By: Rick Dobson | Updated: 2024-11-22 | Comments | Related: > Database Design
Problem
Please provide T-SQL examples that illustrate how to create and use GUID values in SQL Server. Also, show how to analyze GUID values with T-SQL. Include a couple of examples on how to detect duplicate values in a column of GUIDs. Additionally, discuss how duplicate values can exist in columns of globally unique values.
Solution
GUIDs are instances of universally unique values (within the limits of their specifications which are exceedingly extensive in scope). As of the writing of this tip, the most recent specification for the generation of GUID values is RFC 9532, which obsoletes an earlier standard for universally unique values (RFC 4122). Both standards were issued by the Internet Engineering Task Force. There are several different specifications for GUIDs. Version 4 of either standard is the one to which Microsoft SQL Server adheres.
A GUID is a sequence of 128 bits in SQL Server with a uniqueidentifier data type. Another more common way of representing GUIDs is as 16 bytes. Because a single byte contains eight bits and 16 x 8 equals 128, you can grasp how the byte and bit formats are alternative and equivalent representations for GUIDs.
The overwhelming majority of GUID bits, or more precisely 122 bits, are randomly assigned. The randomization rules focus on returning unique GUIDs. A Wikipedia article on universal unique identifiers with the aid of a probabilistic analysis indicates that "the probability to find a duplicate within 103 trillion version-4 UUIDs is one in a billion."
The objective of this tip is to present and describe several T-SQL examples for creating, using, and analyzing GUIDs. This tip includes a T-SQL code sample for empirically analyzing the uniqueness of GUID values. The current tip therefore offers a framework that is easy to run and interpret for assessing the uniqueness of GUIDs in your own SQL Server applications.
Appending GUIDs to SQL Server Results Sets
The first T-SQL example in this tip generates four results sets:
- Result Set 1: Populates rows in a temp table (#temp_sdc). The temp table stores data for two stock ticker symbols (SPY and QQQ). There are three columns in the temp table for this tip – namely, symbol, date, and close for the close price at the end of a trading day. In case you do not typically analyze stock price data, the results set could as easily be about product sales, product inventories, inches of rainfall, or daily low and high temperatures.
- Result Set 2: Displays the top and bottom five rows ordered by date for the SPY symbol. The results set is generated by two select statements with a union operator between them.
- Result Set 3: Invokes the NEWID() function to append a column of GUIDs to the other columns from the second results set.
- Result Set 4: Uses a NEWID() function (again) to append a column of GUIDs to a results set for symbol, date, and close prices for the QQQ symbol.
Here is the T-SQL script for generating the four results sets described above. Note: Reviewing the script, you will discover that it is copiously commented, and the comments identify the code for generating each of the four results sets. Note: The initial script statement references a database named DataScience. You can replace this database name with any other one that is convenient for you because the default database is never explicitly referenced in the script.
use DataScience
declare @Symbol_SPY varchar(8) = 'SPY'
,@Symbol_QQQ varchar(8) = 'QQQ'
-- create a fresh temp table (#temp_sdc) with rows
-- for August 2024 dates for
-- each of two different symbols (QQQ, SPY)
-- that are sorted alphabetical by symbol
-- and by date within symbol
drop table if exists #temp_sdc
-- for first results set
select
[Symbol]
,[date]
,[close]
into #temp_sdc
from [SecurityTradingAnalytics].[dbo].[PriceAndVolumeDataFromYahooFinanceAcrossSymbols]
order by Symbol asc, date
-- optionally display the contents of #temp_sdc
-- select * from #temp_sdc
--------------------------------------------------------------------
-- for second results set
-- display just the top and bottom 5 rows for the SPY symbol
-- in ascending order by date
select top 5 * from #temp_sdc where symbol = @Symbol_SPY
union
-- display just the top 5 rows and bottom 5 rows in asc date order
-- for the SPY symbol
select * from
(select top 5 *
from #temp_sdc
where symbol = @Symbol_SPY
order by date desc) bot_5
order by date asc
--------------------------------------------------------------------
-- for third results set
-- append myGuids column values to top and bottom 5 displayed rows
-- for @Symbol_SPY
select top 5 *, NEWID() myGuids
from #temp_sdc where symbol = @Symbol_SPY
union
-- display just the top 5 rows and bottom 5 rows in asc date order
-- for the SPY symbol
select *, NEWID() myGuids from
(select top 5 *
from #temp_sdc
where symbol = @Symbol_SPY
order by date desc) bot_5
order by date asc
--------------------------------------------------------------------
-- for fourth results set
-- append myGuids column values to top and bottom 5 displayed rows
-- for @Symbol_QQQ
select top 5 *, NEWID() myGuids
from #temp_sdc where symbol = @Symbol_QQQ
union
-- display just the top 5 rows and bottom 5 rows in asc date order
-- for the SPY symbol
select *, NEWID() myGuids from
(select top 5 *
from #temp_sdc
where symbol = @Symbol_QQQ
order by date desc) bot_5
order by date asc
You can learn more about the operations of the preceding script by examining its outputs.
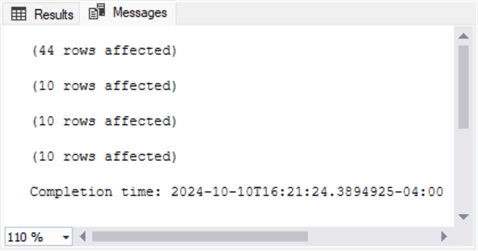
Here is the output from the Messages tab. There are four messages – one for each of the results sets:
- The first message is for the first results set. This message says the results set has 44 rows. As it turns out, there are 22 trading days in August 2024. Because the results set contains data for two ticker symbols, there are 44 trading days in the results set.
- Each of the remaining three messages are, respectively, for the second, third, and fourth results sets. Because the code for each of these results sets returns data for the first and last five rows, these messages indicate there are 10 rows per results set.
Here is the output from the Results tab:
- Notice there are only three results sets in the tab. This is because the first results set generated by preceding script populates the #temp_sdc temp table, which becomes a data source for the remaining three results sets.
- In contrast, the second, third, and fourth results sets appear in the Results
tab:
- The first results set in the following tab is for the second results set generated by the script. This result set has no GUIDs. All 10 rows for this results set are for the SPY ticker symbol.
- The code for the remaining two results sets that appear in the tab below are, respectively, for the SPY and QQQ ticker symbols. Two select statements interoperate with each other via a union operator in the preceding script to send the first and last five rows of a results set to the Results tab.
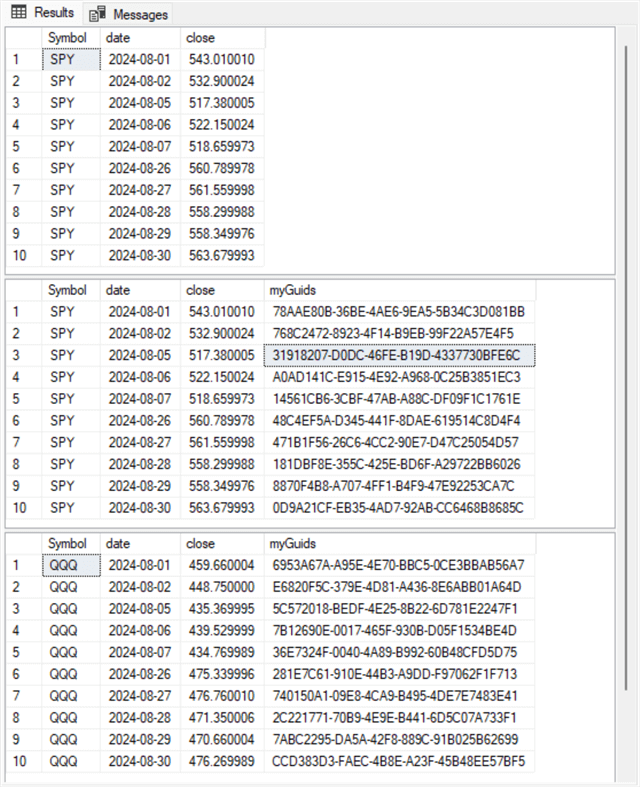
Now may be a good time to dive a little bit more deeply into the structure of GUIDs. Recall that they have a length of 16 bytes, but the GUID columns below have 32 characters per row (not including dashes). GUIDs can represent each byte with two hexadecimal characters (0 through 9 and A through F) – one for the first four bits and a second for the last four bits in a byte. These two sets of four-byte fields are sometimes called nibbles. In other words, there are 32 nibbles in a GUID – two for each of the 16 bytes in a GUID.
Inserting and Maintaining New GUIDs in a Table
The sample for this section has two main parts. First, this section demonstrates how to add GUIDs by default when inserting fresh records into a table. After new records are added to a table, the records may need to be managed. For example, a beginner DBA may be updating field values in a table and inadvertently modify a valid GUID so that it collides with another valid GUID. Alternatively, a bad actor may intentionally corrupt one or more valid GUIDs so they collide with other valid GUIDs. This section also demonstrates how to detect the collision of GUIDs in a table and remedy any collisions. A collision occurs when the GUIDs for two or more table rows are identical.
The script for the first part of this section begins with a use statement. Note: You can replace the DataScience name at the top of the script with whatever other name is convenient to use in your development environment.
The following script shows how to create a default GUID value for each new record entered into the dbo.persons table. The first line of code in the create table statement specifies the person_id column to have a uniqueidentifier data type. The default NEWID() function text at the end of the line generates by default a GUID to be inserted for each new table row. The PK_dbo_persons constraint in the last line of the create table statement adds an extra level of protection for the GUIDs by designating the person_id column as a primary key for the table. The protection follows from the fact that the constraint must be dropped prior to modifying any GUIDs in person_id column. The remaining lines of code in the create table expression designates additional columns for storing data.
A set of three insert statements follows the create table statement. These insert statements add three rows to the dbo.persons table. The script excerpt ends with a select statement to echo the values added to the dbo.persons table.
Use DataScience
drop table if exists dbo.persons
-- create a table with a default uniqueidentifier type primary key
create table dbo.persons(
person_id uniqueidentifier default newid()
,first_name nvarchar(20) not null
,last_name nvarchar(20) not null
,email nvarchar(60)
,phone nvarchar(12)
,constraint PK_dbo_persons primary key (person_id)
);
-- insert a three records into dbo.persons
insert into dbo.persons (first_name, last_name, email, phone)
values ('Michael', 'Williams', 'michaelwilliams', '111-111-1111')
insert into dbo.persons (first_name, last_name, email)
values ('John', 'Brown', '[email protected]');
insert into dbo.persons (first_name, last_name, phone)
values ('Jane','Smith', '333-333-3333');
-- first echo of records
select * from dbo.persons
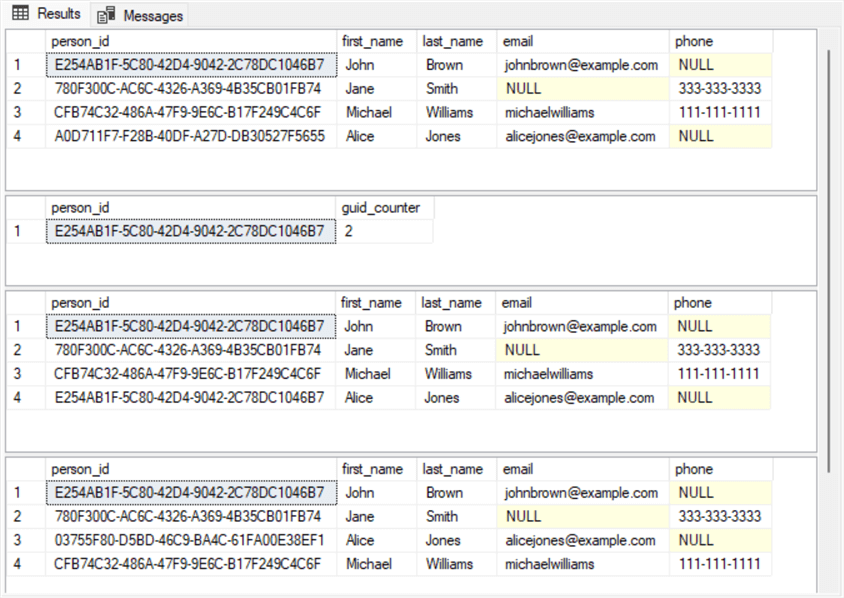
Here is the echo generated by the preceding script.

The next script illustrates how a bad actor or an inexperienced DBA may cause the collision of GUIDs. A table with one or more collisions defeats the uniqueness of GUIDs as primary key values for a table.
- The script starts by adding a fresh new row for Alice Jones to the dbo.persons table. The outcome of this step is shown by the following select statement that displays the dbo.persons table with a new fourth row.
- Next, the PK_dbo_persons constraint is dropped from the dbo.persons table. This step permits a bad actor or an inexperienced DBA to create the collision of the GUID for the Alice Jones row with the row for another person in the table.
- Next, an update statement revises the GUID for the Alice Jones row so that it matches the GUID for the John Brown row.
- After the update statement completes, a select statement searches the dbo.persons table for rows with identical GUIDs.
- Next, a select statement shows the revised dbo.persons table with the corrupted person_id value for Alice Jones that matches the person_id value for John Brown. The select statement displays the count of GUIDs that identify two or more people.
- The following select statement shows the revised dbo.persons table with Alice Jones having the same GUID as the one for John Brown.
- The remaining statements in the following script fix the corruption and display by assigning a fresh new GUID to Alice Jones, adding a new primary key constraint to the dbo.persons table, and displaying the fixed dbo.persons table.
Use DataScience
-- add a new record for Alice Jones
insert into dbo.persons (first_name, last_name, email)
values ('Alice', 'Jones', '[email protected]');
-- second echo of records
select * from dbo.persons
-- drop the PK constraint for the dbo.persons table
alter table dbo.persons
drop constraint PK_dbo_persons;
-- update the person_id value for Alice Jones
-- to match the person_id value for John Brown
update dbo.persons
set person_id =
(select person_id from dbo.persons where first_name = 'John' and last_name = 'Brown')
where first_name = 'Alice' and last_name = 'Jones'
-- return listing of rows that are not unique
select person_id, count(person_id) guid_counter
from dbo.persons [Guid_id values that are not unique]
group by person_id
having count(person_id) > 1
-- third echo of records
select * from dbo.persons
-- assign Alice Jones a new Guid
update dbo.persons
set person_id = newid()
where first_name = 'Alice' and last_name = 'Jones'
-- restore the PK constraint for dbo.persons
alter table dbo.persons
add constraint PK_dbo_persons primary key (person_id)
-- fourth echo of records
select * from dbo.persons
Here are the results sets returned by the preceding scripts. These results sets let you trace the entry of a new row, the corruption of the GUID for the new row, and the restoration of the new row with a fresh GUID that does not collide with the GUID for another row.
Searching for GUIDs in Larger Tables
The main objective of this section is to illustrate two different approaches for verifying if GUIDs are unique within sets of 100,000, 1,000,000, and 10,000,000 records. This tip provides empirical evidence that assesses the suitability of GUIDs to serve as primary keys for large tables because uniqueness is an important property for primary keys. A secondary objective of this tip section is to present performance results for each approach for assessing the uniqueness of GUID values in large tables.
One approach relies on a while loop because it is easy to understand – particularly for developers coming from a procedural programming background. The other approach is oriented to the skills of a DBA because it relies on cross joins of three copies of a built-in sys view (sys.all_objects) with itself, a rownumber() function for the results set from the joins, a clustered index, adding GUID values after instead of before the prior processing steps, as well as the maxdop option to control the maximum number of processors supporting a query.
The following script shows the T-SQL for generating a table of GUIDs (dbo.for_Guid_counts) with a while loop:
- After the use statement for declaring a default database for the script, the T-SQL creates a fresh copy of the dbo.for_Guid_counts table.
- The @currentrow_id and @max_row_number local variables control the flow
of the while loop:
- @currentrow_id indicates the current row number and
- @max_row_number holds the value of the maximum row number
- Each pass through the while loop:
- Inserts a GUID to the GUID_id column of the dbo.for_Guid_counts table, and
- Increments the value of @currentrow by one.
- The last section of the script searches for GUID_id column values that are not unique and displays a report of these GUIDs if any.
Use DataScience
drop table if exists dbo.for_Guid_counts
-- create a table with a default uniqueidentifier type primary key
create table dbo.for_Guid_counts(
GUID_id uniqueidentifier default newid() primary key
);
-- insert @max_row_number GUID values into GUID_id column of dbo.for_Guid_counts
declare @currentrow_id int = 1, @max_row_number int;
set @max_row_number = 100000;
while @currentrow_id <= @max_row_number
begin
insert into dbo.for_Guid_counts (GUID_id)
values (NEWID());
set @currentrow_id = @currentrow_id + 1;
end;
-- return listing of rows that are not unique
select @max_row_number [Total number of rows]
select myGuids, count(myGuids) guid_counter
from dbo.nGuids [Guid_id values that are not unique]
group by myGuids
having count(myGuids) > 1
Here is the script for the DBA approach to generating GUIDs for large tables:
- The script starts by setting the value of the @max_row_number local variable
to 100,000.
- The value of the @max_row_number local variable is changed to 100,000, 1,000,000, or 10,000,000, depending on the size of the table that is being evaluated in a script run.
- This same feature is available for use with the while loop script.
- Next, conditional drop table statements remove any prior versions of the
dbo.Numbers and dbo.nGuids tables.
- The dbo.Numbers table is populated based on the row_numbers function for the cross joins of three copies (s1, s2, and s3) of the sys.all_objects view with itself.
- The select statement populating the dbo.Numbers table uses the maxdop option in an attempt to optimize the query.
- The results set from the select statement is ordered by the row_number function.
- The maxdop 4 option controls the maximum number of processors used by the query.
- The dbo.nGuids table is populated by the next select statement. The GUIDs are added to the results set in this step.
- Finally, the script ends by searching for non-unique GUIDs in dbo.nGuids.
use DataScience declare @max_row_number int; set @max_row_number = 100000; -- cleanup prior versions of tables drop table if exists dbo.Numbers; drop table if exists dbo.nGuids; -- cross join sys.all_objects to itself multiple times -- return top @max_row_number from the results set -- use maxdop option of 4 to explicitly reference 4 cores select top (@max_row_number) n = convert(int, row_number() OVER (ORDER BY s1.[object_id])) into dbo.Numbers from sys.all_objects s1 CROSS JOIN sys.all_objects s2 cross join sys.all_objects s3 option (maxdop 4); create unique clustered index n on dbo.Numbers(n) -- append myGuids to dbo.Numbers rows and save as nGuids table select *, NEWID() myGuids into dbo.nGuids from dbo.Numbers -- return listing of rows that are not unique select @max_row_number [Total number of rows] select myGuids, count(myGuids) guid_counter from dbo.nGuids [Guid_id values that are not unique] group by myGuids having count(myGuids) > 1
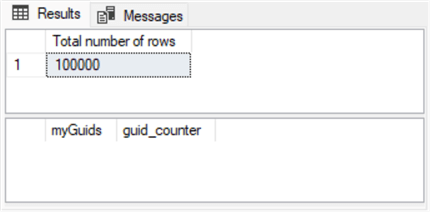
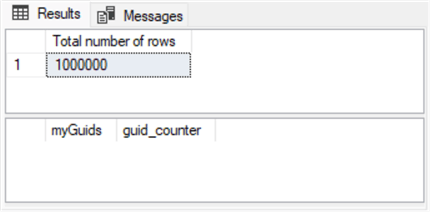
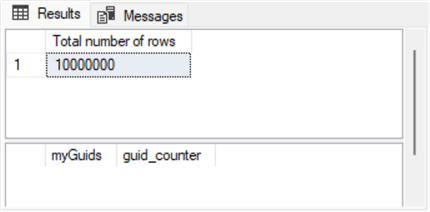
The search for duplicate GUIDs yielded the same outcome for all three table sizes of 100,000, 1,000,000, and 10,000,000 rows for both search approaches. The following table shows three Results tabs from the cross joins approach.
- The number of rows searched appears in the top panel, and the number of GUIDs with duplicate values appears in the second panel for a results set.
- If there are no duplicate GUIDs for the Total number of rows displayed in the top panel, then the bottom panel will have no rows listed.
- Notice there are no rows listed in the bottom panel for any of the three sample sizes.
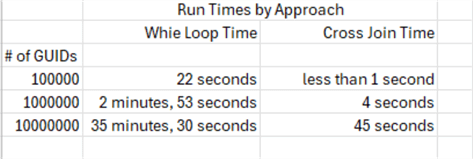
Here is a summary of the query run times from both approaches for all three sample sizes. Each query was run twice, and the run times are the average across both times.
- The search query times grow for both approaches as the sample size goes from 100,000 through 10,000,000.
- The difference in run times for the While loop approach versus the cross
join approach grows as the sample size gets larger.
- The run time difference by approach is slightly less than 22 seconds for a sample size of 100,000.
- This difference grows to around 2 minutes 49 seconds for sample size of 1,000,000.
- For the final sample size of 10,000,000, the difference grows to 34 minutes 45 seconds.
- Based on these results, the cross join approach delivers substantial time
savings for testing either:
- A single sample of 10,000,000 or more.
- Many samples of 1,000,000.
Next Steps
Add the NEWID() function to associate GUIDs with your SQL Server results sets and table rows for the databases that you manage. Adapt the T-SQL code illustrated at multiple points in this tip to assess whether there are any duplicate GUIDs in any of your test runs. Also, avoid using while loops when generating GUIDs for large results sets or tables. Instead, use cross joins for the sys.all_objects view with a row_number function as demonstrated in the preceding tip section because the cross join approach can run dramatically faster than the while loop approach.
Several prior MSSQLTips.com articles examine various aspects of GUIDs. Three references are listed below. By referring to these prior tips, you can discover potential use cases and issues pertaining to the use of GUIDs within SQL Server projects.
- What is a GUID in SQL Server
- Auto generated SQL Server keys with the uniqueidentifier or IDENTITY
- SQL Server Performance Comparison INT versus GUID






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-11-22
