By: Ben Snaidero
Overview
There are two different storage types for tables in SQL Server, Heap tables and Clustered tables. Heap tables are tables that do not have a clustered index defined on them and Clustered tables are tables that have a clustered index defined. There are few reasons why it's recommended that most if not all tables have a clustered index defined.
Explanation
The first benefit to having a clustered index defined on a column is it saves a lookup when you query the based on the indexed column because the data is part of the index. It's because of this that it's recommended that you create your clustered indexes on columns that are most heavily used in WHERE clauses not necessarily the primary key column if it's not used that often to access the table. For example, if you had an OrderDetail table where the primary key was an identity column OrderDetailID but most queries accessed the table using the OrderID column then it would be better if the clustered index was on the OrderID column as this would produce more row level locks when the tables is accessed. Let's take a look at the simple query of the Parent table. First we'll have to create an index on one of the secondary columns and also remove the clustered index from this table. Here are the SQL statements that do both of these operations.
ALTER TABLE dbo.Parent DROP CONSTRAINT PK_Parent ALTER TABLE dbo.Parent ADD CONSTRAINT PK_Parent PRIMARY KEY NONCLUSTERED (ParentID) CREATE NONCLUSTERED INDEX idxParent_IntDataColumn ON [dbo].[Parent] ([IntDataColumn])
And here is our query of the Parent table.
SELECT * FROM [dbo].[Parent] P WHERE P.IntDataColumn=32433
Looking at the explain plan for this query we can see that the SQL Optimizer has to perform a lookup on the Heap table after finding the record in the index.
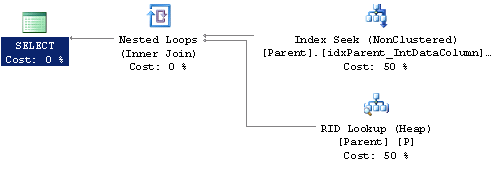
Now let's recreate this index on the InDataColumn as a clustered index. Here is the SQL statements.
DROP INDEX Parent.idxParent_IntDataColumn CREATE CLUSTERED INDEX idxParent_IntDataColumn ON [dbo].[Parent] ([IntDataColumn])
Checking the explain plan now we can see that the SQL optimizer now just has to do an index seek.

Looking at the SQL Profiler results for this query we can confirm that having a clustered index does in fact allow SQL Server to execute the query using less resources, specifically the number of reads it has to perform to process the data.
| Table Type | CPU | Reads | Writes | Duration |
|---|---|---|---|---|
| Heap | 0 | 7 | 0 | 6 |
| Clustered | 0 | 3 | 0 | 0 |
The second benefit to having a clustered index on a table is it provides a way to reorganize the table data when it becomes fragmented. Let's run an update on our table so it becomes a little bit fragmented. We'll also put the table back to its original state with only the clustered primary key to make it easier to view the results. Here are the SQL statements to perform these tasks.
DROP INDEX Parent.idxParent_IntDataColumn
ALTER TABLE dbo.Parent DROP CONSTRAINT PK_Parent
ALTER TABLE dbo.Parent ADD CONSTRAINT
PK_Parent PRIMARY KEY CLUSTERED (ParentID)
DECLARE @x BIGINT
DECLARE @y BIGINT
SELECT @x=1
WHILE @x < 100000
BEGIN
UPDATE [dbo].[Parent] SET VarcharDataColumn='TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST
TESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTESTTEST'+
CAST(@x AS VARCHAR)
WHERE ParentID=@x
SELECT @x=@x+1
ENDWe can double check the fragmentation level of our table using the following query.
SELECT index_level,avg_fragmentation_in_percent,fragment_count,avg_fragment_size_in_pages,page_count FROM sys.dm_db_index_physical_stats(DB_ID(N'master'), OBJECT_ID(N'dbo.Parent'), NULL, NULL , 'DETAILED')
We can see from the following results after executing the update above we have some fragmentation in our table.
| index_level | avg_fragmentation_in_percent | fragment_count | avg_fragment_size_in_pages | page_count |
|---|---|---|---|---|
| 0 | 14.3 | 3507 | 6.9 | 24394 |
| 1 | 5.3 | 111 | 1.0 | 112 |
| 2 | 0 | 1 | 1 | 1 |
Now if our table did not have a clustered index we would have to create a temporary table and reload the data into this table, then recreate all of the indexes, then drop the original table and rename the temporary table. We would also have to have disabled any referential integrity constraints before doing any of this and add them back when we were done. All of these tasks would also require downtime for the application. Since our table does have a clustered index we can simply rebuild this index to reorganize the table data. Doing a regular rebuild would require some downtime but we would avoid all the extra steps required by the reload. If we don't have the luxury of being able to take our application offline to do maintenance the SQL Server does provide the ability to perform this task online, while the table is being accessed. Here is the SQL statement to do an online rebuild (note: simply remove the WITH condition or replace ON with OFF to perform a regular offline rebuild).
ALTER INDEX PK_Parent ON Parent REBUILD WITH (ONLINE=ON)
After running the index rebuild statement we can again check the fragmentation in our table using the sys.dm_db_index_physical_stats query from earlier.
| index_level | avg_fragmentation_in_percent | fragment_count | avg_fragment_size_in_pages | page_count |
|---|---|---|---|---|
| 0 | 0.01 | 18 | 694.4 | 12500 |
| 1 | 0 | 4 | 7.5 | 30 |
| 2 | 0 | 1 | 1 | 1 |
Additional Information
- Find a better candidate for your SQL Server clustered indexes
- Rebuilding indexes using the ONLINE option
Last Update: 2/17/2014
