By: Ben Snaidero
Overview
Using a derived table in place of the IN predicate when we are aggregating data allows us to only have to process certain table records once therefore reducing the amount of resources required to execute a query.
Explanation
When we use the IN predicate we first have to process the data in our subquery then we are processing a lot of the same data again (depending on the WHERE clause) in our main query. If we can use a derived table to do most of the work we can avoid the double processing of data. Before we take a look at an example to illustrate this point we'll need to add an index to our Parent table so the results are not skewed by having to do a table scan. Here is the code to create this index.
CREATE NONCLUSTERED INDEX idxParentID_IntDataColumnParentID ON [dbo].[Parent] ([IntDataColumn],[ParentID]) -- cleanup statements DROP INDEX Parent.idxParentID_IntDataColumnParentID
Let's look at a query that uses the IN predicate to return the second largest value from a table. One way to do this would be as follows.
SELECT MIN(IntDataColumn)
FROM [dbo].[Parent]
WHERE ParentID IN (SELECT TOP 2 ParentID
FROM [dbo].[Parent]
ORDER BY IntDataColumn DESC)Just by looking at the query we can see we are going to access the Parent table twice to get this result. From the explain plan we can see that the second access does use an index seek so it might not be too much of an issue.
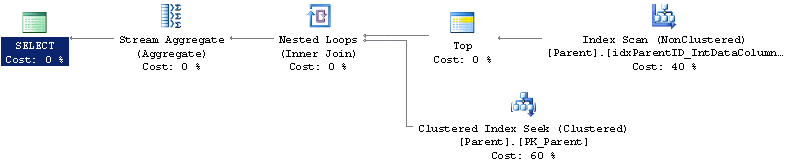
Now let's rewrite this query and use a derived table to generate the result. Here is that SQL statement.
SELECT MIN(IntDataColumn)
FROM (SELECT TOP 2 IntDataColumn
FROM [dbo].[Parent]
ORDER BY IntDataColumn DESC) AS ANotice that from the query we only reference the Parent table once and the explain plan confirms that we no longer have to access the Parent table a second time, even with an index.

We can also see from the SQL Profiler results below that we do get some significant resource savings even for this simple query. Although the CPU and total duration were the same, we only had to perform 2 reads as opposed to the 8 required by the original query.
| CPU | Reads | Writes | Duration | |
|---|---|---|---|---|
| IN Predicate | 0 | 8 | 0 | 0 |
| Derived Table | 0 | 2 | 0 | 0 |
Additional Information
Last Update: 2/17/2014
