By: Sergey Gigoyan | Updated: 2021-07-20 | Comments (13) | Related: > Database Design
Problem
According to database design best practices, a SQL Server table should not contain duplicate rows. During the database design process primary keys should be created to eliminate duplicate rows. However, sometimes we need to work with databases where these rules are not followed or exceptions are possible (when these rules are bypassed knowingly). For example, when a staging table is used and data is loaded from different sources where duplicate rows are possible. When the loading process completes, table should be cleaned or clean data should be loaded to a permanent table, so after that the duplicates are no longer needed. Therefore, an issue concerning the removal of duplicates from the loading table arises. In this tutorial let's examine some ways to solve data de-duplication needs.
Solution
We will consider two cases in this tip:
- The first case is when a SQL Server table has a primary key (or unique index) and one of the columns contains duplicate values which should be removed.
- The second case is that table does not have a primary key or any unique indexes and contains duplicate rows which should be removed. Let's discuss these cases separately.
How to remove duplicate rows in a SQL Server table
Duplicate records in a SQL Server table can be a very serious issue. With duplicate data it is possible for orders to be processed numerous times, have inaccurate results for reporting and more. In SQL Server there are a number of ways to address duplicate records in a table based on the specific circumstances such as:
- Table with Unique Index - For tables with a unique index, you have the opportunity to use the index to order identify the duplicate data then remove the duplicate records. Identification can be performed with self-joins, ordering the data by the max value, using the RANK function or using NOT IN logic.
- Table without a Unique Index - For tables without a unique index, it is a bit more challenging. In this scenario, the ROW_NUMBER() function can be used with a common table expression (CTE) to sort the data then delete the subsequent duplicate records.
Check out the examples below to get real world examples on how to delete duplicate records from a table.
Removing duplicates rows from a SQL Server table with a unique index
Test Environment Setup
To accomplish our tasks, we need a test environment which we create with the following statement:
USE master GO CREATE DATABASE TestDB GO USE TestDB GO CREATE TABLE TableA ( ID INT NOT NULL IDENTITY(1,1), Value INT, CONSTRAINT PK_ID PRIMARY KEY(ID) )
Now let's insert data into our new table - 'TableA' with the following statement:
USE TestDB GO INSERT INTO TableA(Value) VALUES(1),(2),(3),(4),(5),(5),(3),(5) SELECT * FROM TableA SELECT Value, COUNT(*) AS DuplicatesCount FROM TableA GROUP BY Value
As we can see in the result set below the values 3 and 5 exists in the 'Value' column more than once:
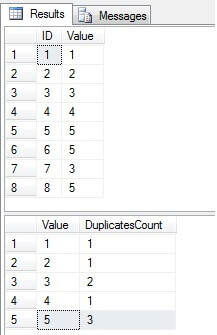
Identify Duplicate Rows in a SQL Server Table
Our task is to enforce uniqueness for the 'Value' column by removing duplicates. Removing duplicate values from table with a unique index is a bit easier than removing the rows from a table without it. First of all, we need to find duplicates. There are many different ways to do that. Let's investigate and compare some common ways. In the following queries below there are six solutions to find that duplicate values which should be deleted (leaving only one value):
----- Finding duplicate values in a table with a unique index
--Solution 1
SELECT a.*
FROM TableA a, (SELECT ID, (SELECT MAX(Value) FROM TableA i WHERE o.Value=i.Value GROUP BY Value HAVING o.ID < MAX(i.ID)) AS MaxValue FROM TableA o) b
WHERE a.ID=b.ID AND b.MaxValue IS NOT NULL
--Solution 2
SELECT a.*
FROM TableA a, (SELECT ID, (SELECT MAX(Value) FROM TableA i WHERE o.Value=i.Value GROUP BY Value HAVING o.ID=MAX(i.ID)) AS MaxValue FROM TableA o) b
WHERE a.ID=b.ID AND b.MaxValue IS NULL
--Solution 3
SELECT a.*
FROM TableA a
INNER JOIN
(
SELECT MAX(ID) AS ID, Value
FROM TableA
GROUP BY Value
HAVING COUNT(Value) > 1
) b
ON a.ID < b.ID AND a.Value=b.Value
--Solution 4
SELECT a.*
FROM TableA a
WHERE ID < (SELECT MAX(ID) FROM TableA b WHERE a.Value=b.Value GROUP BY Value HAVING COUNT(*) > 1)
--Solution 5
SELECT a.*
FROM TableA a
INNER JOIN
(SELECT ID, RANK() OVER(PARTITION BY Value ORDER BY ID DESC) AS rnk FROM TableA ) b
ON a.ID=b.ID
WHERE b.rnk > 1
--Solution 6
SELECT *
FROM TableA
WHERE ID NOT IN (SELECT MAX(ID)
FROM TableA
GROUP BY Value)
As we can see the result for all cases is the same as shown in the screenshot below:
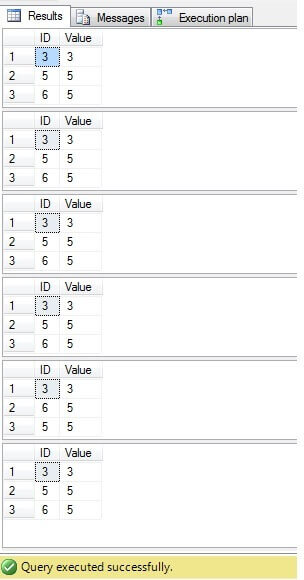
Only rows with ID=3, 5, 6 need to be deleted. Looking at the execution plan we can see that latest - the most 'compact' solution ('Solution 6') has a highest cost (in our example there is a primary key on the 'ID' column, so 'NULL' values are not possible for that column, therefore 'NOT IN' will work without any problem), and the second has the lowest cost:

Deleting Duplicate Rows in a SQL Server Table
Now by using the following queries, let's delete duplicate values from the table. To simplify our process, we will use only the second, the fifth and the sixth queries:
USE TestDB
GO
--Initializing the table
TRUNCATE TABLE TableA
INSERT INTO TableA(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
--Deleting duplicate values
DELETE t
FROM TableA t
WHERE ID IN ( SELECT a.ID FROM TableA a, (SELECT ID, (SELECT MAX(Value) FROM TableA i WHERE o.Value=i.Value GROUP BY Value HAVING o.ID=MAX(i.ID)) AS MaxValue FROM TableA o) b
WHERE a.ID=b.ID AND b.MaxValue IS NULL)
--Initializing the table
TRUNCATE TABLE TableA
INSERT INTO TableA(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
--Deleting duplicate values
DELETE a
FROM TableA a
INNER JOIN
(SELECT ID, RANK() OVER(PARTITION BY Value ORDER BY ID DESC) AS rnk FROM TableA ) b
ON a.ID=b.ID
WHERE b.rnk>1
--Initializing the table
TRUNCATE TABLE TableA
INSERT INTO TableA(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
--Deleting duplicate values
DELETE FROM TableA
WHERE ID NOT IN (SELECT MAX(ID)
FROM TableA
GROUP BY Value)
Deleting the data and looking into the execution plans again we see that the fastest is the first DELETE statement and the slowest is the last as expected:
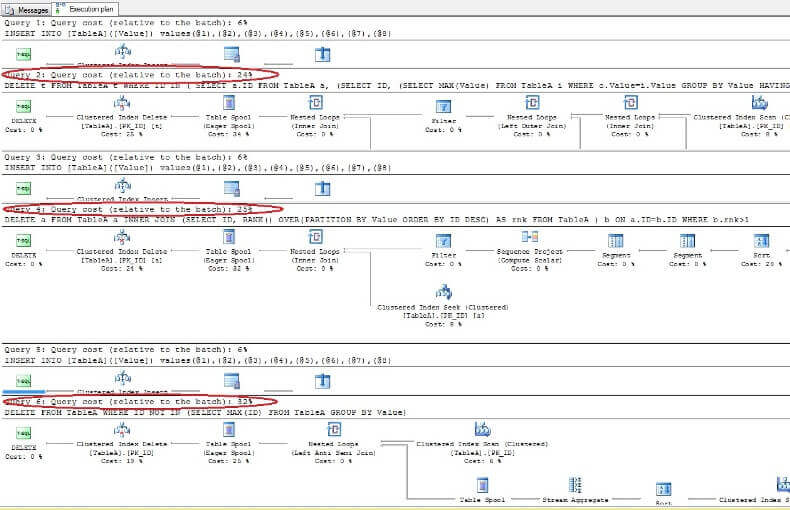
Removing duplicates from table without a unique index in ORACLE
As a means to help illustrate our final example in this tip, I want to explain some similar functionality in Oracle. Removing duplicate rows from the table without a unique index is a little easier in Oracle than in SQL Server. There is a ROWID pseudo column in Oracle which returns the address of the row. It uniquely identifies the row in the table (usually in the database also, but in this case, there is an exception - if different tables store data in the same cluster they can have the same ROWID). The query below creates and inserts data into table in the Oracle database:
CREATE TABLE TableB (Value INT); INSERT INTO TableB(Value) VALUES(1); INSERT INTO TableB(Value) VALUES(2); INSERT INTO TableB(Value) VALUES(3); INSERT INTO TableB(Value) VALUES(4); INSERT INTO TableB(Value) VALUES(5); INSERT INTO TableB(Value) VALUES(5); INSERT INTO TableB(Value) VALUES(3); INSERT INTO TableB(Value) VALUES(5);
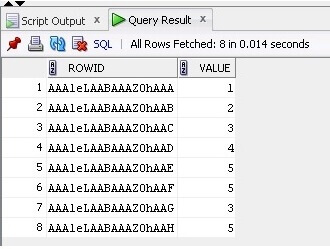
Now we are selecting the data and ROWID from the table:
SELECT ROWID, Value FROM TableB;
The result is below:
Now using ROWID, we will easily remove duplicate rows from table:
DELETE TableB
WHERE rowid not in (
SELECT MAX(rowid)
FROM TableB
GROUP BY Value
);
We can also remove duplicates using the code below:
DELETE from TableB o
WHERE rowid < (
SELECT MAX(rowid)
FROM TableB i
WHERE i.Value=o.Value
GROUP BY Value
);
Removing duplicates from a SQL Server table without a unique index
Unlike Oracle, there is no ROWID in SQL Server, so to remove duplicates from the table without a unique index we need to do additional work for generating unique row identifiers:
USE TestDB GO CREATE TABLE TableB (Value INT) INSERT INTO TableB(Value) VALUES(1),(2),(3),(4),(5),(5),(3),(5) SELECT * FROM TableB ; WITH TableBWithRowID AS ( SELECT ROW_NUMBER() OVER (ORDER BY Value) AS RowID, Value FROM TableB ) DELETE o FROM TableBWithRowID o WHERE RowID < (SELECT MAX(rowID) FROM TableBWithRowID i WHERE i.Value=o.Value GROUP BY Value) SELECT * FROM TableB
In the code above, we are creating a table with duplicate rows. We are generating unique identifiers using the ROW_NUMBER() function and by using common table expression (CTE) we are deleting duplicates:
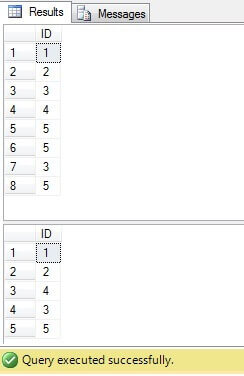
This code, however, can be replaced with more compact and optimal one:
USE TestDB GO --Initializing the table TRUNCATE TABLE TableB INSERT INTO TableB(Value) VALUES(1),(2),(3),(4),(5),(5),(3),(5) --Deleting duplicate values ; WITH TableBWithRowID AS ( SELECT ROW_NUMBER() OVER (PARTITION BY Value ORDER BY Value) AS RowID, Value FROM TableB ) DELETE o FROM TableBWithRowID o WHERE RowID > 1 SELECT * FROM TableB
Having said that, it is possible to identify the physical address of the row in SQL Server as well. Despite the fact that it is practically impossible to find official documentation about this feature, it can be used as an analog to ROWID pseudo column in Oracle. It is called %%physloc%% (since SQL Server 2008) and it is a virtual binary(8) column which shows the physical location of the row. As the value of %%physloc%% is unique for each row, we can use it as a row identifier while removing duplicate rows from a table without a unique index. Thus, we can remove duplicate rows from a table without a unique index in SQL Server like in Oracle as well as like in the case when the table has a unique index.
The first two queries below are the equivalent versions of removing duplicates in Oracle, the next two are queries for removing duplicates using %%physloc%% similar to the case of the table with a unique index, and in the last query, %%physloc%% is not used just for comparing performance of all of these options:
-- option 1
--Initializing the table
TRUNCATE TABLE TableB
INSERT INTO TableB(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
DELETE o
FROM
(SELECT %%physloc%% as RowID, value FROM TableB) o
WHERE o.RowID < (
SELECT MAX(%%physloc%%)
FROM TableB i
WHERE i.Value=o.Value
GROUP BY Value
)
-----------
-- option 2
--Initializing the table
TRUNCATE TABLE TableB
INSERT INTO TableB(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
DELETE TableB
WHERE %%physloc%% not in (
SELECT MAX(%%physloc%%)
FROM TableB
GROUP BY Value
)
-----------
-- option 3
--Initializing the table
TRUNCATE TABLE TableB
INSERT INTO TableB(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
DELETE b1
FROM
(SELECT %%physloc%% as RowID, value FROM TableB) b1
INNER JOIN
(SELECT %%physloc%% as RowID, RANK() OVER(PARTITION BY Value ORDER BY %%physloc%% DESC) AS rnk FROM TableB ) b2
ON b1.RowID=b2.RowID
WHERE b2.rnk>1
-----------
-- option 4
--Initializing the table
TRUNCATE TABLE TableB
INSERT INTO TableB(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
DELETE b1
FROM Tableb b1
WHERE %%physloc%% < (SELECT MAX(%%physloc%%)
FROM Tableb b2
WHERE b1.Value=b2.Value
GROUP BY Value
HAVING COUNT(*) > 1
)
-----------
-- option 5
--Initializing the table
TRUNCATE TABLE TableB
INSERT INTO TableB(Value)
VALUES(1),(2),(3),(4),(5),(5),(3),(5)
; WITH
TableBWithRowID AS
(
SELECT ROW_NUMBER() OVER (partition by Value ORDER BY Value) AS RowID, Value
FROM TableB
)
DELETE o
FROM TableBWithRowID o
WHERE RowID > 1
Analyzing the Execution Plans, we can see that the first and the last queries are the fastest when compared to the overall batch times:
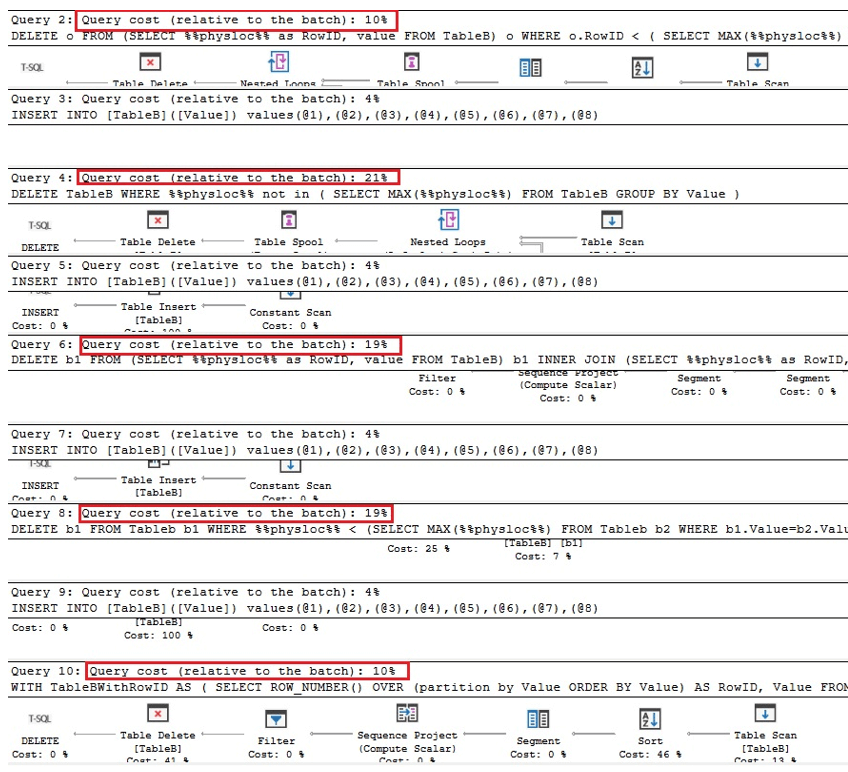
Hence, we can conclude that in general, using %%physloc%% does not improve the performance. While using this approach, it is very important to realize that this is an undocumented feature of SQL Server and, therefore, developers should be very careful.
There are other ways to remove duplicates which is not discussed in this tip. For example, we can store distinct rows in a temporary table, then delete all data from our table and after that insert distinct rows from temporary table to our permanent table. In this case DELETE and INSERT statements should be included in one transaction.
Conclusion
During our experience we face situations when we need to clean duplicate values from SQL Server tables. The duplicate values can be in the column which will be de-duplicated based on our requirements or the table can contain duplicate rows. In either case we need to exclude the data to avoid data duplication in the database. In this tip we explained some techniques which hopefully will be helpful to solve these types of problems.
Next Steps
- Review this related information:
- https://technet.microsoft.com/en-us/library/ms190766(v=sql.105).aspx
- https://msdn.microsoft.com/en-us/library/ms186734.aspx
- https://docs.oracle.com/cd/B19306_01/server.102/b14200/pseudocolumns008.htm
- Delete duplicate rows with no primary key on a SQL Server table
- Different strategies for removing duplicate records in SQL Server
- Removing Duplicates Rows with SSIS Sort Transformation






About the author
 Sergey Gigoyan is a database professional with more than 10 years of experience, with a focus on database design, development, performance tuning, optimization, high availability, BI and DW design.
Sergey Gigoyan is a database professional with more than 10 years of experience, with a focus on database design, development, performance tuning, optimization, high availability, BI and DW design.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-07-20
