By: Eduardo Pivaral | Comments (3) | Related: > TSQL
Problem
Sometimes you must perform DML processes (insert, update, delete or combinations of these) over large tables, if your SQL Server database has a high concurrency, these types of processes can lead to locks, or filling the transaction log, even if you run these processes outside of business hours. So maybe you were asked to optimize some processes to avoid large log growths or minimizing locks to tables and by optimizing these processes some execution time can be saved as well. How can this be achieved?
In this previous tip we discussed how to perform a batch solution for tables with sequential numeric keys, but how about tables without sequential numeric keys? In this tip we will show another approach for these types of tables.
Solution
We will do these DML processes using batches with the help of the TOP statement. NOTE: We could also use SET ROWCOUNT, but this function will be deprecated in a future release of SQL Server, so I do not recommend using it. This also gives you the ability to implement custom "stop-resume" logic. We will show you a general method, so you can take it as a base to implement it on your own processes.
For this method, a sequential numeric key is not required, but we still require a key, so if you need to perform an operation over a large Heap, you will need to make sure there is a key for the table.
Basic Algorithm
The basic batch process is something like this:
DECLARE @id_control INT
DECLARE @batchSize INT
DECLARE @results INT
SET @results = 1 --stores the row count after each successful batch
SET @batchSize = 10000 --How many rows you want to operate on each batch
SET @id_control = -1 --a value lower than your lowest key value
-- when 0 rows returned, exit the loop
WHILE (@results > 0)
BEGIN
-- put your custom code here
UPDATE top(@batchSize) <YOUR_TABLE> -- or any other DML command
SET <your operations>
, @id_control = [<your key column>] --it takes the latest value updated to help next iteration
WHERE [<your key column>] > @id_control -- filter rows already processed
AND <additional evaluations you could need>
-- End of your custom operations
-- very important to obtain the latest rowcount to avoid infinite loops
SET @results = @@ROWCOUNT
END
Explanation of Code
We will use the TOP command to limit the number of rows processed for each batch.
Also, we included a control variable to filter the next iteration (if you use a delete, you can remove the filter, since you don’t need to track the deleted rows, so for deletes it will be simpler) and we iterate through it until the row count is 0 rows.
So, with this approach we don’t need sequential numeric keys, just any key to uniquely identify each row (to avoid processing more rows than we really need).
Important Note: You might notice the complexity of this approach that handles the drawbacks from the previous tip, that was much more simpler, so you must be extra careful testing it before moving into production environments.
Sample Table and Data Set
We will use a test table [test_items] with this definition:
CREATE TABLE [dbo].[test_items]( [id] [bigint] IDENTITY(1,1) NOT NULL, [date] [smalldatetime] NOT NULL, [quantity] [int] NOT NULL, [value] [money] NOT NULL, [description] [nvarchar](500) NOT NULL, [enabled] [bit] NOT NULL, [category1] [tinyint] NOT NULL, [category2] [tinyint] NOT NULL, CONSTRAINT [PK_test_items] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
I then inserted 9,126,650 random records.
UPDATE Statement in Single Batch
We will take this as a base UPDATE inside a transaction. Update the varchar field with random data (so our test is more real), and after clearing the cache, we proceed to execute it.
Here is a screenshot of the transaction log before the operation.

BEGIN TRAN; UPDATE test_items SET [description] = 'PROCESSED IN 1 BATCHES!' WHERE category1 in (2,7,9) COMMIT TRAN;
The execution took 55 seconds on my lab machine.
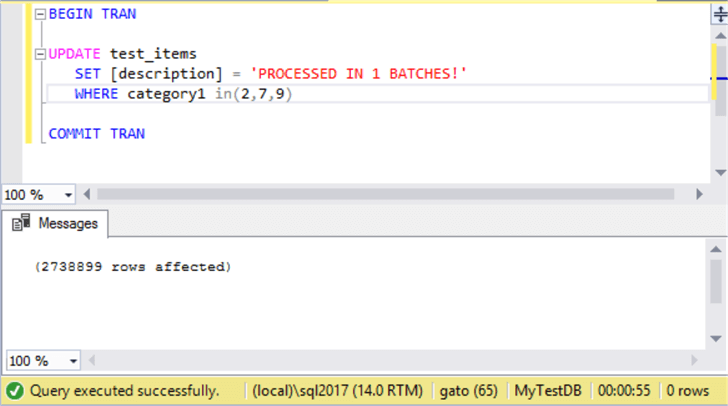
There were 2,738,899 rows updated.
And the log usage? Checking the log size again we can see it grow 1.69 GB (and then released the space since the database is in SIMPLE mode):

T-SQL Update Using Smaller Batches
Now let's execute the same UPDATE statement, we copied the original data from a backup, then released the log size and performed a cache cleanup, this time the UPDATE process will be performed in batches, as follows:
SET NOCOUNT ON;
DECLARE @id_control INT
DECLARE @batchSize INT
DECLARE @results INT
SET @results = 1 --stores the row count after each successful batch
SET @batchSize = 20000 --How many rows you want to operate on each batch
set @id_control = -1
-- when 0 rows returned, exit the loop
WHILE (@results > 0)
BEGIN
-- put your custom code here
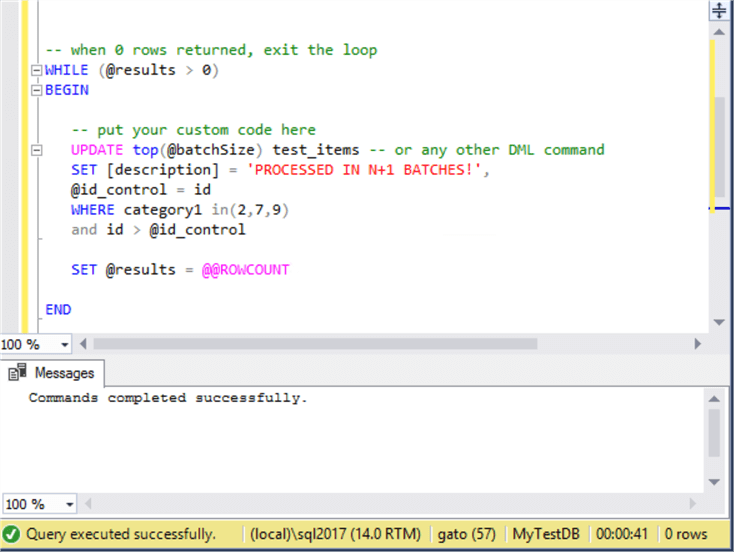
UPDATE top(@batchSize) test_items -- or any other DML command
SET [description] = 'PROCESSED IN N+1 BATCHES!',
@id_control = id
WHERE category1 in (2,7,9)
AND id > @id_control
SET @results = @@ROWCOUNT
END
SET NOCOUNT OFF;
This time the query execution was 41 seconds, so there was a slight improvement in time:
And what about the log size? As we can see there was an improvement, this time the log growth was less than 0.25 GB.

There is only a last thing to verify, the number of rows affected must be the same, so let's check it:
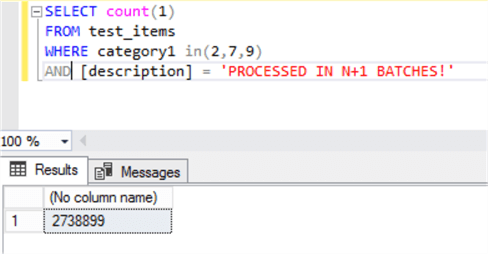
And yes, we have the same 2,738,899 rows were affected.
Conclusion
As you can see, for very large DML processes, treating the data in batches could be beneficial for execution time, transaction log usage or both.
Even when the execution time is reduced, it is not as much as with the previous method. Another drawback of this method, is that you still need a key with a datatype that allows comparison to use the greater than operator.
As stated above, if you plan to use this method for DELETE operations, you can get rid of the id control part of the code.
Next Steps
- Check out part 1 of this tip, where we explained a simpler method, but with more requirements to meet.
- You can determine if your process can use this batch method just running the SELECT and comparing the number of expected rows with the results.
- You can increase/decrease the batch size to suit your needs, but for it to have meaning, batch size must be less than 50% of the expected rows to be processed.
- This process can be adapted to implement a "stop-retry" logic so already processed rows can be skipped if you decide to cancel the execution.
- It also supports multi-statement processes (in fact, this is the real-world use of this approach) and you can achieve this with a "control" table having all the records to work with, using a temporary or staging table, and update it accordingly, just please have in mind that if your process is very complex, the execution time can be greater due to the operations with the control tables, so the only gain you could have can be minimizing locks and the transaction log growth.
- If you want to implement an "execution log" you can achieve this by adding PRINT statements, just note that this could slow down some processes, especially for very small batch sizes.






About the author
 Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments.
Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
