By: Brady Upton
Where do I start? The transaction log is an integral part of SQL Server. Every database has a transaction log that is stored within the log file that is separate from the data file. A transaction log basically records all database modifications. When a user issues an INSERT, for example, it is logged in the transaction log. This enables the database to roll back or restore the transaction if a failure were to occur and prevents data corruption. For example, let’s say Sue is using an application and inserts 2000 rows of data. While SQL Server is processing this data let’s say someone pulls the plug on the server. (Again, this is just an example, I hope nobody would actually do this). Because the INSERT statement was writing to the transaction log and it knows a failure occurred it will roll back the statement. If this wasn’t put in place, could you imagine having to sift through the data to see how many rows it inserted and then change the code to insert the remaining rows? Or even better, what if the application inserted random columns in no order and you had to determine what data was inserted and what data was left out? This could take forever!
Log entries are sequential in nature. The transaction log is split up into small chunks called virtual log files, which we will discuss in a later section. When a virtual log file is full, transactions automatically move to the next virtual log file. As long as the log records at the beginning of the transaction log have been truncated when logging reaches the end of the log, it will circle back around to the start and will overwrite what was there before:
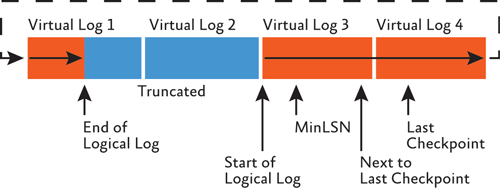
Source: Technet
Last Update: 3/25/2014
