By: Jared Westover | Updated: 2024-11-13 | Comments (1) | Related: > TSQL
Problem
Even though I enjoy using SQL Server, there are some things other tools do better. For example, calculating moving averages or rolling totals is often simpler in tools like Power BI or Excel. That's because Microsoft built those programs with that functionality in mind. Recently, we had to optimize a complex moving average query written for SQL Server 2008R2. Surprise! There's no built-in function for moving averages in SQL Server. But don't worry; I'll show you how to make it work.
Solution
In this article, I'll explore two methods for creating a moving average in SQL Server. We'll start with the older and less performant way, which happens to be what was in production. Who knows, maybe you're still using an outdated version of SQL Server. Then, we'll look at a modern way to use windowing functions and how adding an index makes all the difference. By the end of this article, you'll be ready to tackle that moving average the next time someone needs it, and you can't simply say, "Use Excel."
Moving Average
This article is not about statistics; I couldn't do that topic justice. Yet, allow me to try to define the moving average. The most common definition is an average calculated for data points that smooth out a trend over time. You hear about moving averages in the stock market, for example, comparing the 50-day to the 30-day moving averages or whatever magical formula traders use to get rich.
Moving Average in Excel
Creating a moving average in Excel is easy. Imagine for a moment that Bob is starting a weight loss journey in the new year. Bob wants to track his weight over time to ensure he's making progress. He decides to weigh himself every day, knowing that his weight fluctuates from day to day. One day, he went to a lovely cafe and ordered too much—it was hard to say no to tasty food. The next morning arrives, and the scale is up a pound. But Bob isn't worried because he uses a 7-day moving average to track his weight.
In the screenshot below, Bob tracked his weight in Excel and added a column for the 7-day average. To get the formula, you take the average of his weight from day one down to day seven (cells B2:B8). Then, drag that formula to the bottom. The weight entry on January 21 was almost 2 pounds higher than the day before; however, the moving average stayed the same, a better indicator of long-term success.
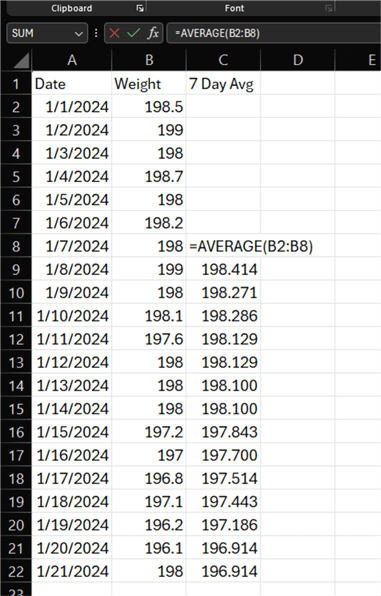
Since we've defined the usefulness of a moving average, let's create a large dataset in which 600 people track their weight for five years. By analyzing weight data over five years, we'll use the moving average to detect long-term trends with a larger sample size.
Demo Dataset
I'll create a single table called BigWeightTracker with the script below and insert around 1.3 million rows into it. Also, let's add a helpful index. This index follows Itzik Ben-Gan's partitioning, ordering, and covering (POC) recommendation.
-- mssqltips.com
DROP TABLE IF EXISTS dbo.BigWeightTracker;
GO
CREATE TABLE dbo.BigWeightTracker
(
Id INT IDENTITY(1, 1) NOT NULL,
UserId INT NOT NULL,
Pounds Decimal(10, 2) NOT NULL,
DateRecorded DATE NOT NULL,
CONSTRAINT PK_BigWeightTracker_Id
PRIMARY KEY CLUSTERED (Id)
);
GO
DECLARE @StartDate DATE = '2018-01-01';
DECLARE @EndDate DATE = '2023-12-31';
WITH Users
AS (SELECT TOP 600
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS UserId
FROM sys.all_columns AS s1
),
Dates
AS (SELECT @StartDate AS Date
UNION ALL
SELECT DATEADD(DAY, 1, Date) AS Date
FROM Dates
WHERE Date < @EndDate
)
INSERT INTO dbo.BigWeightTracker
(
UserId,
DateRecorded,
Pounds
)
SELECT u.UserId,
d.Date,
(ABS(CHECKSUM(NEWID()) % (220 - 170 + 1)) + 170) AS Weight
FROM Users u
CROSS JOIN Dates d
OPTION (MAXRECURSION 0);
GO
DROP INDEX IF EXISTS IX_BigWeightTracker_Average ON dbo.BigWeightTracker;
CREATE NONCLUSTERED INDEX IX_BigWeightTracker_Average
ON dbo.BigWeightTracker
(
UserId,
DateRecorded ASC
)
INCLUDE (Pounds);
GO
The Old Way
In all fairness, someone wrote the original query several years ago. At that time, SQL Server didn't have all the fancy analytical functions available in a modern version like SQL Server 2019 or 2022. Below is an example of the original query. There's a lot more complexity going on with the actual query, but I want to focus on the moving average.
-- mssqltips.com
SET STATISTICS TIME, IO ON;
SELECT t1.UserId,
t1.DateRecorded,
t1.Pounds,
CASE
WHEN COUNT(t2.Pounds) < 7 THEN
NULL
ELSE
AVG(t2.Pounds)
END AS [7DayMovingAverage]
FROM dbo.BigWeightTracker t1
INNER JOIN dbo.BigWeightTracker t2
ON t2.DateRecorded
BETWEEN DATEADD(DAY, -6, t1.DateRecorded) AND t1.DateRecorded
AND t1.UserId = t2.UserId
GROUP BY t1.UserId,
t1.DateRecorded,
t1.Pounds
ORDER BY t1.UserId,
t1.DateRecorded;
SET STATISTICS TIME, IO OFF;
GO
This method uses a self-join on the BigWeightTracker table, returning the 7-day average. When we run the query, SQL Server returns the data in about four seconds. Since I don't want to see early results on the 7-day average column, I'll return NULL until the count reaches seven. Also, I'm enabling time and I/O feedback to help us determine our current performance.
I've included the number of logical reads, scans, and execution times below. As you can see, the table's join predicate isn't very efficient because it scans the table for every row SQL returns.
- Scan Count: 1,314,609
- Logical Reads: 3,981,941
- CPU Time: 4.8s
- Elapsed Time: 3.6s

Another way to write this query is to use a correlated subquery. Based on the performance metrics, this approach still results in a high number of logical reads and scans with about the same execution time.
-- mssqltips.com
SET STATISTICS TIME, IO ON;
SELECT t1.UserId,
t1.DateRecorded,
t1.Pounds,
(
SELECT CASE
WHEN COUNT(t2.Pounds) < 7 THEN
NULL
ELSE
AVG(t2.Pounds)
END
FROM BigWeightTracker t2
WHERE t2.DateRecorded
BETWEEN DATEADD(DAY, -6, t1.DateRecorded) AND t1.DateRecorded
AND t1.UserId = t2.UserId
) AS [7DayMovingAverage]
FROM dbo.BigWeightTracker t1
ORDER BY t1.UserId,
t1.DateRecorded;
SET STATISTICS TIME, IO OFF;

Neither of these approaches is efficient because SQL Server has to scan the table repeatedly. Also, the queries can be hard to read and maintain unless your T-SQL skills are above average. So, let's try to find a simpler way.
The Simplified Way
Microsoft introduced window functions in SQL Server 2005, but added new and improved options in SQL Server 2012. Why did we wait so long to update the old code? It's a fair question, and I can give a reason: updating code is time-consuming and comes with a risk-to-reward ratio for testing and the potential for new bugs. The older method worked until the data grew larger, and we needed to update it for other reasons.
A few of my favorite functions to use with windowing include:
- ROW_NUMBER: Adds a sequential number to each row.
- RANK: Ranks rows and leaves a gap when there are ties.
- DENSE_RANK: Like RANK but doesn't leave gaps when there are ties.
The OVER clause allows you to define your window frame. Additionally, you can tell the frame how many prior rows to include with the ROWS PRECEDING argument. Before we build the 7-day average, let's look at a simple example.
-- mssqltips.com
DECLARE @Simple_Test AS TABLE (Id INT);
INSERT INTO @Simple_Test
(
Id
)
VALUES (1),
(2),
(3),
(4),
(5);
SELECT Id,
SUM(Id) OVER (ORDER BY Id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS Value
FROM @Simple_Test;
GO
Output:
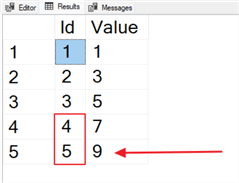
With the code above, I'm returning two columns. The first displays the IDs 1 through 5. My second column, Value, returns the sum of the current row and the previous one. For example, in the screenshot above, row 5 has a value of 9, which is simply adding 4 + 5. To achieve this, I'm using the argument ROWS BETWEEN 1 PRECEDING AND CURRENT ROW. People often don't bother with the additional arguments, even if they've used windowing functions for years. However, as you'll see below, they come in handy.
Now for the grand reveal. The following code is an example of our new query.
-- mssqltips.com
SET STATISTICS TIME, IO ON;
SELECT t1.UserId,
t1.DateRecorded,
t1.Pounds,
CASE
WHEN ROW_NUMBER() OVER (PARTITION BY t1.UserId ORDER BY t1.DateRecorded) > 6 THEN
AVG(t1.Pounds) OVER (PARTITION BY t1.UserId
ORDER BY t1.DateRecorded
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
)
ELSE
NULL
END AS [7DayMovingAverage]
FROM dbo.BigWeightTracker t1
ORDER BY t1.UserId,
t1.DateRecorded;
SET STATISTICS TIME, IO OFF;
I've included the statistics below, which show an improvement over the previous methods:
- Scan Count: 1
- Logical Reads: 4250
- CPU Time: 1s
- Elapsed Time: 2.9s

Check out the drop in logical reads. Also, this query runs faster. With a larger dataset, this method outperforms older code. Plus, the code is easier to read and maintain, especially for someone who doesn't work with T-SQL daily. In my opinion, adding more calculations, like a 14-day moving average, is easier. Some people don't like windowing functions for various reasons, but in this case, the pros outweigh the cons.
Clean Up
If you're done playing around, don't forget to drop the table using the code below.
-- mssqltips.com DROP TABLE IF EXISTS dbo.BigWeightTracker; GO
Key Points
- Windowing functions are an excellent substitute for use cases like those discussed in this article, where you might otherwise perform self-joins or correlated subqueries to pull back the results.
- Tools like Excel and Power BI are better for performing calculations like the one above, but there are situations where you need to crunch the numbers with T-SQL.
- Remember the additional arguments you can supply the next time you use a windowing function, like ROWS BETWEEN n PRECEDING AND CURRENT ROW.
Next Steps
- My favorite and most used windowing function is ROW_NUMBER. To learn more about it, read "SQL Server ROW_NUMBER for Ranking Rows."
- Koen Verbeeck assembled a tutorial on using windowing functions called "SQL Server T-SQL Window Functions Tutorial." It's well worth the time investment to improve your skills.
- For an in-depth look at moving averages in SQL Server, check out Rick Dobson's article, "Weighted vs Simple Moving Average with SQL Server T-SQL Code."






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-11-13
