By: Tim Wiseman | Updated: 2013-09-30 | Comments (6) | Related: > Indexing
Problem
SQL Server Clustered indexes can have enormous implications for performance of operations on a table. But are there times when a SQL Server non-clustered index would perform better than a clustered index for the same operation? Are there any trade-offs to consider? Check out this tip to learn more.
Solution
Effective Clustered Indexes can often improve the performance of many operations on a SQL Server table. However, there are times when a non-clustered index can improve the performance of certain queries more than a clustered index. Because of that, there are some situations where the performance of some queries can be improved by created a non-clustered index which is identical to the clustered index.
To be clear, having a non-clustered index along with the clustered index on the same columns will degrade performance of updates, inserts, and deletes, and it will take additional space on the disk. These drawbacks of adding additional indexes need to be considered before adding any new nonclustered index.
Some Background on SQL Server Clustered vs. NonClustered Indexes
Clustered indexes logically organize the entire table based on the indexing key (there is a common belief that the table is physically organized by the indexing key of a clustered index, but the reality is more complicated). When a clustered index exists, it affects the way the table is stored, if there is no clustered index the data is stored in an unordered heap.
Nonclustered indexes, on the other hand, exist separately from the table. They store pointers to the rows that contain the complete data. So, when there are times when it can be faster to get the complete information needed for that smaller index rather than resorting to the clustered index, which is organizing the entire underlying table.
SQL Server Performance Testing for SQL Server Clustered vs. NonClustered Indexes
In order to demonstrate the performance differences between the different types of indexes, I set up a few tests. So, I created four tables with identical junk data. They tables are:
- No indexes
- Clustered index created along with the primary key
- Only a non-clustered index
- Both clustered and non clustered indexes
Here is my test script:
/*
This script will generate the tables used for testing clustered and nonclustered indexes and
populate them. This can take quite a while to run. Almost 20 minutes on my test machine.
*/
use TestDb
GO
-- First, create a table with no indexes as a control.
if OBJECT_ID('noIndex', 'U') is not NULL
drop table dbo.noIndex
CREATE TABLE dbo.noIndex(
n int NOT NULL, -- part of index
singleChar char(1) NOT NULL, -- part of index
stringData char(2000) NOT NULL,
bigIntData bigint NOT NULL,
decimalData decimal(18, 0)NOT NULL
)
GO
--Populate the table with data
insert into dbo.noIndex(n, singleChar, stringData, bigIntData, decimalData)
select top 1000000 --1 Million, large enough to take some time on searches
row_number() over (order by s1.name) as n,
CHAR((row_number() over (order by s1.name) % 89) + 33) as singleChar,
REPLICATE(CHAR((row_number() over (order by s1.name) % 89) + 33), 2000) as stringData,
row_number() over (order by s1.name) * 1000000000 as bigIntData,
row_number() over (order by s1.name) *1.1 as decimalData
from master.dbo.syscolumns s1,
master.dbo.syscolumns s2
------
--Now create one with a primary key, which will automatically create the clustered index
GO
if OBJECT_ID('pkIndex', 'U') is not NULL
drop table dbo.pkIndex
CREATE TABLE dbo.pkIndex(
n int NOT NULL,
singleChar char(1) NOT NULL,
stringData char(2000) NOT NULL,
bigIntData bigint NOT NULL,
decimalData decimal(18, 0) NOT NULL,
constraint PK_pkIndextable primary key clustered (n, singleChar)
)
GO
--Populate the table with data
insert into
dbo.pkIndex(n, singleChar, stringData, bigIntData, decimalData)
select
n, singleChar, stringData, bigIntData, decimalData
from
dbo.noIndex
--------------
--Just the non_clustered index
GO
if OBJECT_ID('nonclusteredIdx', 'U') is not NULL
drop table dbo.nonclusteredIdx
CREATE TABLE dbo.nonclusteredIdx(
n int NOT NULL,
singleChar char(1) NOT NULL,
stringData char(2000) NOT NULL,
bigIntData bigint NOT NULL,
decimalData decimal(18, 0) NOT NULL
)
GO
--Populate the table with data
insert into
dbo.nonclusteredIdx(n, singleChar, stringData, bigIntData, decimalData)
select
n, singleChar, stringData, bigIntData, decimalData
from
dbo.pkIndex
create unique nonclustered index nonclusteredIdx_n
on dbo.nonclusteredIdx (n, singleChar)
--------------
--Just table with both indexes
GO
if OBJECT_ID('bothIdx', 'U') is not NULL
drop table dbo.bothIdx
GO
CREATE TABLE dbo.bothIdx(
n int NOT NULL,
singleChar char(1) NOT NULL,
stringData char(2000) NOT NULL,
bigIntData bigint NOT NULL,
decimalData decimal(18, 0) NOT NULL,
constraint PK_bothIdx primary key clustered (n, singleChar)
)
--Populate the table with data
insert into
dbo.bothIdx(n, singleChar, stringData, bigIntData, decimalData)
select
n, singleChar, stringData, bigIntData, decimalData
from
dbo.pkIndex
create unique nonclustered index both_nonclusteredIdx_n
on dbo.bothIdx (n, singleChar)
--------------------------------------------
--Playing around with some queries
select n, singleChar
from dbo.bothIdx
where n % 10 = 0
select n, singleChar
from dbo.bothIdx
where singlechar = 'a'
select n, singleChar
from dbo.noIndex
where n % 10 = 0
select n, singleChar, bigIntData
from dbo.nonclusteredIdx
where n % 10 = 0
select n, singleChar, bigIntData
from dbo.pkIndex
where n % 10 = 0
order by n desc
SQL Server Execution Plans for SQL Server Clustered vs. NonClustered Indexes
With those tables available, I found it helpful to look at some of the execution plans for queries run on those tables.
For instance, SQL Server estimates that running a simple count on the table with the clustered index is substantially more expensive than running it on the table with only the nonclustered index:
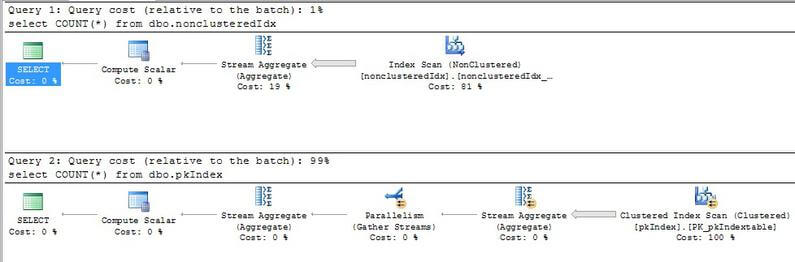
This is born out by the fact that the optimizer will use the nonclustered index when this query is run against a table with both as well as by some time trials I ran on my machine with Python that compared the execution time. Here is that sample code followed by some of the results:
# -*- coding: utf-8 -*-
"""
@author: TimothyAWiseman
Not using timeit here since we want to clear out the cache before
every single run. Given the need to clear out the cache each time
and the desire to not include the time to clear the cache in the measurements
timeit is less than optimal. Therefore using a timing wrapper instead.
There is more on clearing the cache for SQL Server at:
http://www.mssqltips.com/sqlservertip/1360/clearing-cache-for-sql-server-performance-testing/
Not all of these tests made it into the tip.
"""
#import useful modules
import pyodbc #to connect to SQL Server
import matplotlib.pyplot as plt #graph the results
import numpy as np
import time
##########################################################
#Establish parameters that will be used throughout the running of the script
#These are, in effect, settings. If this were meant as a complete program
#I would shut these off into a configuration file or make them user
#selectable. As a custom, test script it makes sense to just include them here.
#Must configure the conn string for your instance of SQL Server
sqlConnStr = (#Insert your SQL Conn Str Here )
#Leaving off the schema from the table names for ease of
#labeling graphs.
tableNames = ['noIndex', 'pkIndex', 'nonclusteredIdx', 'bothIdx']
#########################################################
#Create the utility functions
def time_wrapper(func):
def wrapper(*arg, **kw):
start = time.time()
result = func(*arg, **kw)
end = time.time()
return (end - start), result
return wrapper
def clearCache(curs):
curs.execute('checkpoint')
curs.execute('dbcc dropcleanbuffers')
def getRowCount(curs, tableName):
"""Gets the rowcount of the table named by tableName."""
sql = """select count(*)
from {}""".format(tableName)
curs.execute(sql)
return curs.fetchone()
def getInfoFromIndex(curs, tableName):
"""Gets information from that is entirely contained within the index
key.
The where clause is included to reduce the amount of raw data returned to
keep the execution times reasonable and to prevent the network trips
from swamping out the execution time of the query on the server.
"""
sql = """select n, singlechar
from {}
where n%1000 = 0""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getInfoOutsideIndex(curs, tableName):
"""This pulls in a column that requires information that is not in the
index."""
sql = """select n, singleChar, bigIntData, decimalData
from {}
where n%1000 = 0""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getTop100(curs, tableName):
"""This pulls in a column that requires information that is not in the
index."""
sql = """select top 100 *
from {}""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getTop100Order(curs, tableName):
"""This pulls in a column that requires information that is not in the
index."""
sql = """select top 100 *
from {}
order by n""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getTop100OrderDesc(curs, tableName):
"""This pulls in a column that requires information that is not in the
index."""
sql = """select top 100 *
from {}
order by n desc""".format(tableName)
curs.execute(sql)
return curs.fetchall()
#Originally I tried to do a lookup for just one value, but the results
#were essentially random as other factors swamped out the time for SQL to
#execute, and most results were essentially 0. This worked better,
#but I found I needed to do more reps to get anything reliable. Also,
#this comes across best if the no index table is left out since it is
#so dramatically slower than any of the others.
def specificValueLookups(curs, tableName):
"""Looks for just one row"""
sql = """select n, singleChar, stringData, bigIntData, decimalData
from {}
where n in (1234, 456, 789, 1, 101112, 2, 131415, 5)""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getRangeIndexOnly(curs, tableName):
"""Gets a range looking for only values that are part of the index.
Expect this to favor the nonclustered index."""
sql = """select n, singleChar
from {}
where n between 100 and 20000
and singleChar between 'A' and 'Z'""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def getRangeAllValues(curs, tableName):
"""Gets a range looking for only values that are part of the index.
Expect this to favor the nonclustered index."""
sql = """select *
from {}
where n between 100 and 20000
and singleChar between 'A' and 'Z'""".format(tableName)
curs.execute(sql)
return curs.fetchall()
def makeGraphForTimes(funcToTime, curs, tableNames, graphFileName, graphTitle='', numReps = 6):
"""Times the repeated iteration of the function and makes a graph out of it.
The function needs to take the paramaters (cursor, tableName) or this will generate an error."""
timedFunc = time_wrapper(funcToTime)
resultsDict = {}
for tableName in tableNames:
resultsDict[tableName] = []
for i in range(numReps):
clearCache(curs)
thisIterTime, result = timedFunc(curs, tableName)
resultsDict[tableName].append(thisIterTime)
#print resultsDict #used for testing
avgs = {x: np.mean(resultsDict[x]) for x in resultsDict}
plt.figure()
width = .6
plt.bar(np.arange(len(avgs)), avgs.values(), align = 'center')
plt.xticks(np.arange(len(avgs) + width/2), avgs.keys(), rotation = 17, size = 'small')
plt.ylabel('Time in Seconds')
plt.title(graphTitle)
plt.savefig(graphFileName)
plt.close('all')
########################################################
#Execute the main script
if __name__ == '__main__':
#autocommit
sqlConn = pyodbc.connect(sqlConnStr, autocommit = True)
curs = sqlConn.cursor()
makeGraphForTimes(getRowCount, curs, tableNames, 'RowCountTest.jpg', 'Row Count Execution Time')
makeGraphForTimes(getInfoFromIndex, curs, tableNames, 'DataFromIndex.jpg', 'Query Covered by Index')
makeGraphForTimes(getInfoOutsideIndex, curs, tableNames, 'DataOutOfIndex.jpg', 'Query not covered by Index')
#Removing the noIndex for some of these because it makes the graph hard to read
tnMinusNoIndex = [x for x in tableNames if x != 'noIndex']
makeGraphForTimes(getTop100, curs, tnMinusNoIndex, 'Top100.Jpg', 'Top 100 No Conditions', numReps = 20)
makeGraphForTimes(getTop100Order, curs, tnMinusNoIndex, 'Top100Order.Jpg', 'Top 100 Ordered By', numReps = 20)
makeGraphForTimes(getTop100OrderDesc, curs, tnMinusNoIndex, 'Top100OrderDesc.Jpg', 'Top 100 Descending', numReps = 20)
makeGraphForTimes(specificValueLookups, curs, tnMinusNoIndex, 'SpecificValueLookup.Jpg', 'Lookup One Row', numReps = 500)
makeGraphForTimes(getRangeIndexOnly, curs, tnMinusNoIndex, 'RangeIdxOnly.Jpg', 'Lookup Range for Values in Index', numReps = 50)
makeGraphForTimes(getRangeAllValues, curs, tnMinusNoIndex, 'RangeAllValues.Jpg', 'Lookup Range for All Values', numReps = 100)
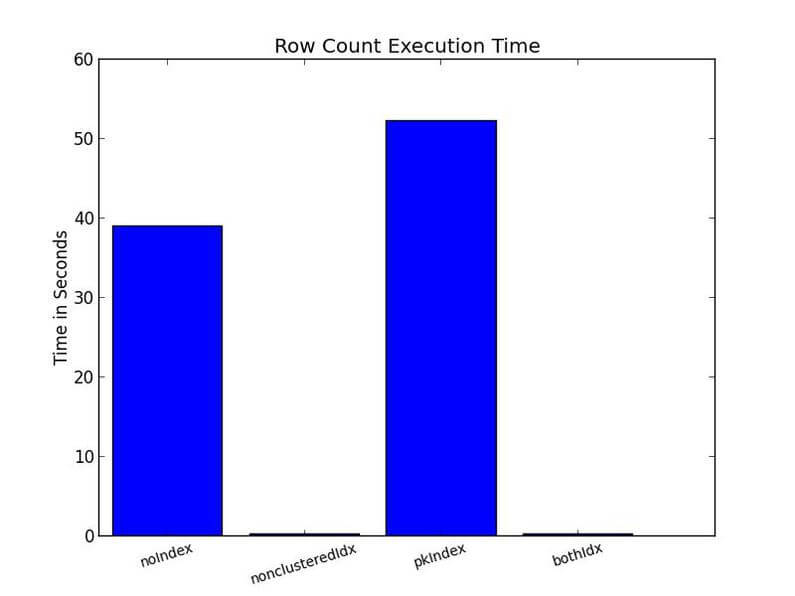
Let's start digging into the results. You can see with the row count example, the table with the non clustered indexes performed the best.
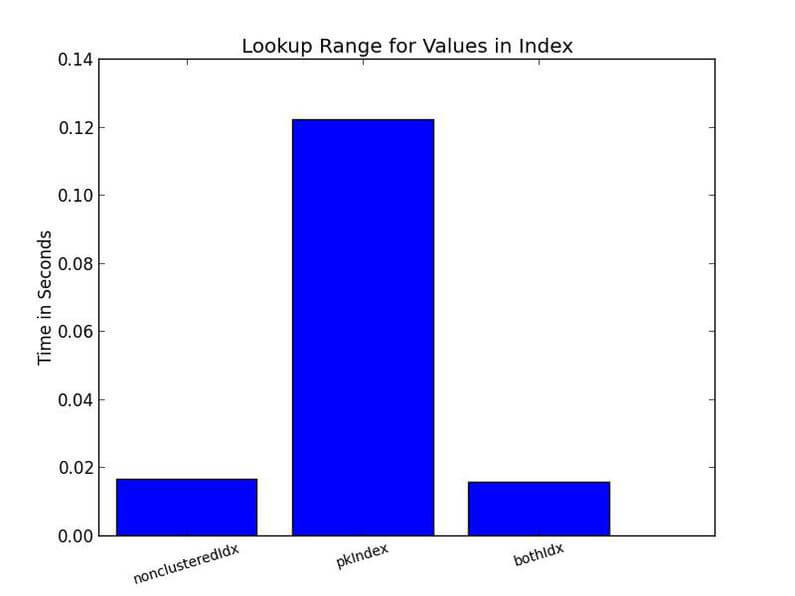
Similarly, nonclustered indexes do better when the select statement is entirely covered by the index.
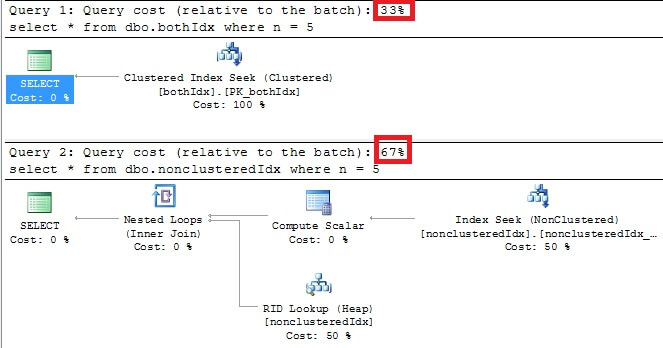
Of course, clustered indexes shine in retrieving the entire row for specific values, as the optimizer shows if we look at the execution plans for a simple query like "select * from {tablename} where n = 5":
Conclusion
Clustered indexes and nonclustered indexes often perform best under different circumstances. Therefore it can be beneficial for certain types of operations to create a nonclustered index which is identical to the clustered index on a table. However, the benefits in retrieval need to be balanced against the additional overhead that maintaining that index will cause.
Next Steps
- Check out these additional resources:
- See Greg Robidoux's article for more on the differences between Clustered Tables vs. Heaps.
- Greg has another excellent article detailing the different types of indexes titled Understanding SQL Server Indexing
- The MSDN article Clustered and Nonclustered Indexes Described provides more background information.
- SQL Server Index Checklist
- SQL Server Indexing Basics






About the author
 Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.
Tim Wiseman is a SQL Server DBA and Python Developer in Las Vegas.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2013-09-30
