By: Rick Dobson | Updated: 2023-06-20 | Comments (2) | Related: > TSQL
Problem
This article discusses starter T-SQL examples for table and column metadata from SQL Server databases. It will cover how to use the metadata from sys.tables and how to coordinate this system view with sys.columns, sys.system_columns, and sys.all_columns.
Solution
Sys views, sometimes called system catalog views, are for returning metadata about objects in a SQL Server database. Metadata is data about data. For example, you can use system views to learn about the attributes of tables and columns in a SQL Server database.
- The sys.tables view returns a row for each user-defined table in a SQL Server database.
- The sys.columns view returns a row for each user-defined object in a SQL
Server database that has columns in a SQL Server database. Objects that
have columns include:
- Table-valued assembly functions
- Inline table-valued SQL functions
- Internal tables
- System tables
- Table-value SQL functions
- User-defined tables
- Views
- The sys.system_columns view returns a row for each system object with columns.
- The sys.all_columns view returns a row for the union of all user-defined and system-defined objects with columns.
It is important to understand that SQL Server columns only exist in relation to a SQL Server object, such as a user-defined table. In a sense, there is a parent-child relationship between a table object and the columns that belong in the table. This relationship is maintained with the help of an object_id value available from the metadata for both the column and the object to which the column belongs. Another especially critical attribute to the identity of a column and the object to which it belongs is its name. Column names belonging to objects must be unique within each object. The SQL Server engine assigns object_id values to objects and columns when they are created. When a user creates an object, such as a table, it must give the object a name.
This tip builds particularly on a previous article that offers a "getting started" perspective for sys views, "Starter Metadata T-SQL Query Examples for Databases and Tables". The objective of this pair of tips is to give you an introduction to sys views with enough T-SQL examples to empower you to build your own custom applications for processing returns from sys.databases, sys.tables, sys.columns, sys.system_columns, and sys.all_columns views. Other MSSQLTips.com articles for sys views either treat a particular objective ("List columns and attributes for every table in a SQL Server database") or include a large library of T-SQL tips ("Over 40 queries to find SQL Server tables with or without a certain property"). Additionally, Greg Robidoux presents a tip (INFORMATION_SCHEMA.COLUMNS) that introduces Information_Schema views, instead of sys views, for returning SQL Server metadata.
Copying Sys View Contents into a Temporary Table
With the exception of sys.databases, the sys views referenced in this tip return metadata for a particular SQL Server database. The SQL Server Management Studio (SSMS) use statement provides a means of specifying a particular SQL Server database as the source for a query of a sys view, such as sys.tables. Unlike other sys views, sys.databases can return all the database names on a SQL Server instance in one query.
If you need to develop a solution that reports metadata for more than one SQL Server database on a SQL Server instance with sys.tables and sys.all_columns, then you can employ the following approach.
- The following query starts by creating a fresh copy of #temp_from_sys_tables_for_multiple_databases; this temp table is designed to store metadata from multiple databases on a SQL Server instance.
- The different databases in this tip have names of master, DataScience, Correlate_index_ETFs_and_ECON_indices,
and alter_examples; the query has four main sections – one for each database:
- Each section starts with a use statement to designate a default database for a section of the overall query
- Next, an insert into statement and a select statement transfer the contents
of a sys view query into #temp_from_sys_tables_for_multiple_databases; the
two statements gather metadata information into three columns within the
temp table:
- Recall that the sys.tables view returns one row per table in a database
- The column names for each row are the name for the table name and create_date for the date the table was created. The source database column value is returned by the db_name() function, which returns the name of the current database within a section of the tip
- By specifying a new database name at the beginning of each succeeding section, you can transfer the contents of multiple databases into a table for subsequent reference and querying
- For example, the final select statement in the following script displays the contents from sys.tables for any selection of database names that you specify in the script.
-- source: https://www.MSSQLTips.com -- drop table if exists #temp_from_sys_tables_for_multiple_databases go create table #temp_from_sys_tables_for_multiple_databases( name sysname ,create_date date ,source_database sysname ) -- save sys.tables info -- in #temp_from_sys_tables_for_multiple_databases -- from the tables in four databases -- master -- DataScience -- Correlate_index_ETFs_and_ECON_indices -- alter_examples -- specify master as default database use master -- save table info from default database insert into #temp_from_sys_tables_for_multiple_databases select name ,create_date ,db_name() [source database] from sys.tables -- specify DataScience as default database use DataScience insert into #temp_from_sys_tables_for_multiple_databases -- save table info from default database select name ,create_date ,db_name() [source database] from sys.tables -- specify Correlate_index_ETFs_and_ECON_indices as default database use Correlate_index_ETFs_and_ECON_indices insert into #temp_from_sys_tables_for_multiple_databases -- save table info from default database select name ,create_date ,db_name() [source database] from sys.tables -- specify alter_examples as default database use alter_examples insert into #temp_from_sys_tables_for_multiple_databases -- save table info from default database select name ,create_date ,db_name() [source database] from sys.tables -- display table names in sys.tables select * from #temp_from_sys_tables_for_multiple_databases
The following screenshot shows the first 14 rows from the results set of the preceding script. All these rows are for tables from the master database in the database's instance used for the query. Some tables were copied or created as a part of the SQL Server installation process. Other tables, namely those with a create_date in 2022 and 2023, were created in the master database as part of a custom application.
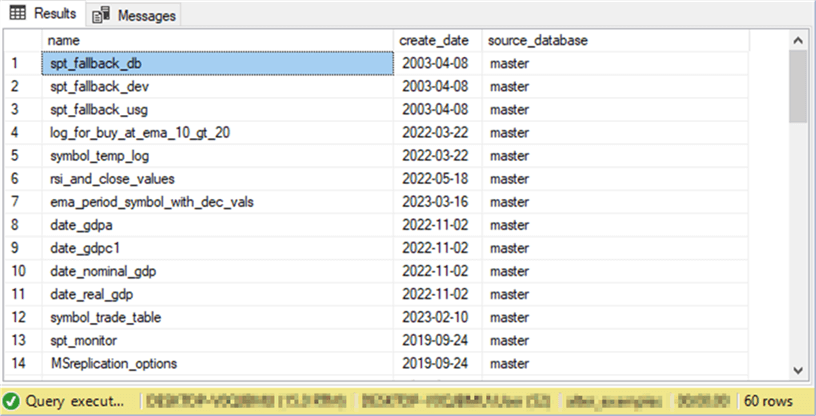
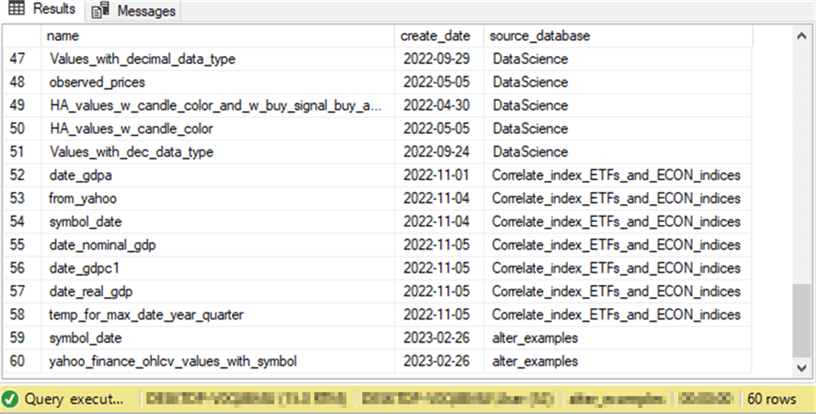
This screenshot shows the last 14 rows in the results set from the preceding script. As you can see, the rows are for tables from three databases – DataScience, Correlate_index_ETFs_and_ECON_indices, and alter_examples. Several of the table names appear in more than one database.
- For example, the date_gdpc1 table name in row 9 of the preceding screenshot and row 56 of the following screenshot.
- Notice that the two versions of the date_gdpc1 table have different create dates – namely, 2022-11-02 in the preceding screenshot and 2022-11-05 in the following screenshot.
- These two screenshots confirm that it is possible to readily perform diagnostic work on the contents of multiple databases through the sys views.
Programmatically Selecting a Subset of Tables Metadata from Different Databases
The results set from the previous section shows how easy it can be to create and populate a temp table with all the sys.tables rows from multiple databases. Commentary on subsets of the results set confirmed that tables with the same name could exist in two or more databases. Even with a relatively small set of just 60 tables, detecting and displaying duplicated tables across two or more databases can be tedious. The objective of this section is to show how simple it is to design and run diagnostic queries that extract subsets of the sys.tables rows derived from multiple databases.
The following brief script shows how to list all table names that occur more than once across all databases in the #temp_from_sys_tables_for_multiple_databases table.
- All the tip does is group and count the rows in the table by name.
- Then, it returns the name of all sys.tables rows with names in more than one database. These are the table names that occur in two or more databases.
-- source: https://www.MSSQLTips.com -- -- display table names that occur more than once across databases select name [table_name_count] from #temp_from_sys_tables_for_multiple_databases group by name having count(*) > 1
Here is the results set from the script. There are 11 table names that appear in more than one database.
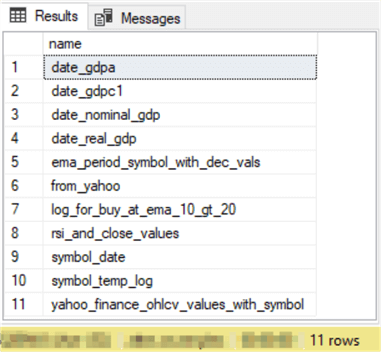
The preceding query is straightforward to code, and its results are valid. However, it does not highlight which databases the duplicate table names appear in. Furthermore, it does not list the table and database names for each pair of duplicated table names. The next script addresses these issues.
- It returns a single row for each instance of a duplicated table name. Duplicated table names are detected by a derived table in an inner query that passes its results set to an outer query.
- The outer query returns the database name for a duplicated table name instance, the create date for the table, and the database name in which the table resides. These three columns are denoted by the asterisk in the select statement of the outer query.
- A group by clause in the inner query groups results set rows by table name.
- Also, a having clause in the inner query restricts the output to table names that appear more than once.
- Finally, an order by clause orders the rows by table name values.
-- source: https://www.MSSQLTips.com -- -- display name, create_date, and source databases -- for duplicated tables across more than 1 database select * from #temp_from_sys_tables_for_multiple_databases where name in ( -- table names that occur more than once across databases select name [table_name_count] from #temp_from_sys_tables_for_multiple_databases group by name having count(*) > 1 ) order by name
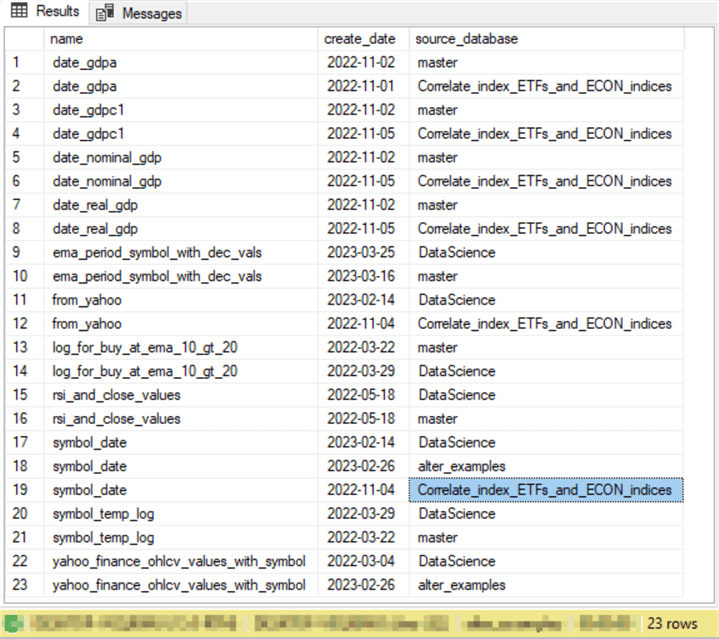
Here is the results set from the preceding query.
- In this case, there are 23 rows in the results set.
- The vast majority of the duplicated table names appear in just two databases.
- For example, rows 1 and 2 show that the date_gdpa table appears in the master and Correlate_index_ETFs_and_ECON_indices databases.
- Rows 22 and 23 show the yahoo_finance_ohlcv_values_with_symbol table name appearing in two databases – namely, DataScience and alter_examples.
- If you scan the results set rows, you can discover that the symbol_date table appears on rows 17, 18, and 19. This indicates that the symbol_date table is in the DataScience, alter_examples, and Correlate_index_ETFs_and_ECON_indices databases.
If there are 60 rows in the #temp_from_sys_tables_for_multiple_databases table, as shown in the preceding section, and there are 23 rows with duplicated table names, as shown in the prior screenshot, then there should be 37 rows from the #temp_from_sys_tables_for_multiple_databases table that appear in just one database. The following script confirms this outcome programmatically.
There are two key differences between this query and the preceding query:
- The having clause restricts results set rows to those with a count(*) value of 1 in the following query, while the preceding query only includes rows with a count(*) value of more than 1.
- Also, the following query does not have a trailing order by name clause. This is because the built-in row order is sufficient for the objective of the query.
-- source: https://www.MSSQLTips.com -- -- list of non-duplicated table names across -- source_database column values -- in #temp_from_sys_tables_for_multiple_databases select * from #temp_from_sys_tables_for_multiple_databases where name in ( -- table names that occur more than once across databases select name from #temp_from_sys_tables_for_multiple_databases group by name having count(*) = 1 )
Here is the results set from the preceding query. The results set contains 37 rows for tables from three different databases – namely, master, DataScience, and Correlate_Index_ETFs_and_ECON_indices.
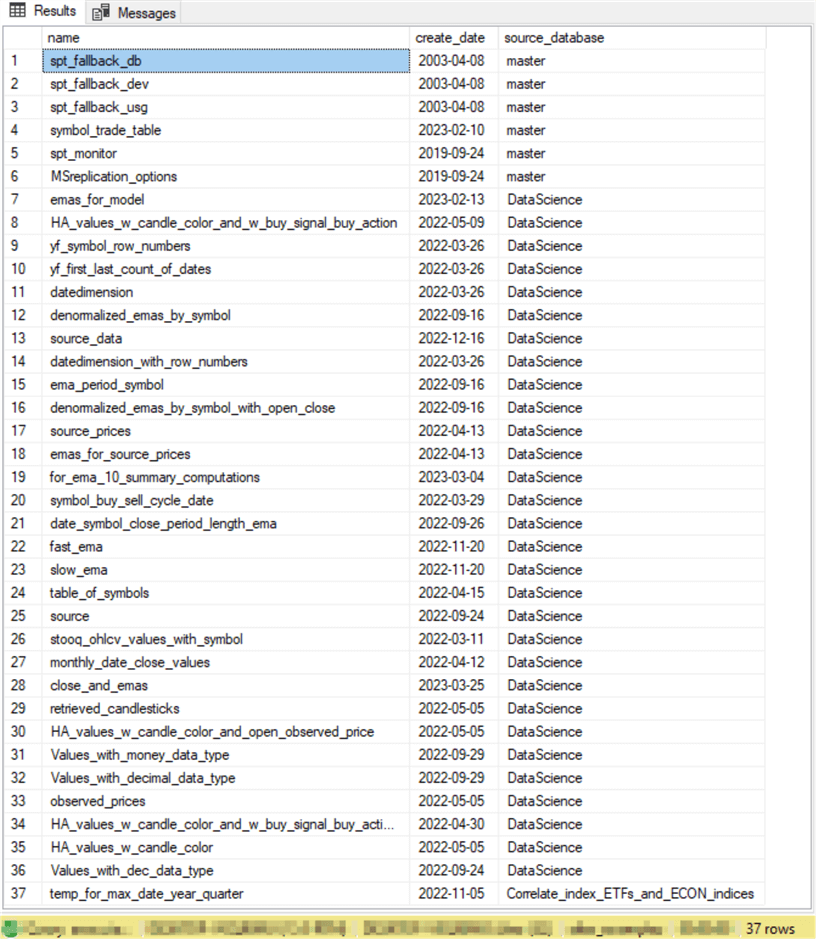
Joining Column Metadata to Table Metadata for a Single Table
This section illustrates with several examples how to join column metadata from sys.all_columns to table metadata from sys.tables. Recall that sys.tables can return metadata for one table per row from the current database. The joined metadata are contained in column values on a row in the results set. You can specify the current database for a script or script segment with a use statement that designates a database.
The sys.all_columns view can return metadata for one column per row in the current database. Recall that the sys.all_columns view is the union of the sys.columns view and the sys.system_columns view.
Just like tables belong to databases, columns belong to tables. Also, any one table can have a variable number of columns associated with it. T-SQL facilitates the joining of columns to tables by object_id metadata values. Each sys.tables row has an object_id column value to uniquely identify the table in a database. Similarly, each sys.all_columns row has an object_id column value to designate the table to which the column belongs. Examples of other metadata for sys.all_columns and sys.tables appear below. All named metadata is from sys.all_columns, except for Max_column_id_used, which is from sys.tables.
- Name is for the column name
- Column_id is for the sequence identifier of a column in a table
- Max_column_id_used is for the largest column_id value in a table
- Is_nullable indicates whether the values within a column can contain null values
- Various other metadata values to denote the type of data in a column
Joining All Columns to Their Tables in a Database
Here is a starter script segment to list all the tables in a database.
- The use statement sets the current database to DataScience
- The select statement returns metadata in three columns:
- The name of the current database referenced by the db_name() function
- The object_id for a table within the database
- The table name within the database
-- source: https://www.MSSQLTips.com -- -- specify DataScience as default database use DataScience -- display database name from db_name() as well as -- name and object_id column values from sys.tables in default database select db_name() [database name] ,object_id [object_id from sys.tables] ,name [table name] from sys.tables
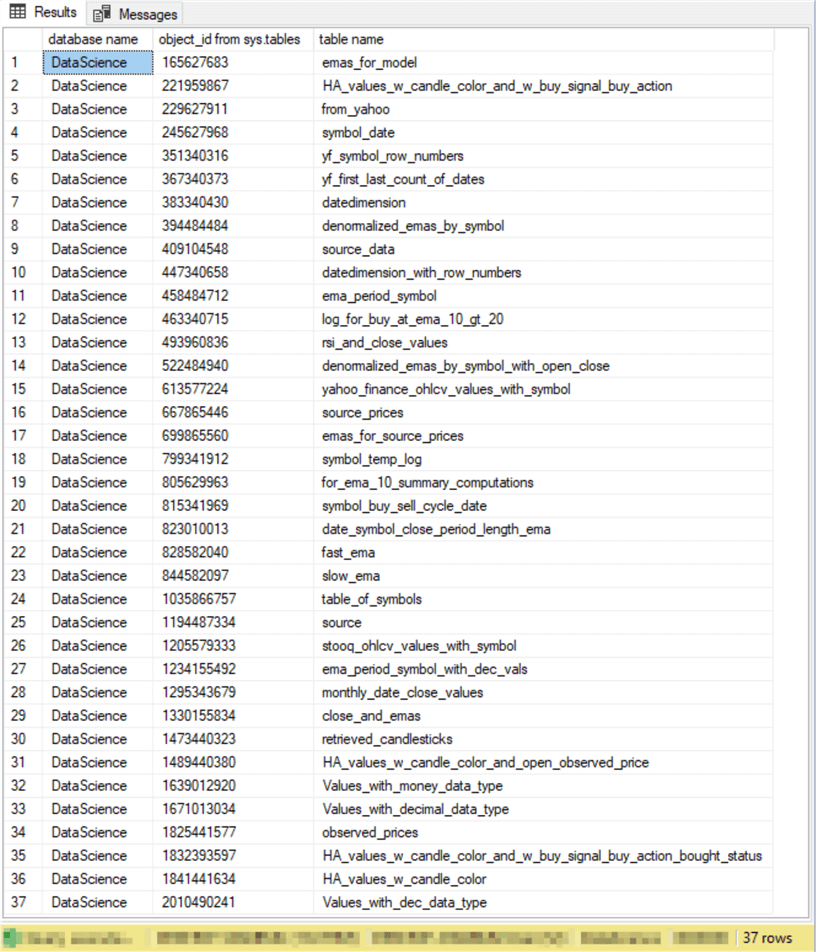
Here is the results set from the preceding script. The results set contains 37 rows – one for each table in the DataScience database.
- The first column value within each row indicates it contains metadata for a table from the DataScience database.
- The second column value is the number value for the object_id of the table on the current row.
- The third column value is the name of the table for the current row.
The next script segment shows how simple it can be to list all the tables with their matching columns from a database.
- This script begins with a use statement to ensure it returns data from the DataScience database. If DataScience were not explicitly designated as the current database, the remaining code would return metadata for whatever other database was the current default database.
- There are seven select list items in the select statement:
- The first column returns the name of the current database with the db_name() function.
- The script returns metadata for all columns in all tables within the DataScience database.
- The second, third, and seventh columns return metadata from sys.tables.
- The fourth, fifth, and sixth columns return metadata from sys.all_columns.
- The from clause in the select statement designates the syntax for the join.
- The first view name in the from clause is sys.all_columns.
- The second view name in the from clause is sys.tables.
- The join operator between the two views implicitly performs an inner join between the two views.
- The on clause after the second view indicates the two views are joined by their object_id values.
-- source: https://www.MSSQLTips.com -- -- specify DataScience as default database use DataScience -- join sys.tables and sys.all_columns by object_id -- returns database name, table name, column name select db_name() [database name] ,tables.object_id [object_id from sys.tables] ,tables.name [table name] ,all_columns.object_id [object_id from sys.all_columns] ,all_columns.name [column name] ,all_columns.column_id ,tables.max_column_id_used from sys.all_columns join sys.tables on all_columns.object_id = tables.object_id
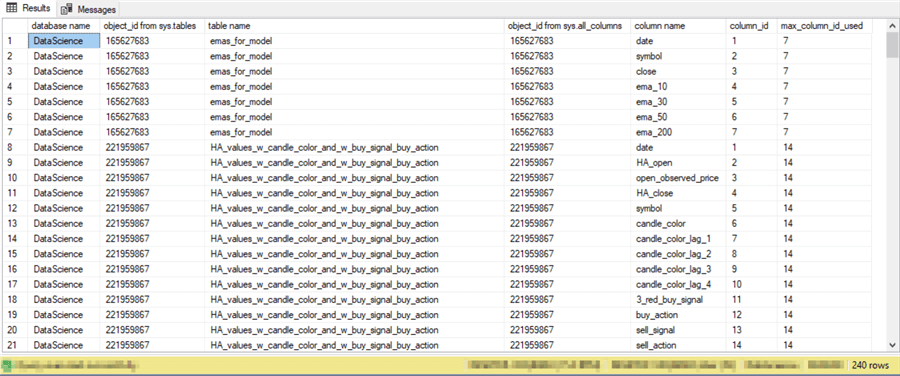
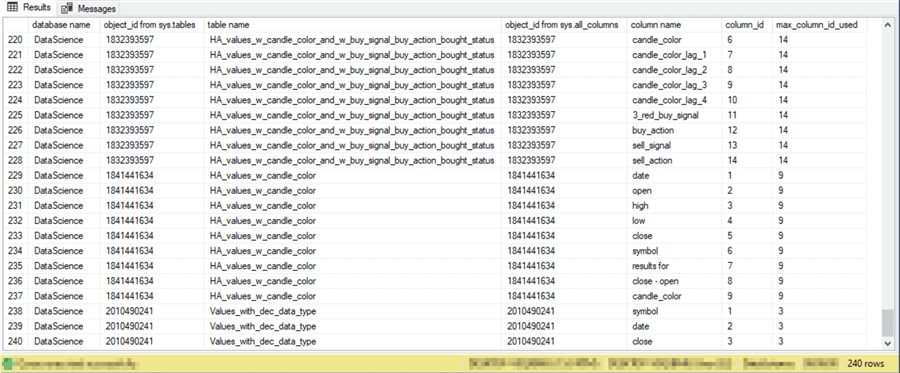
The next pair of screenshots show the first and last 21 rows from the results set. As you can see, there are 240 rows in the results set.
- All the rows in the first column contain a value of DataScience because they show metadata for the DataScience database.
- The second and the fourth columns return object_id values from sys.tables and sys.all_columns, respectively.
- The third column returns the table name for a row of metadata in the results
set.
- Notice that there are successive blocks of rows in the results set with the same table name.
- For example, rows 1 through 7 in the top screenshot show metadata rows from the emas_for_model table.
- In contrast, the last three rows in the second screenshot display metadata from the Values_with_dec_data_type table.
- All the rows for a single table name have the same object_id value in the second and fourth columns.
- The fifth column displays the column names within the table specified by the third column value.
- The sixth column displays a number for the position of a column within a table. The values start at 1 for the left-most column in each table and proceed sequentially through the right-most column.
- The seventh column reveals the number of the right-most column within a
table.
- The emas_for_model table has a right-most column value of 7.
- The Values_with_dec_data_type table has a right-most column value of 3.
Joining sys.all_columns Metadata to a Specified Table in sys.tables
This subsection focuses on joining column and table metadata for a specific SQL Server database. The prior subsection introduces the basics of the join for all columns with all tables in a database. This subsection starts with two examples illustrating two different ways of extracting data from sys.tables for a specific table name. In addition, using the object_id() function in the first two examples reveals how to navigate from a SQL Server table name to a matching object_id value. This subsection ends with an easy-to-follow T-SQL example that joins sys.tables with sys.all_columns to return metadata for a specified SQL Server table.
Here is the script for the subsection with all three examples.
- The first example commences with a use statement for the DataScience database that applies to each code segment; a declare statement defines and populates a local variable name.
- The first select statement specifies in a where clause the table name for which to return metadata.
- The first select statement also introduces two different ways to employ
the object_id keyword
- The first way (tables.object_id) is identical to how it is used in previous examples within this tip. That is, the object_id column is extracted from the sys.tables view
- The second way -- object_id(tables.name) – extracts the column name from the sys.tables view and then passes that name to the object_id() function, which converts the table name to its corresponding object_id numeric value
- The second example builds on the first example by referencing a local variable (@table_name) and assigns a value to it for the specified table. Then, the local variable is referenced in the where clause for the second select statement.
- The third example illustrates a from clause with three reference views:
sys.tables, sys.all_columns, and sys.types.
- The sys.tables and sys.all_columns views are joined by object_id values
- The sys.all_columns and sys.types views are joined by user_type_id
- The sys.types view serves as a lookup source for the names of data type values in a column
- The sys.all_columns view returns the data type attributes for columns, such as max_length, precision, and scale
- The reference to the sys.types view enables the inclusion of a column referenced by their type name instead of a numeric code for their type; this column facilitates the display of data type names for column values
- The is_nullable column in the query's results set displays
values denoting the nullability of a column
- A value of 1 for is_nullable denotes a column in a table that can accept null values
- A value of 0 for is_nullable denotes a column in a table that cannot accept null values
-- source: https://www.MSSQLTips.com -- -- specify DataScience as default database; also, define and -- assign a value to a local variable with a table name use DataScience go declare @table_name sysname = 'symbol_date' -- display name and other selected table attribute values -- from default database for literal table name select db_name() [database name] ,tables.name [table name] ,tables.object_id [looked up table object_id] ,object_id(tables.name) [computed table object_id] ,max_column_id_used from sys.tables where tables.name = 'symbol_date' -- display name and other selected table attribute values -- from default database for local variable with table name select db_name() [database name] ,tables.name [table name] ,tables.object_id [looked up table object_id] ,object_id(tables.name) [computed table object_id] ,max_column_id_used from sys.tables where name = @table_name -- display database, table, and column names -- along with column_id and max_column_id_used -- and finally data type and nullability of columns -- for columns in table with a name matching @table_name value select db_name() [database name] ,tables.name [table name] ,all_columns.name [column name] ,all_columns.column_id ,max_column_id_used ,types.[name] [user_type name] ,all_columns.max_length ,all_columns.precision ,all_columns.scale ,all_columns.is_nullable from sys.tables join sys.all_columns on all_columns.object_id = tables.object_id join sys.types on all_columns.user_type_id = types.user_type_id where tables.name = @table_name
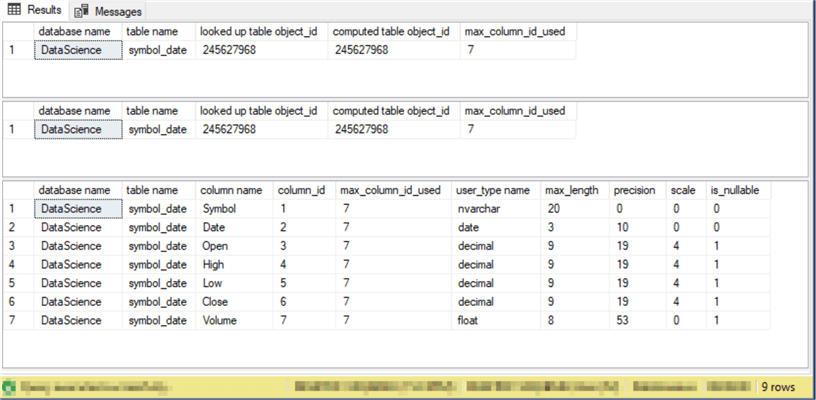
Here are the results sets from the preceding script. Each results set appears in a separate pane.
- The first and second panes are identical because they are derived from code samples that merely illustrate two different ways to extract metadata for the same table
- The third pane drills down on properties, such as data types and nullability, for individual columns in the symbol_date table
Next Steps
The next steps suggested for this tip can take you in at least three directions:
- If you find an example script that addresses a specific metadata query that you need to implement, just update the sample scripts in the tip for the names of metadata for which you need a results set
- If you find a need to redesign a query example in this tip, then update it according to your needs (for example, designate a different database name in a use statement)
- Finally, you can build on your understanding of metadata queries from this tip and the references cited in this tip to create and populate your own library of custom metadata queries






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-06-20
