By: Atif Shehzad | Updated: 2009-02-20 | Comments (3) | Related: > Performance Tuning
Problem
SCHEMA BINDING is commonly used with SQL Server objects like views and User Defined Functions (UDF). The main benefit of SCHEMA BINDING is to avoid any accidental drop or change of an object that is referenced by other objects. A User Defined Function (UDF) may or may not access any underlying database objects, but in this tip we show how using SCHEMA BINDING with a UDF can improve performance even if there are no underlying objects.
Solution
In order to continue with this example, we will create two UDFs that will not use any underlying objects. One UDF will use schema binding and the other will not use schema binding. To test both UDFs independently we will also create two sample tables to work with. Both UDFs simply apply a mathematical formula on the sample tables.
The UDFs and tables are created through script # 1.
Script # 1: Create UDFs and tables and populate the tables
/* Two functions will be created Two tables will be created Both tables will be populated with 100K rows each */ ------------------------------- CREATE BOTH USER DEFINED FUNCTIONS -- Create non schema binded UDF USE AdventureWorks GO CREATE FUNCTION NonSchemaBinded(@INPUT INT) RETURNS INT BEGIN RETURN @INPUT * 2 + 50 END GO -- Create schema binded UDF USE AdventureWorks GO CREATE FUNCTION SchemaBinded(@INPUT INT) RETURNS INT WITH SCHEMABINDING BEGIN RETURN @INPUT * 2 + 50 END GO ------------------------------- CREATE BOTH TABLES -- Create table for non schema binded UDF USE AdventureWorks GO CREATE TABLE forNonSB(col1 INT) -- Create Table CREATE INDEX IndexOnNonSB -- Create index on table ON forNonSB(col1 ASC) GO -- Create table for schema binded UDF USE AdventureWorks GO CREATE TABLE forSB(col1 INT) -- Create Table CREATE INDEX IndesxOnSB -- Create index on table ON forSB(col1 ASC) GO --------------------------------- POPULATE BOTH TABLES --Populate table for non schema binded UDF with 100K rows USE AdventureWorks GO SET NOCOUNT ON -- Set NoCount ON GO DECLARE @COUNT INT -- Declare variable for loop SET @COUNT = 1 -- Initialize the variable WHILE (@COUNT < 100000) -- Start loop here BEGIN INSERT INTO forNonSB VALUES (@COUNT) -- Insert values SET @COUNT = @COUNT +1 -- Increment loop END -- End of loop GO SET NOCOUNT OFF -- Set NoCount OFF GO --Populate table for schema binded UDF with 100K rows USE AdventureWorks GO SET NOCOUNT ON -- Set NoCount ON GO DECLARE @COUNT INT -- Declare variable for loop SET @COUNT = 1 -- Initialize the variable WHILE (@COUNT < 100000) BEGIN INSERT INTO forSB VALUES (@COUNT) -- Insert values SET @COUNT = @COUNT +1 -- Increment loop END -- End of loop GO SET NOCOUNT OFF -- Set NoCount OFF GO
Query Stats
Now we have two User Defined Functions (UDF) 'NonSchemaBinded(int)' and 'SchemaBinded(int)' along with two populated sample tables 'forNonSB' and 'forSB'.
The UDF 'NonSchemaBinded(int)' is not schema bound while the UDF 'SchemaBinded(int)' is schema bound.
In script 2 we will run both functions on a column of their respective tables and the resource consumption of both will be analyzed. Do not forget to include the actual execution plan through SSMS for this script when you run it.
Script # 2: Use both UDF
----------------------- start update for schemabinded UDF
SELECT CONVERT(VARCHAR,GETDATE(),113)
AS 'Update with schema bound UDF starts at following time'
GO
USE adventureworks
GO
UPDATE forSB
SET col1 = col1 + 5
WHERE dbo.SchemaBinded(col1) > 10
GO
SELECT CONVERT(VARCHAR,GETDATE(),113)
AS 'Update with schema bound UDF ends at following time'
GO
-- Check that UDF accesses system catalogs
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.SchemaBinded'), 'SYSTEMDATAACCESS')
AS 'Check that UDF dbo.SchemaBinded accesses system catalogs'
-- Check that UDF accesses any user data
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.SchemaBinded'), 'USERDATAACCESS')
AS 'Check that UDF dbo.SchemaBinded accesses any user data'
GO
--==========================================================
------------------------ start update for non schemabinded UDF
SELECT CONVERT(VARCHAR,GETDATE(),113)
AS 'Update with non-schema bound UDF starts at following time'
GO
USE adventureworks
GO
UPDATE forNonSB
SET col1 = col1 + 5
WHERE dbo.NonSchemaBinded(col1) > 10
GO
SELECT CONVERT(VARCHAR,GETDATE(),113)
AS 'Update with non-schema bound UDF ends at following time'
GO
-- Check that UDF accesses system catalogs
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NonSchemaBinded'), 'SYSTEMDATAACCESS')
AS 'Check that UDF dbo.NonSchemaBinded accesses system catalogs'
-- Check that UDF accesses any user data
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NonSchemaBinded'), 'USERDATAACCESS')
AS 'Check that UDF dbo.NonSchemaBinded accesses any user data'
GO
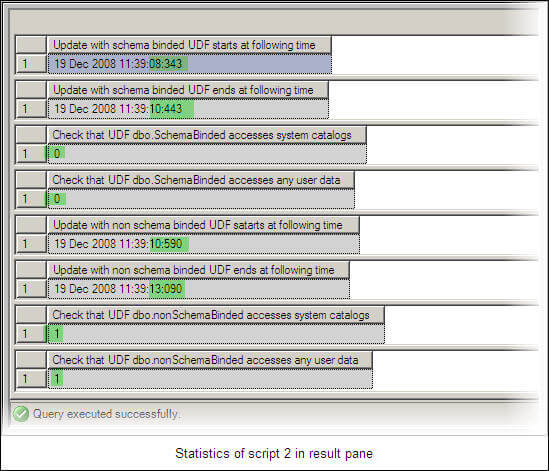
As a result of executing both UDFs through the above script on their related tables, we get the following statistics:
Execution Plans
For the above statistics the start and end times have been highlighted. Depending upon hardware resources of your system these timings may be different for you.
The highlighted time statistics indicate that the schema bound UDF provides better performance than the non-schema bound UDF. Also two derived properties of SQL Server 2005 have been used to show if the UDF is accessing system or user data. For our schema bound UDF 'SchemaBinded(int)' we can see that both properties indicate system catalog and user data is not accessed. While for the non-schema bound UDF 'NonSchemaBinded(int)' both properties indicate that system catalog and user data is accessed causing additional over head.
As a result of executing both UDFs through the above script on their related tables, we get the following execution plans::
Schema Bound UDF


Non-Schema Bound UDF


For the actual query plans we can compare that the operator Table Spool is present for the non-schema bound UDF while it is not there for the schema bound UDF. Also the filter cost for the non-schema bound UDF is more than that of the schema bound.
The Table Spool operator scans the input and places a copy of each row in a hidden spool table (stored in the tempdb database and existing only for the lifetime of the query). SQL Server 2005 uses the Table Spool operator for the non-schema bound UDF to ensure that no DDL change will break the ongoing operation of the UDF. If the UDF is non-schema bound then the query optimizer will generate the spool operator. In the case of a UDF where it is not accessing any base table or view, such spooling will never be utilized. So in the case of the schema bound UDF this spool operation does not occur and performance is increased.
The Compute Scalar operator evaluates an expression to produce a computed scalar value. This may then be returned to the user, referenced elsewhere in the query, or both. This operator is also eliminated for the UDF that is schema bound.
Query Cache
Another option to monitor the performance of both UDFs is to look at the SQL Server cache. By using the view sys.dm_exec_query_stats, we can get aggregate performance statistics for cached query plans.
Run the following script to get the plan cache statistics for both UDFs.
Script # 3: Get aggregate performance statistics of both UDF in plan cache
SELECT total_logical_reads, total_logical_writes,
total_physical_reads, total_worker_time,
total_elapsed_time, sys.dm_exec_sql_text.TEXT
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE total_logical_reads <> 0
AND total_logical_writes <> 0
ORDER BY (total_logical_reads + total_logical_writes) DESC
GO
The following result is generated for script # 3.
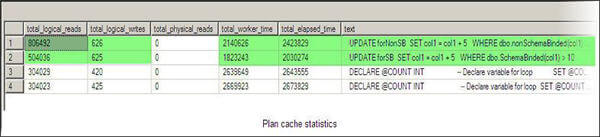
Description of columns generated through script # 3 are as follows:
| Column Name | Description |
| [total_logical_reads] | is total number of logical reads performed by executions of this plan since it was compiled. |
| [total_logical_writes] | is total number of logical writes performed by executions of this plan since it was compiled. |
| [total_physical_reads] | is total number of physical reads performed by executions of this plan since it was compiled. We have zero for both of our UDF. |
| [total_worker_time] | is total amount of CPU time, in microseconds, that was consumed by executions of this plan since it was compiled. |
| [total_elapsed_time] | is total elapsed time, in microseconds, for completed executions of this plan. |
Both UDFs are created and used equal number of times. The above stats for the plan cache show that the schema bound UDF is more efficient than the non-schema bound UDF.
Let us also consider the case when a single value is provided as parameter to both of our UDFs. The following script provides a single int value to the schema bound and non-schema bound UDF.
Script 4: Provide single parameter to both UDF
USE AdventureWorks
GO
-- Provide parameter to schemabinded UDF
SELECT dbo.SchemaBinded(60) as ValueFromSB
GO
-- Check that UDF accesses system catalogs
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.SchemaBinded'), 'SYSTEMDATAACCESS')
AS 'Check that UDF dbo.SchemaBinded accesses system catalogs'
-- Check that UDF accesses any user data
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.SchemaBinded'), 'USERDATAACCESS')
AS 'Check that UDF dbo.SchemaBinded accesses any user data'
GO
-- Provide parameter to non schemabinded UDF
SELECT dbo.NonSchemaBinded(60) as ValueFromNonSB
GO
-- Check that UDF accesses system catalogs
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NonSchemaBinded'), 'SYSTEMDATAACCESS')
AS 'Check that UDF dbo.nonSchemaBinded accesses system catalogs'
-- Check that UDF accesses any user data
SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NonSchemaBinded'), 'USERDATAACCESS')
AS 'Check that UDF dbo.nonSchemaBinded accesses any user data'
GOFollowing is the actual execution plan generated for script # 4.
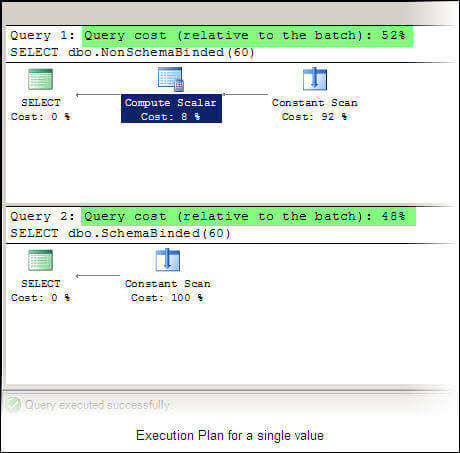
We can see that the query cost for the non-schema bound UDF is more than the schema bound UDF. An additional operator 'Compute Scalar' is used in the case of the non-schema bound UDF with a cost of about 8%. The Compute Scalar operator evaluates an expression to produce a computed scalar value. This may then be returned to the user, referenced elsewhere in the query, or both. This operator is also eliminated for a UDF that is schema bound and thus performance is increased. Also in the result pane you can see that the schema bound UDF did not access any system catalog or user data, while the non-schema bound UDF did.
To clean up and remove the created UDFs and tables use the following script.
Script 5: Remove the created table and UDF
USE AdventureWorks GO -- Drop both tables DROP TABLE forSB, forNonSB GO -- Drop both user defined functions DROP FUNCTION dbo.SchemaBinded, dbo.NonSchemaBinded GO
Next Steps
We saw that applying SCHEMA BINDING to a UDF increases the performance. So analyze your databases for all such UDFs which do not access any underlying database objects and alter each UDF to include schema binding. No consideration for base objects is required in this case as no base object is being referenced for these UDFs.






About the author
 Atif Shehzad is a passionate SQL Server DBA, technical reviewer and article author.
Atif Shehzad is a passionate SQL Server DBA, technical reviewer and article author.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2009-02-20
