By: Aaron Bertrand | Updated: 2012-04-12 | Comments (9) | Related: 1 | 2 | 3 | 4 | > Database Design
Problem
In my last tip, I shared some ideas for determining if you should consider breaking up the e-mail addresses you're storing, even putting the domain names in a separate table. I performed storage and timing comparisons for working with 10,000 unique e-mail addresses, but I completely ignored data compression. I wanted to revisit the same test case and apply data compression to the tables and see how that impacted the outcome.
Solution
If you remember, we were storing contacts in three different ways, and now we're just going to use page compression on each table.
The original table:
CREATE TABLE dbo.Contacts_Original
(
EmailAddress VARCHAR(320) PRIMARY KEY
) WITH (DATA_COMPRESSION = PAGE);A table where we split the local part from the domain name:
CREATE TABLE dbo.Contacts_Split
(
LocalPart VARCHAR(64) NOT NULL,
DomainName VARCHAR(255) NOT NULL,
PRIMARY KEY (DomainName, LocalPart)
) WITH (DATA_COMPRESSION = PAGE);
And finally, a two-table solution where domain names were stored in their own separate table:
CREATE TABLE dbo.EmailDomains
(
DomainID INT IDENTITY(1,1) PRIMARY KEY,
DomainName VARCHAR(255) NOT NULL UNIQUE
) WITH (DATA_COMPRESSION = PAGE);
CREATE TABLE dbo.Contacts_DomainFK
(
DomainID INT NOT NULL FOREIGN KEY
REFERENCES dbo.EmailDomains(DomainID),
LocalPart VARCHAR(64),
PRIMARY KEY (DomainID, LocalPart)
) WITH (DATA_COMPRESSION = PAGE);Again we'll run these tables through the same three tests:
- Inserting 10,000 new e-mail addresses
- Counting the number of addresses in use by a specific domain
- Updating all the addresses for one domain to use a new domain
Again we can use the same query to generate 10,000 unique e-mail addresses:
;WITH x(n,i,rn) AS
(
SELECT TOP (10000) LOWER(s1.name),
ABS(s2.[object_id] % 10),
ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_objects AS s2
),
y(i, localpart, domain) AS
(
SELECT i, n+RTRIM(rn),
CASE WHEN i < =2 THEN 'gmail.com'
WHEN i <= 4 THEN 'hotmail.com'
WHEN i = 5 THEN 'aol.com'
WHEN i = 6 THEN 'compuserve.net'
WHEN i = 7 THEN 'mci.com'
WHEN i = 8 THEN 'hotmail.co.uk'
ELSE RTRIM(rn) + '.com'
END
FROM x
)
SELECT DISTINCT y.localpart, y.domain, email = y.localpart + '@' + y.domain
FROM x INNER JOIN y ON x.i = y.i;So with that in place, we could proceed with our tests.
Creating 10,000 contact rows
Again, we have the same three stored procedures, one to handle each case: the original table, the split table, and the domain FK tables.
CREATE PROCEDURE dbo.Contact_Create_Original
@EmailAddress VARCHAR(320)
AS
BEGIN
SET NOCOUNT ON;
MERGE INTO dbo.Contacts_Original AS c
USING (SELECT EmailAddress = @EmailAddress) AS p
ON c.EmailAddress = p.EmailAddress
WHEN NOT MATCHED THEN
INSERT (EmailAddress) VALUES(p.EmailAddress);
END
GO
CREATE PROCEDURE dbo.Contact_Create_Split
@LocalPart VARCHAR(64),
@DomainName VARCHAR(255)
AS
BEGIN
SET NOCOUNT ON;
MERGE INTO dbo.Contacts_Split AS c
USING
(
SELECT LocalPart = @LocalPart,
DomainName = @DomainName
) AS p
ON c.LocalPart = p.LocalPart
AND c.DomainName = p.DomainName
WHEN NOT MATCHED THEN
INSERT (LocalPart, DomainName) VALUES(p.LocalPart, p.DomainName);
END
GO
CREATE PROCEDURE dbo.Contact_Create_DomainFK
@LocalPart VARCHAR(64),
@DomainName VARCHAR(255)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @DomainID INT;
SELECT @DomainID = DomainID
FROM dbo.EmailDomains
WHERE DomainName = @DomainName;
IF @DomainID IS NULL
BEGIN
INSERT dbo.EmailDomains(DomainName) SELECT @DomainName;
SELECT @DomainID = SCOPE_IDENTITY();
END
MERGE INTO dbo.Contacts_DomainFK AS c
USING (SELECT DomainID = @DomainID, LocalPart = @LocalPart) AS p
ON c.DomainID = p.DomainID
AND c.LocalPart = p.LocalPart
WHEN NOT MATCHED THEN
INSERT (DomainID, LocalPart) VALUES(p.DomainID, p.LocalPart);
END
GOAnd again, we dump the 10,000 unique addresses into a #temp table for re-use:
... ) SELECT DISTINCT EmailAddress = y.localpart + '@' + y.domain, DomainName = y.domain, LocalPart = y.localpart INTO #foo FROM x INNER JOIN y ON x.i = y.i;
And once again I could create a cursor for each method and time the run:
DECLARE @EmailAddress VARCHAR(320), @DomainName VARCHAR(255), @LocalPart VARCHAR(64); SELECT SYSDATETIME(); DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT EmailAddress, DomainName, LocalPart FROM #foo; OPEN c; FETCH NEXT FROM c INTO @EmailAddress, @DomainName, @LocalPart; WHILE (@@FETCH_STATUS <> -1) BEGIN --EXEC dbo.Contact_Create_Original @EmailAddress = @EmailAddress; --EXEC dbo.Contact_Create_Split @LocalPart = @LocalPart, @DomainName = @DomainName; --EXEC dbo.Contact_Create_DomainFK @LocalPart = @LocalPart, @DomainName = @DomainName; FETCH NEXT FROM c INTO @EmailAddress, @DomainName, @LocalPart; END CLOSE c; DEALLOCATE c; SELECT SYSDATETIME();
The results here are almost identical to the results without compression:
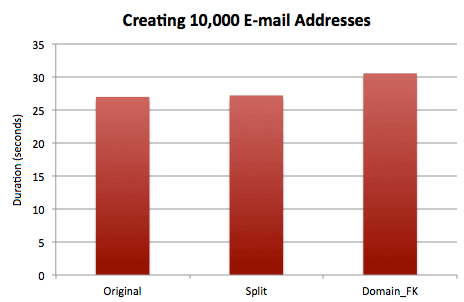
I also wanted to check the disk space usage again:
SELECT t.name, data_in_kb = 8 * (p.in_row_data_page_count) FROM sys.tables AS t INNER JOIN sys.dm_db_partition_stats AS p ON t.[object_id] = p.[object_id] WHERE p.index_id IN (0,1);
Results:
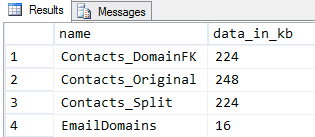
So when splitting the domains out into a separate table, we again have a slight increase in cost when performing inserts, and a mixed bag result in terms of disk space. This could partially be because the "random" domain names in use are all about 8 characters and probably compress a lot better than the integer values - I think the differences would be much more substantial if the domain names followed a much more realistic and volatile pattern. I'll leave that for perhaps another discussion.
Counting contacts from a particular domain
Again I picked a domain with a lot of contacts (gmail.com) and a domain with one (1010.com), and timed counting each of those 10,000 times:
SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_Original WHERE EmailAddress LIKE '%@gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_Original WHERE EmailAddress LIKE '%@1010.com'; GO 10000 SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_Split WHERE DomainName = 'gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_Split WHERE DomainName = '1010.com'; GO 10000 SELECT SYSDATETIME(); GO DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.Contacts_DomainFK AS c INNER JOIN dbo.EmailDomains AS d ON c.DomainID = d.DomainID WHERE d.DomainName = 'gmail.com'; SELECT @c = COUNT(*) FROM dbo.Contacts_DomainFK AS c INNER JOIN dbo.EmailDomains AS d ON c.DomainID = d.DomainID WHERE d.DomainName = '1010.com'; GO 10000 SELECT SYSDATETIME();
Results:
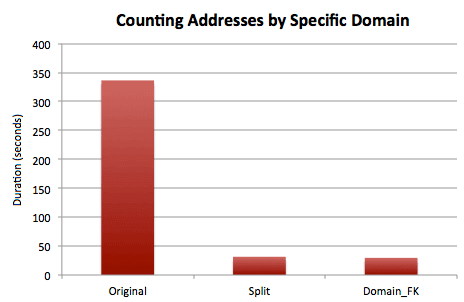
The original method is still by far the least efficient approach for this operation, but now the separate domain table comes into a virtual tie with the split method (probably due to a significantly fewer number of pages required to satisfy these specific queries).
Updating all addresses to use a different domain
Finally, we test changing a domain name and then changing it back, 500 times:
SELECT SYSDATETIME();
GO
UPDATE dbo.Contacts_Original
SET EmailAddress = LEFT(EmailAddress, CHARINDEX('@', EmailAddress))
+ 'att.net' WHERE EmailAddress LIKE '%@mci.com';
UPDATE dbo.Contacts_Original
SET EmailAddress = LEFT(EmailAddress, CHARINDEX('@', EmailAddress))
+ 'mci.com' WHERE EmailAddress LIKE '%@att.net';
GO 500
SELECT SYSDATETIME();
GO
UPDATE dbo.Contacts_Split
SET DomainName = 'att.net' WHERE DomainName = 'mci.com';
UPDATE dbo.Contacts_Split
SET DomainName = 'mci.com' WHERE DomainName = 'att.net';
GO 500
SELECT SYSDATETIME();
GO
UPDATE dbo.EmailDomains
SET DomainName = 'att.net' WHERE DomainName = 'mci.com';
UPDATE dbo.EmailDomains
SET DomainName = 'mci.com' WHERE DomainName = 'att.net';
GO 500
SELECT SYSDATETIME();Results:
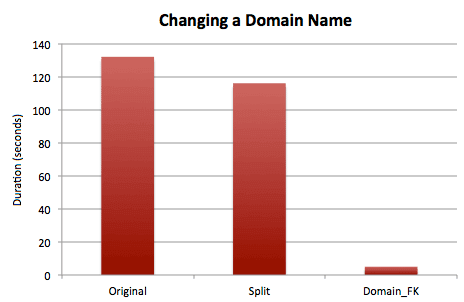
Once again it should come as no surprise that changing the domain as part of an e-mail address, as opposed to an entire value, is going to be more expensive - however the reduced I/O afforded by compression does bring this more in-line with the first split alternative. But obviously since a single-value change is all that's required for the separate domain name storage, this still comes in as the clear winner.
Conclusion
We can still see that different storage approaches can affect your workload and storage requirements, with or without data compression. You should play with the data you're storing in different ways and see how the various components of your typical workload respond to the changes.
Next Steps
- Review your current data storage policies.
- Consider alternate ways to store redundant data.
- Review the following tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2012-04-12
