUUM can also be used to update the visibility map. But what is it?
Each relation (table) has a visibility map that keeps track of which pages contain only valid tuples and ones with only frozen tuples (more on FREEZE later). It is stored in different files than the normal database pages of the tables, but the filename contains the reference to the relation. It looks like this: <relfilenode>_vm.
It has two functions:
- It helps vacuum determine whether pages contain dead rows.
- Most importantly, it can be used by index-only scans to answer queries quicker. If it's known that all tuples on the page are visible, the heap fetch can be skipped, and as the visibility map is vastly smaller than the actual pages, it can be cached easily in memory.
Every VACUUM action updates this visibility map with the live and dead tuples.
There are two additional options for VACUUM: FREEZE and ANALYZE. These introduce us to an extremely important feature: the need for VACUUM FREEZE or FULL to prevent transaction id wraparound.
But first, we need to see how PostgreSQL implements CONCURRENCY using MVCC.
MVCC in PostgreSQL
Multi-Version Concurrency Control (MVCC) is a method used by PostgreSQL to handle concurrency and ensure data consistency. As the name implies, MVCC allows multiple transactions to access the database concurrently (for example, with multiple SELECT and UPDATE) without blocking each with locks, but with different data versions that need to be accessed.
When data is modified in the examples above, PostgreSQL doesn't overwrite the existing data; instead, it creates a new version. Each tuple/row has metadata, including transaction IDs (t_xmin and t_xmax), to indicate which transaction created it and which marked it as deleted. Every transaction has assigned a unique transaction ID (txid). The txid helps to determine the visibility of a tuple to a transaction by comparing the transaction's txid with the tuple's t_xmin and t_xmax.
We use the txid number to point to the visibility of a tuple. This number is automatically assigned to each transaction executed on the database. So, each query run has a txid, and the actual value can be checked by a simple SELECT. Note: Even this SELECT will get a txid assigned.
--MSSQLTips.com SELECT txid_current();
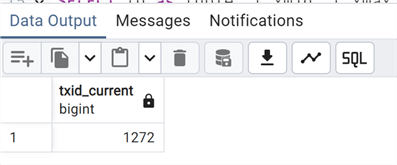
However, this number is limited. It is a 32-bit unsigned integer, so the maximum value is 4,294,967,295, or roughly 4.2 billion. PostgreSQL treats the txid number as a circle, like a circular time-space. The previous 2.1 billion txids are "in the past," and the next 2.1 billion txids are "in the future," thus only the ones in the past are visible.
Now, let's assume that we have a live tuple, Tuple_1, that is inserted with a txid of 100, i.e., the t_xmin of Tuple_1 is 100. The PostgreSQL cluster has been running for a very long time, and Tuple_1 has not been modified.
The current txid is 2.1 billion + 100 and a SELECT command is executed. At this time, Tuple_1 is visible because txid 100 is in the past. See picture:
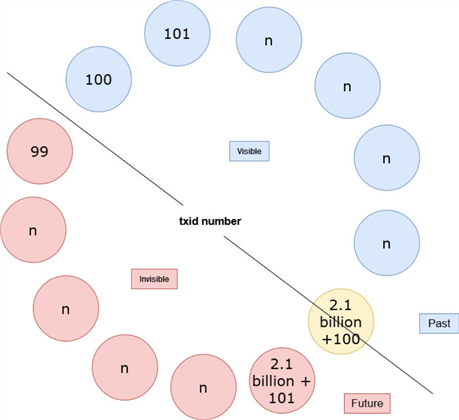
Then, the same SELECT command is executed again; thus, the current txid is 2.1 billion + 101. However, Tuple_1 is no longer visible because txid 100 is in the future! See picture:
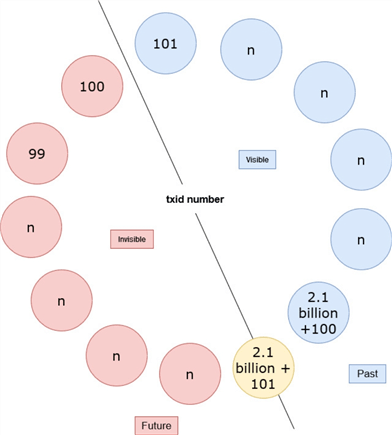
This causes a catastrophic data loss. Interestingly, data is still there, but it is no longer visible! This condition is called transaction id (or txid) wraparound failure.
VACUUM FREEZE
Fortunately, VACUUM FREEZE prevents this problem from occurring. How does it work?
Basically, VACUUM FREEZE freezes the transaction id for all pages, whether modified or not, so that all the current rows can be seen as old (or in the past), making them visible for all new transactions.
PostgreSQL reserves a special txid, FrozenTransactionId, that is always considered older than every normal txid. This id is inserted during the VACUUM FREEZE process in the t_infomask column of the tuple header.
Enough said, let's see it in action. In order to demonstrate it, we need to first create more dead tuples, as the ones we had before have been cleaned by VACUUM and VACUUM FULL:
--MSSQLTips.com update test_vacuum set descrizione='test_vacuum 24' where (id % 2) = 0;
Now, run VACUUM with option FREEZE:
--MSSQLTips.com vacuum freeze test_vacuum;
Take a look at the size and memory page:
--MSSQLTips.com
select pg_size_pretty
(pg_relation_size('test_vacuum'));
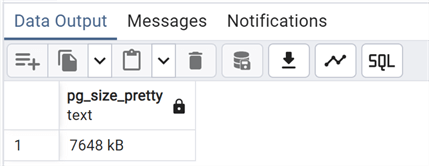
Since we have not issued a VACUUM FULL command, the size of the table is bigger. The disk space has not been recovered. Only the dead tuples have been deleted, like in a normal VACUUM.
But, let's look again at the table page, adding the infomask column this time:
--MSSQLTips.com
SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid, t_infomask
FROM heap_page_items(get_raw_page('test_vacuum', 0));
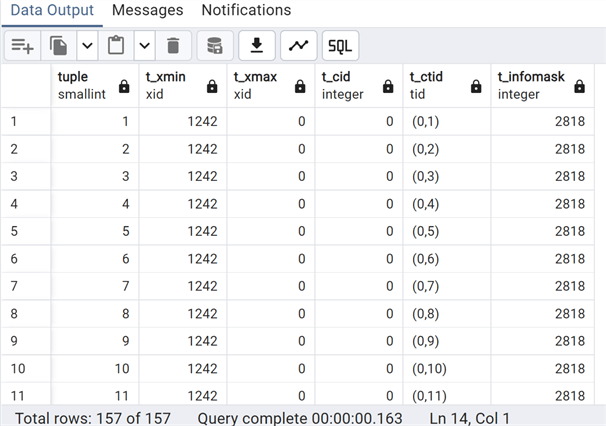
We can now see that we have a separate id indicating these tuples (rows) are frozen and visible.
A few Important notes on FREEZE:
- Aggressive freezing is always performed when the table is rewritten, so this option is redundant when FULL is specified. When we run a VACUUM FULL, we also do a FREEZE.
- vacuum_freeze_min_age parameter controls when a row will be frozen.
- vacuum_freeze_table_age parameter controls when the whole table must be scanned.
We will talk more in-depth about these last two parameters in the second part of this tip.
So, now that we've learned there is a tool that prevents a potentially catastrophic issue, we need to learn how to use it! Do we need to manually perform this VACUUM FREEZE every given time period on all tables in our databases?
Fortunately, no, we have an automation tool called AUTOVACUUM enabled by default on all tables!
But this is a story for the next chapter of this tip!
Next Steps
In this tip, we learned what VACUUM is and its most important features and uses, as well as some theory on how PostgreSQL memorizes data pages and performs concurrency by default.
A future article will discuss what AUTOVACUUM is and how to tune it, and the option ANALYZE. So stay tuned!!
As always, here are some links to the official documentation:






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-10-11
