By: Armando Prato
Overview
We've discussed a primary key and a clustered index for tables as well as constraints to safeguard the data. What about additional indexes? We need to get data out of the database quickly. How should we define them?
Explanation
Defining indexes is part art and part science. Any indexes you will want to define in addition to the clustered index will be nonclustered indexes. They are also stored as B tree structures but the leaf level stores the index keys plus, tucked away, will be the clustered index key. This is important to note since any data that can't be satisfied solely by the nonclustered index will jump over (a key lookup) to the clustered index using this tucked away key to get any remaining data required. The nonclustered indexes you define will largely be based on the data queries your applications will issue.
Any defined primary key and UNIQUE constraints automatically get a unique index assigned by SQL Server. Foreign Keys do not get an index automatically defined. That said, it's prudent to index foreign keys since it's likely queries will be issued that join a parent table to a child table. Whenever I create a foreign key, I manually create an index for the column(s) involved in the constraint.
Also look to avoid creating duplicated indexes in your database. For instance, the AdventureWorks Person.Person table has a non-clustered index by LastName, FirstName, and MiddleName. If separate queries require searching by (LastName, FirstName) and by (LastName, FirstName, MiddleName), you don't need to specify two separate indexes. The single existing index will cover both cases. This leads to less index maintenance overhead when inserting/deleting/updating data in the table. It should be noted that if a UNIQUE or Primary Key constraint were defined on (LastName, FirstName, MiddleName), a second index would not need to be defined since SQL Server will give you an index by virtue of creating the constraint!
In this example, we look at the structure of non-clustered index IX_Person_LastName_FirstName_MiddleName in the Person.Person table of AdventureWorks.
This indexes defined for this table are as follows:

Using the undocumented DBCC PAGE command, we can drill into index structures to examine the makeup of non-clustered indexes within clustered tables. In this case, let's examine a random sample of some data within the index.
dbcc traceon(3604)
dbcc page('AdventureWorks2008R2',1,1745,3) with tableresults
go
This yields the following:
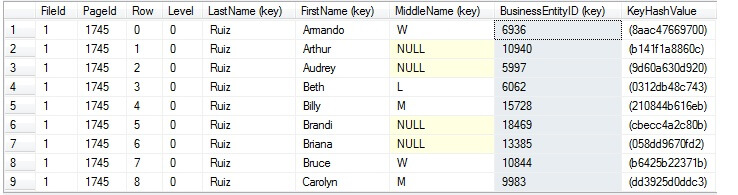
As can be seen, the clustered index key (BusinessEntityID) is stored with each non-clustered index key. This comes into play when the resultset to satisfy a query is outside the scope of the columns within the index.
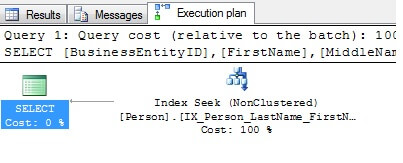
The following query returns 1 row and it's execution plan shows that the existing index can satisfy the resultset.
select BusinessEntityID, FirstName, MiddleName, LastName from Person.Person where LastName = 'Allison'
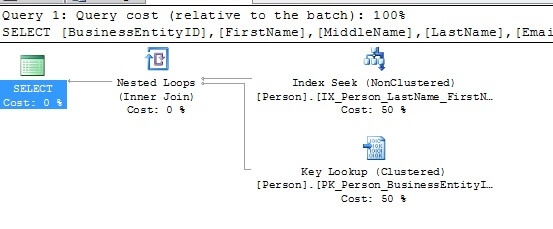
Changing the query to include a column not within the index shows a Key Lookup operation. In this case, the clustered index key on BusinessEntityID is used to lookup the additional EmailPromotion column from the Person.Person table to satisfy the resultset.
select BusinessEntityID, FirstName, MiddleName, LastName, EmailPromotion from Person.Person where LastName = 'Allison'
Additional Information
- Improve SQL Server Performance with Covering Index Enhancements
- Avoid Index Redundancy in SQL Server Tables
- Understanding SQL Server Indexing
Last Update: 9/10/2011
