By: Kenneth A. Omorodion | Updated: 2024-11-14 | Comments (2) | Related: More > Data Warehousing
Problem
In modern data warehousing, how we handle updates to dimension tables is crucial. There are several approaches; but the decision often comes down to two primary strategies: Slowly Changing Dimensions (SCD) Type 2 and overwriting tables. Each has its own benefits, use cases, and trade-offs. This tip will explore the two methods and why SCD Type 2 is often a better option in many data warehouse scenarios.
Solution
Let's begin by understanding these approaches in some detail.
Overwriting Tables
Overwriting a table in a data warehouse is a straightforward process, where you simply replace the existing table with a new version. This method is often used when historical changes don't need to be tracked, and the focus is on maintaining only the most recent data. This approach is commonly applied to transactional data or static dimensions that rarely change.
Let's consider a scenario where you are loading data into a Dim_Products table in a data warehouse from a staging area or a Lakehouse (Silver zone). Here's how you could overwrite this table using SQL.
Steps Involved
- Load the data from the source.
- Overwrite the dimension table with the latest records by first truncating the table and then inserting new records to the table.
The code below show an example of how to achieve this using SQL:
-- Step 1: Truncate the existing Dim_Products table in the data warehouse
TRUNCATE TABLE Dim_Products;
-- Step 2: Load the latest data from the Silver Lakehouse
-- Assuming we're using Azure Synapse or any SQL-based data warehouse
INSERT INTO Dim_Products
SELECT
ProductKey,
ProductName,
Category,
Subcategory,
StandardCost,
Color
FROM
OPENROWSET(
BULK ‘Your ABFS path’, -- Include your ABFS path for source here
FORMAT = 'CSV',
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
FIRSTROW = 2 -- Skips the header row
) AS SilverProducts;
The code above is an example of how you can overwrite an existing table using SQL. If you were doing this in PySpark on Microsoft Fabric, the process would look like the code below:
from pyspark.sql import SparkSession
# Step 1: Initialize Spark session
spark = SparkSession.builder.appName("DataWarehouseLoad").getOrCreate()
# Step 2: Load data from Silver Lakehouse (CSV in ADLS)
silver_lakehouse_path = "abfss://befbb657-dc2e-43c5-8c01-936cdc139ab4@onelake.dfs.fabric.microsoft.com/7ea00bde-a742-481b-9f21-2cb51f2311e1/Tables/Products"
df_products = spark.read.csv (silver_lakehouse_path, header=True, inferSchema=True)
# Step 3: Overwrite the existing Dim_Products table in the Data Warehouse
df_products.write.mode("overwrite").saveAsTable("Dim_Products")
Assumptions
- You have a Silver Lakehouse (or your staging) with a Products table that contains the most up-to-date product information.
- You want to overwrite the existing Dim_Products table in your data warehouse with the latest data from the Silver Lakehouse.
- The Products table contains columns like ProductKey, ProductName, Category, Subcategory, and Color.
- You are using Azure Synapse or Microsoft Fabric for this.
When to Use the Overwriting Approach
- Static Dimensions: If the dimension data doesn't change frequently or if you don't need to track changes over time, overwriting is sufficient.
- Transactional Data: In cases where you only need the latest version of the data, such as current balances or the most recent status of orders, overwriting can be considered.
- High-Volume Data: Overwriting works well when you want to avoid the complexity and overhead of maintaining history, especially for large datasets.
Drawbacks of Overwriting
- No Historical Data: You lose any previous state or version of the data. This is problematic if you later need to analyse how the data has changed over time.
- Lack of Audit Trail: There's no way to track changes, which might be important for compliance or regulatory reasons.
SCD Type 2
Slowly Changing Dimensions Type 2 (SCD Type 2), on the other hand, is designed to track historical changes in the data by creating multiple versions of records. Instead of overwriting, new rows are inserted when an update occurs, and the previous version is marked as inactive.
It is one of the most popular and widely used techniques for managing dimension tables in data warehouses. This popularity stems from its ability to preserve historical data, which is crucial for many business applications, including business intelligence, trend analysis, compliance, and auditing.
Why SCD Type 2 is Popular
- Preserves Historical Data: SCD Type 2 keeps a full history of changes, making it invaluable for understanding how entities like products, customers, or suppliers evolve over time.
- Supports Point-in-Time Analysis: With SCD Type 2, you can analyze data as it existed at a specific point in time, which is essential for tracking trends, performance, and historical changes.
- Compliance and Auditing: Many industries, such as finance and healthcare, require a complete historical record of changes for auditing purposes. SCD Type 2 ensures that no data is lost, making it highly reliable for compliance needs.
- Widely Supported by Tools: Modern data platforms, such as Microsoft Fabric, Azure Synapse, Snowflake, and AWS Redshift, have built-in support for implementing SCD Type 2, making it a go-to choice for enterprises using these platforms.
Because SCD Type 2 strikes a balance between complexity and functionality - by providing a full audit trail without the extreme complexity of some advanced SCD types - it has become a popular choice for dimension management in most data warehouses. So, how does it compare to other SCD types available? I have summarized what the other SCD approaches are meant to achieve for clarification:
- SCD Type 1 (Overwrite): Only stores the current version of data, making it less useful for historical analysis but simpler to implement. It's just simply the overwrite approach mentioned earlier.
- SCD Type 3: Stores only the previous and current version of data, which limits the depth of historical analysis.
- SCD Type 4 & 6: More complex to implement and typically used in specific scenarios but not as common as SCD Type 2.
Steps Involved in SCD Type 2 Implementation
- Check for existing records.
- Insert new rows when changes occur, maintaining the older data for historical purposes.
- Use flags and dates to track the validity of each record.
Let's assume we have a Dim_Product table in our data warehouse, and we want to track changes to product information over time. The table structure below is used to create the table.
CREATE TABLE Dim_Products (
ProductKey INT NOT NULL,
ProductName VARCHAR(100),
StandardCost DECIMAL(18,2),
EffectiveDate DATE,
ExpiryDate DATE,
CurrentFlag BIT
);
ALTER TABLE Dim_Products
ADD CONSTRAINT PK_Dim_Products PRIMARY KEY NONCLUSTERED (ProductKey) NOT ENFORCED;
The descriptions below help to dissect the table structure and can be adapted in other scenarios for dimension tables where SCD Type 2 is to be implemented:
- ProductKey: Unique identifier for the product.
- ProductName: Name of the product.
- StandardCost: Cost of the product.
- EffectiveDate: The date when the record became effective.
- ExpiryDate: The date when the record was replaced by a new version (if applicable).
- CurrentFlag: Indicates whether the record is the current version (1 for current, 0 for historical).
To initially load the Dim_Product table, I will use the code below. In your case, this would obviously be different as you would not be expected to hard-code the values you are entering into your table. If you need more information on how to load tables in a Lakehouse or Warehouse in MS Fabric, see this article: Dimensional modeling in Microsoft Fabric Warehouse: Load tables.
INSERT INTO Dim_Products (ProductKey, ProductName, StandardCost, EffectiveDate, ExpiryDate, CurrentFlag) VALUES (1, 'Product A', 100.00, '2023-01-01', '9999-12-31', 1);
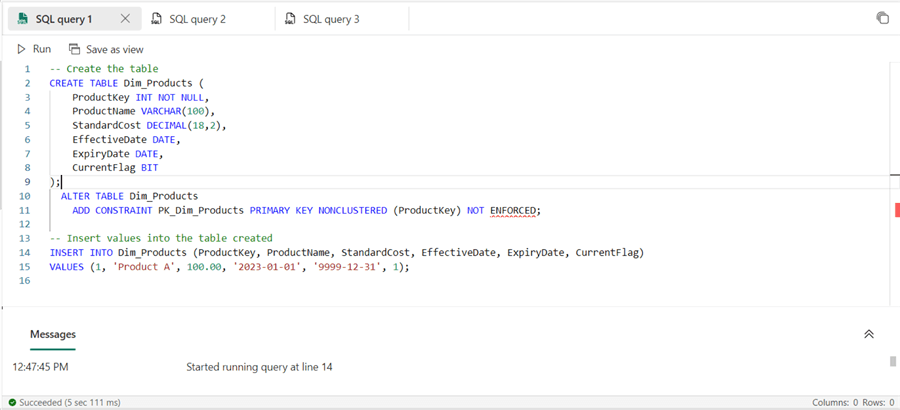
The image below shows both SQL codes in a Microsoft Fabric warehouse.
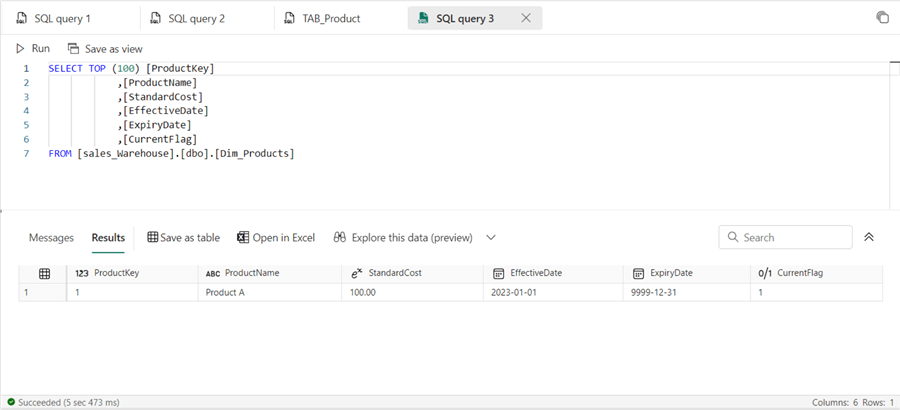
When you run the query to return all columns in the current state of the table, you get the output below.
Suppose the StandardCost for 'Product A' changes to 110.00 on '2024-01-01'. To handle this using SCD Type 2, you would:
- Update the current record to set its ExpiryDate and CurrentFlag.
- Insert a new record with the updated information.
The SQL code below can be used for updating the table in this example under the following conditions:
- You do not expect there to be high concurrency (many users accessing and modifying at the same time).
- There is no need to be extra logical in handling the versioning and history, especially setting the EffectiveDate, ExpiryDate, and CurrentFlag.
-- Step 1: Update the existing record
UPDATE Dim_Products
SET ExpiryDate = GETDATE(),
CurrentFlag = 0
WHERE ProductKey = 1 AND CurrentFlag = 1;
-- Step 2: Insert the new record
INSERT INTO Dim_Products (ProductKey, ProductName, StandardCost, EffectiveDate, ExpiryDate, CurrentFlag)
VALUES (1, 'Product A', 110.00, GETDATE(), '9999-12-31', 1;
The resulting values in the Dim_Products table should look like the image below.
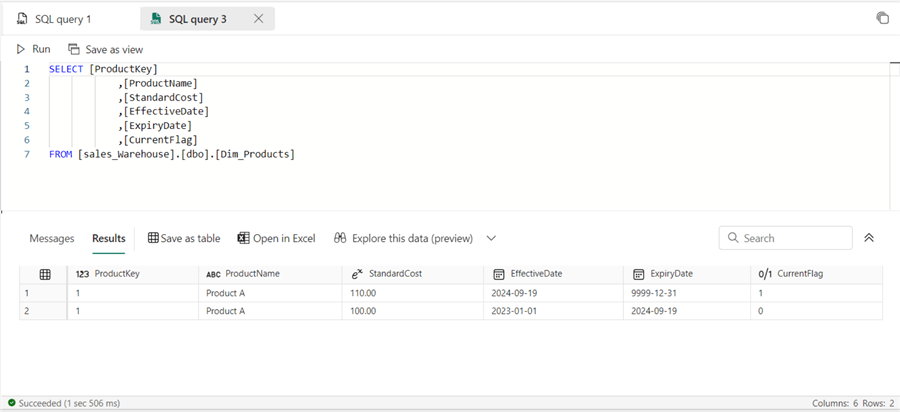
This approach maintains a complete history of changes, which can be useful for reporting and analysis. However, when you need a robust, automated, and large-scale approach that should handle both updates and inserts in one atomic operation, which is particularly useful for managing SCD Type 2, you may need to adjust the code slightly. This is particularly necessary under the following assumptions:
- High Concurrency and Isolation: if you expect the rate of your uploads and access to be high, this helps to avoid potential issues where a row could be inserted or updated by multiple processes.
- Versioning and History: If your dimension table is a SCD Type 2 table, you need to carefully handle the history, especially setting the EffectiveDate, ExpiryDate, and CurrentFlag in a way that keeps previous versions of the record accurate. For instance, use a datetime instead of date data formats.
Key Considerations on Using SCD Type 2
Some considerations you might need to carefully plan and confirm, depending on the environment you are using to develop your warehouse, may include:
- Auto-identity Columns: If your table has an identity column (like an auto-incrementing key), you need to ensure the ProductKey is not auto-generated when manually inserting the key value.
- Primary Keys or Uniqueness Constraints: If your ProductKey is part of a unique or primary key constraint, inserting the same ProductKey might lead to constraint violations if a record with ProductKey = 1 already exists. You might want to insert with a new ProductKey, if necessary.
The MERGE statement allows you to handle both updates and inserts in one atomic operation, which is particularly useful for managing SCD Type 2.
Below is a code example you can adapt to help manage and implement SCD Type 2 on your dimension tables in Azure Synapse.
MERGE INTO Dim_Products AS target
USING (
SELECT
ProductKey,
ProductName,
StandardCost,
GETDATE() AS EffectiveDate, -- Using today's date as the EffectiveDate
'9999-12-31' AS ExpiryDate,
1 AS CurrentFlag
FROM OPENROWSET(
BULK 'abfss://{storage_account}@onelake.dfs.fabric.microsoft.com/{lakehouse_path}/{table}',
FORMAT = 'PARQUET'
) AS source
) AS source
ON target.ProductKey = source.ProductKey AND target.CurrentFlag = 1
-- Step 1: Update the existing record (set ExpiryDate and CurrentFlag to expire the current record)
WHEN MATCHED THEN
UPDATE
SET target.ExpiryDate = GETDATE(), -- Use today's date for the ExpiryDate of the old record
target.CurrentFlag = 0
-- Step 2: Insert the new record (with updated StandardCost and dates)
WHEN NOT MATCHED BY TARGET THEN
INSERT (ProductKey, ProductName, StandardCost, EffectiveDate, ExpiryDate, CurrentFlag)
VALUES (source.ProductKey, source.ProductName, source.StandardCost, GETDATE(), '9999-12-31', 1);
If your environment is Microsoft Fabric, this code might not work (OPENROWSET is not supported in Microsoft Fabric at the time of writing). Instead, you can adapt your code based on the one below for Microsoft Fabric.
MERGE INTO Dim_Product AS target
USING (
SELECT
ProductKey,
ProductName,
StandardCost,
GETDATE() AS EffectiveDate, -- Using today's date as the EffectiveDate
'9999-12-31' AS ExpiryDate,
1 AS CurrentFlag
FROM Staging_Product -- Assuming this table holds data loaded from the Silver Lakehouse
) AS source
ON target.ProductKey = source.ProductKey AND target.CurrentFlag = 1
-- Step 1: Update the existing record (set ExpiryDate and CurrentFlag to expire the current record)
WHEN MATCHED THEN
UPDATE
SET target.ExpiryDate = GETDATE(), -- Use today's date for the ExpiryDate of the old record
target.CurrentFlag = 0
-- Step 2: Insert the new record (with updated StandardCost and dates)
WHEN NOT MATCHED BY TARGET THEN
INSERT (ProductKey, ProductName, StandardCost, EffectiveDate, ExpiryDate, CurrentFlag)
VALUES (source.ProductKey, source.ProductName, source.StandardCost, GETDATE(), '9999-12-31', 1);
When to Use SCD Type 2
- Tracking Changes Over Time: If your business requires knowing how a product, customer, or order has changed over time, SCD Type 2 is ideal.
- Compliance and Auditing: In industries where regulatory compliance requires a record of historical changes (like healthcare or finance), SCD Type 2 is often a must.
- Business Intelligence: If your organization conducts trend analysis, cohort analysis, or predictive modeling, having historical data is crucial.
- Performance: Modern databases, such as Azure Synapse and Microsoft Fabric, are optimized to handle large datasets. With proper indexing and partitioning, the performance overhead of SCD Type 2 can be minimized.
Drawbacks of Using SCD Type 2
- Complexity: SCD Type 2 introduces more complexity. It requires additional logic to manage updates, track changes, and maintain a proper historical record.
- Storage Requirements: Each change results in a new row, so SCD Type 2 consumes more storage space over time.
- Performance Overhead: More rows mean more data to scan during queries, potentially slowing down performance, if not properly indexed.
Conclusion
While overwriting tables is a straightforward and resource-efficient approach, it sacrifices the ability to track historical changes - something that's often vital in modern data warehousing and business intelligence. SCD Type 2, though more complex, preserves historical data, supports point-in-time analysis, and ensures regulatory compliance.
In most data warehouse environments, especially those dealing with dimension tables like Products, SCD Type 2 is the best practice because it provides flexibility and depth for future analytics.
Ultimately, the choice depends on the specific requirements of your business. If historical data isn't critical, overwriting might be suitable. However, for most businesses that need data integrity, history tracking, and rich analytics, SCD Type 2 is the preferred and recommended method.
Next Steps
- Read more about SCD types.
- To learn more about concepts in data warehousing, you might find these articles handy.
- Read more about dimensional modelling in Fabric warehouse.






About the author
 Kenneth A. Omorodion is a Business Intelligence Developer with over eight years of experience. He holds both a bachelor’s and master’s degree (Middlesex University in London). Kenneth has the MCSA, Microsoft Data Analyst - Power BI and Azure Fundamentals certifications. Kenneth is a Microsoft Certified Trainer and has delivered corporate training on Power BI, SQL Server, Excel and SSRS.
Kenneth A. Omorodion is a Business Intelligence Developer with over eight years of experience. He holds both a bachelor’s and master’s degree (Middlesex University in London). Kenneth has the MCSA, Microsoft Data Analyst - Power BI and Azure Fundamentals certifications. Kenneth is a Microsoft Certified Trainer and has delivered corporate training on Power BI, SQL Server, Excel and SSRS.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-11-14
