By: Temidayo Omoniyi | Updated: 2024-07-10 | Comments (6) | Related: > PostgreSQL
Problem
Organizations today are beginning to embrace more open-source technology due to its flexibility and ease of management. The question arises: How can we move all our data from an existing relational database management system (RDBMS) to another? This process should also include all database objects.
Solution
Apache Python PySpark allows data engineers and administrators to manipulate and migrate data from one RDBMS to another with the appropriate JDBC drivers. This approach will save organizations overhead costs when purchasing applications and software for such migration. All that is needed is your Python skills and necessary connectors.
Project Overview
As a data professional, you have been tasked with moving your entire marketing database from a Microsoft SQL Server to a PostgreSQL database. You have also been tasked with maintaining all relationships, constraints, and necessary objects from the previous database to the new one. For this project, the data warehouse designer has provided you with the database Entity Relationship. You must replicate it in the new RDBMS (PostgreSQL database).
Prerequisite
To fully understand this article, I advise you to read our previously released article, Automate ETL Processes with PySpark on a Windows Server. This article covers all the configurations needed for PySpark in a Windows environment and setting up the necessary SQL Server Spark connectors.
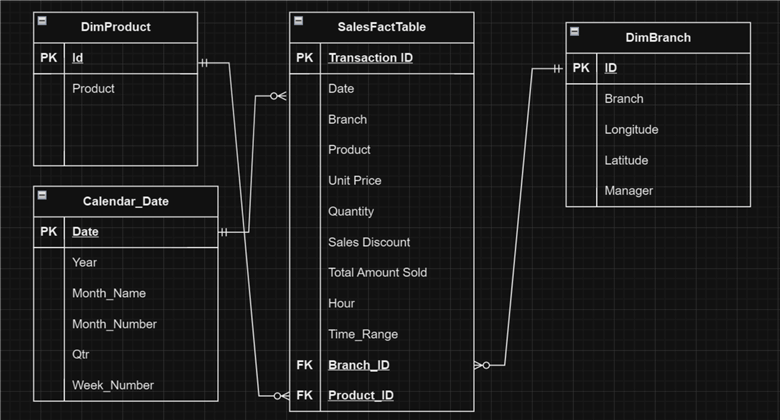
SQL Server Database Entity Relationship Diagram for Marketing Department
Database entity relationships refer to a data point where multiple tables in the database connect. This idea is essential in relational database design.
You have been provided with the database Entity Relationships, which gives you an idea of how the database is structured in the source and what it is expected to be when it reaches its destination, PostgreSQL.
Create a Market Database and Table in the PostgreSQL Database
PostgreSQL is one of the world's leading open-source RDBMSs. It is known for its feature richness, dependability, and conformity to SQL standards.
We need to replicate the SQL Server database in PostgreSQL with all constraints, data types, and relationships accounted for. The following steps should be taken to achieve this.
Step 1: Create a PostgreSQL Database
We need to create a new database in PostgreSQL that will be used to house the entire marketing department data tables.
Expand the server and right-click on the database, then select Create and click Database...
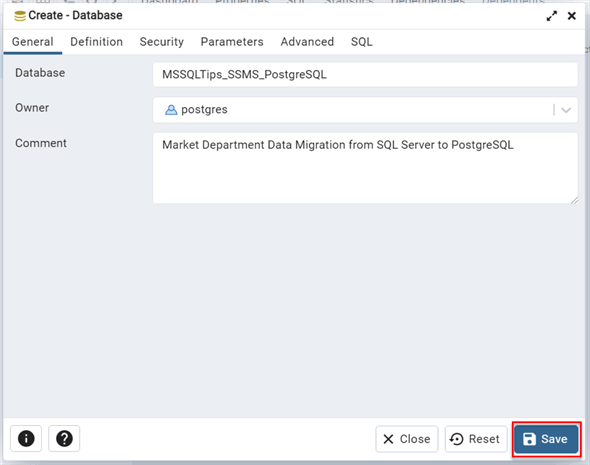
In the new window, provide the new database with the required information from the General settings tab. Leave the rest of the tab at default, then click Save.
Step 2: Create Database Schema
In a database context, a schema acts as a blueprint that defines how data is organized, stored, and interrelated. It outlines the building pieces and their connections like a map might. In the new database created, right-click and select Query Tool. This will open a new window where you can write SQL queries.
Write the query below to create a schema dbo for the Database Owner (Default User).
Create schema dbo
Step 3: Create Database Table and Constraints
We must create all the necessary data tables in the same schema as dbo. These are all the tables currently in SQL Server Management Studio (SSMS) that we want to migrate.
create table dbo.SalesFactTable( "Transaction ID" INT Primary Key not null, Date date, Branch varchar(50), Product varchar(50), "Unit Price" float, Quantity int, "Sales Discount" float, "Total Amount Sold" float, Hour Int, Time_Range varchar(50), Branch_ID INT, Product_ID INT ); Create table dbo.DimBranch( ID int primary key not null, Branch varchar(50), Longitude varchar(50), Lattitude varchar(50), Manager varchar(50) ); Create Table dbo.DimProduct( Id int primary key not null, Product varchar(50) );
After running the query, three empty tables should be created in the dbo schema.

Step 4: Set Relationships and Keys
Before loading the data, we must set all necessary foreign keys and primary relationships from the entity-relationship above. Using the SQL script below, we have added the foreign key constraint to the PostgreSQL table.
The ADD CONSTRAINT fk_salesFact_branch is a new constraint added to the table.
ALTER TABLE dbo.SalesFactTable ADD CONSTRAINT fk_salesFact_product -- Constraint name FOREIGN KEY (product_id) REFERENCES dbo.dimproduct(id); ALTER TABLE dbo.SalesFactTable ADD CONSTRAINT fk_salesFact_branch -- Constraint name FOREIGN KEY (branch_id) REFERENCES dbo.dimbranch(id);
To view the foreign keys constraint created in your PostgreSQL, expand the dbo.SalesFactTable, then broaden the Constraint to fill all constraints associated with the table.
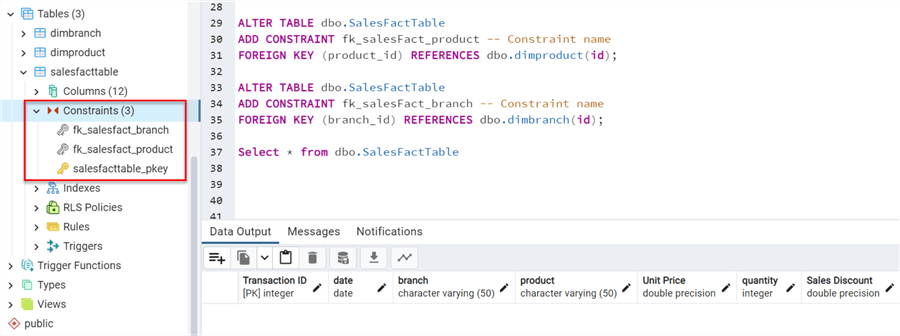
Best Practice for Foreign Key Constraints
To improve both the efficiency and integrity of your database, it is best practice to establish foreign key restrictions before loading data into the database table.
Dimension Modeling Technique in a Database
In data warehousing, dimension tables should typically be loaded before fact tables when data is entered into a database, particularly when utilizing a dimensional modeling technique. This is important in order to:
- Referential Integrity: Fact tables often refer to descriptive attributes found in dimension tables. By loading the dimension tables first, you can ensure that the fact tables are loaded with the appropriate reference data.
- Slowly Changing Dimensions (SCDs): Historical data is frequently included in dimension tables, and certain dimensions may employ SCDs to monitor changes over time.
Set Up PostgreSQL JDBC Driver
The PostgreSQL JDBC drivers can also be referred to as pgJDBC, which serves as a link between PostgreSQL databases and Java programs. It enables Java programs to use regular Java code to connect to and communicate with PostgreSQL databases.
Use the following link to select the pgJBDC version you want to use: Download | Latest Versions. For this article, I am using the Java 8 42.7.3 version.
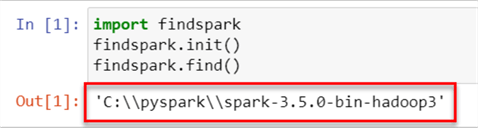
After downloading the Jar file, we must locate where Spark is installed on our Windows machine. Let's use the library findspark, which can provide the exact path of Spark on our local machine.
#Python import findspark findspark.init() findspark.find()
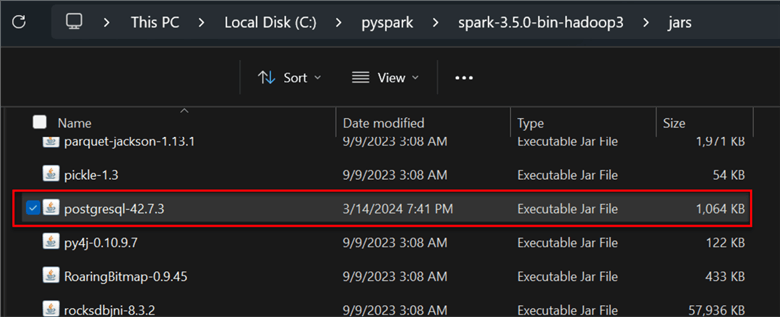
Once you have the Spark directory located, copy and paste the downloaded Jar file into the Spark directory on your Windows machine.
Setup Spark Session and Connect to RDBMS
Now that all necessary configurations have been completed, let's begin by starting Spark sessions and connecting to SSMS.
Let's start by importing all the necessary libraries for this session.
#Python import pyspark from pyspark.sql import SparkSession from pyspark import SparkContext, SparkConf
Initialize a SparkSession object in PySpark, the entry point to programming with Spark.
#Start spark session
spark = SparkSession.builder.appName("SSMS_to_PostgreSQL").getOrCreate()
Set Login Credential Security Using Python-dotenv
The Python-dotenv library prevents sensitive information, like passwords or API keys, from inadvertently becoming public within your code. The previous article explained how to pip install python-dotenv, the library on your Windows machine, and load it to your Python Notebook.
Set .env File. Let's create a .env file on your Windows machine in the same directory as your Python Notebook. The .env file will be used to house all credentials and sensitive information you do not want to write directly to your code.
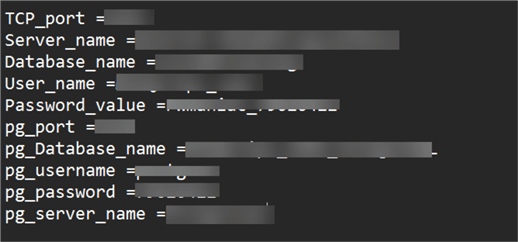
Import all necessary libraries for Python-dotenv in your notebook.
from dotenv import load_dotenv, dotenv_values import os # Load environment variables from the .env file load_dotenv()
Connect PySpark to SQL Server
Using the code below, create the necessary URL and SQL Server properties to connect to SQL Server using PySpark.
# Define SQL Server connection properties
sql_server_url = f"jdbc:sqlserver://{os.getenv('Server_name')}:{os.getenv('TCP_port')};databaseName={os.getenv('Database_name')}"
sql_server_properties = {
"user": os.getenv("User_name"),
"password": os.getenv("Password_value"),
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
Read Table in SQL Server
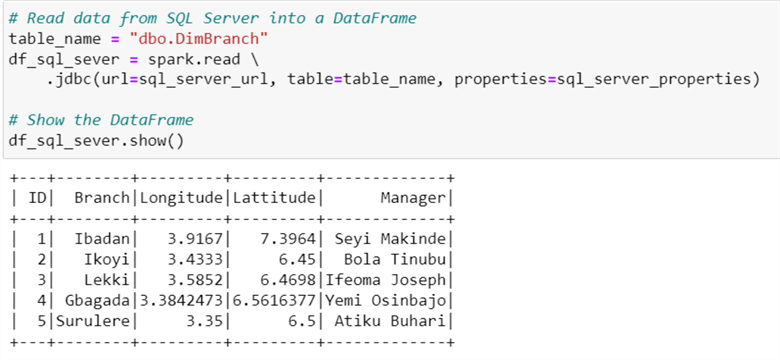
Now that we have successfully connected to SQL Server, let's view the table we want to move to PostgreSQL Server database.
# Read data from SQL Server into a DataFrame table_name = "dbo.DimBranch" df_sql_sever = spark.read .jdbc(url=sql_server_url, table=table_name, properties=sql_server_properties) # Show the DataFrame df_sql_sever.show()
Connect PySpark to PostgreSQL Using JDBC
We downloaded the necessary JDBC drivers to connect PySpark to the PostgreSQL database. Now, let's connect to the PostgreSQL database using PySpark.
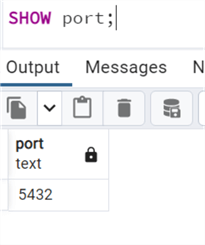
You will need the PostgreSQL port number, which refers to the network port where the database server listens for incoming connections.
–SQL SHOW port;
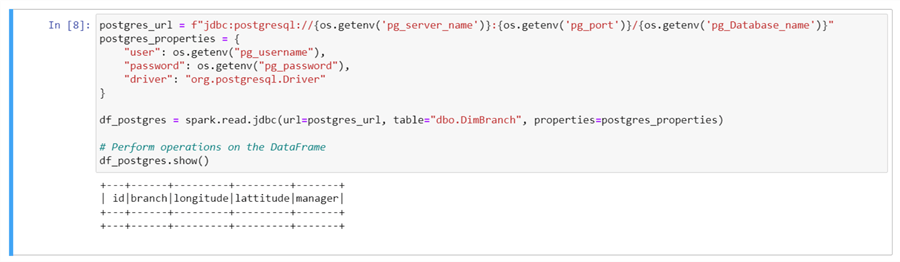
Now that you have the port number for PostgreSQL, head back to your Python Notebook and write the following code to connect with the PostgreSQL database. You will notice the output table for dbo.DimBranch is empty because we haven't moved any data to it.
postgres_url = f"jdbc:postgresql://{os.getenv('pg_server_name')}:{os.getenv('pg_port')}/{os.getenv('pg_Database_name')}"
postgres_properties = {
"user": os.getenv("pg_username"),
"password": os.getenv("pg_password"),
"driver": "org.postgresql.Driver"
}
df_postgres = spark.read.jdbc(url=postgres_url, table="dbo.DimBranch", properties=postgres_properties)
# Perform operations on the DataFrame
df_postgres.show()
Move a Single Table from SQL Server to PostgreSQL
Write the SQL Server DataFrame to PostgreSQL in your Python Notebook using the line of code below.
The following parameters are needed to write to PostgreSQL:
- URL: Specifies the JDBC (JAVA Database Connection) URL of the PostgreSQL database to which the data will be written.
- Table: This is the PostgreSQL database table we created earlier.
- Mode: Specifies the write mode at which data will be written to the PostgreSQL table. The mode was set to Append, meaning that the new data will be appended if there is existing data in the database table. The Overwrite mode can also be used.
- Properties: This is usually a dictionary containing the database credentials, such as username, password, and driver, used in PostgreSQL.
df_sql_sever.write.jdbc(url=postgres_url, table="dbo.DimBranch", mode="append", properties=postgres_properties) # Stop SparkSession spark.stop()
After writing to PostgreSQL, head to your PostgreSQL database system and run the SELECT ALL statement.
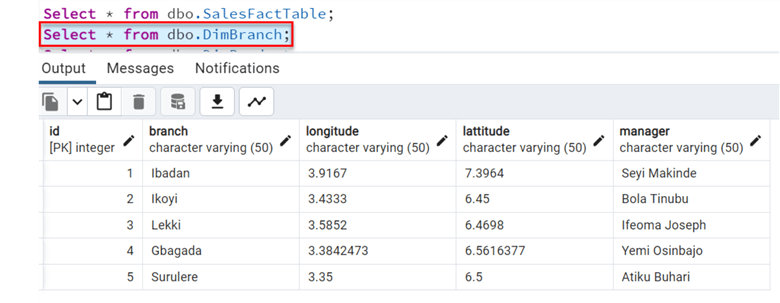
You will notice the data have been migrated successfully to the PostgreSQL database.
Move Multiple Tables
In a real-world scenario, you are not expected to move tables one after the other in a database. You are expected to dynamically move all the tables from one database to another database simultaneously.
The following steps should be followed to achieve this:
Step 1: Import All Necessary Libraries
Import all the necessary libraries needed to perform this operation. We will deal with multiple schema and datatypes to ensure the same data from SQL Server to what is set to PostgreSQL database.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DateType, TimestampType, FloatType, DoubleType from pyspark.sql.types import StructField from pyspark.sql.functions import col
Step 2: Create Table Schema
The table schema is needed to ensure the right datatype format is written to the PostgreSQL database.
table_schemas = {
"dbo.DimBranch": StructType([
StructField("ID", IntegerType(), False),
StructField("Branch", StringType(), True),
StructField("Longitude", StringType(), True),
StructField("Lattitude", StringType(), True),
StructField("Manager", StringType(), True),
]),
"dbo.DimProduct": StructType([
StructField("Id", IntegerType(), False),
StructField("Product", StringType(), True),
]),
"dbo.SalesFactTable": StructType([
StructField("Transaction ID", IntegerType(), False),
StructField("Date", DateType(), True),
StructField("Branch", StringType(), True),
StructField("Product", StringType(), True),
StructField("Unit Price", FloatType(), True),
StructField("Quantity", IntegerType(), True),
StructField("Sales Discount", FloatType(), True),
StructField("Total Amount Sold", FloatType(), True),
StructField("Hour", IntegerType(), True),
StructField("Time_Range", StringType(), True),
StructField("Branch_ID", IntegerType(), True),
StructField("Product_ID", IntegerType(), True),
])
}
After creating the schema, make a list to house it. We will use it as we develop the code.
# List of table names to move table_names = list(table_schemas.keys())
Step 3: Iterate Through Each Table
This code block starts a loop that iterates through each table name in the table_names list. It will loop through the table schema and write the data from SQL Server to PostgreSQL.
# Loop Through
for table_name in table_names:
# Read data from SQL Server table with specified schema
sql_server_df = spark.read.jdbc(url=sql_server_url, table=table_name, properties=sql_server_properties)
# Convert StructType to a list of tuples
schema_tuples = [(field.name, field.dataType) for field in table_schemas[table_name]]
# Cast DataFrame columns to enforce schema
for column, data_type in schema_tuples:
sql_server_df = sql_server_df.withColumn(column, col(column).cast(data_type))
# Write data to PostgreSQL table with mode "append."
sql_server_df.write.jdbc(url=postgres_url, table=table_name, mode="append", properties=postgres_properties)
# Stop SparkSession
spark.stop()
Step 4: Confirm Migration
After running the code, confirm the data was moved successfully.
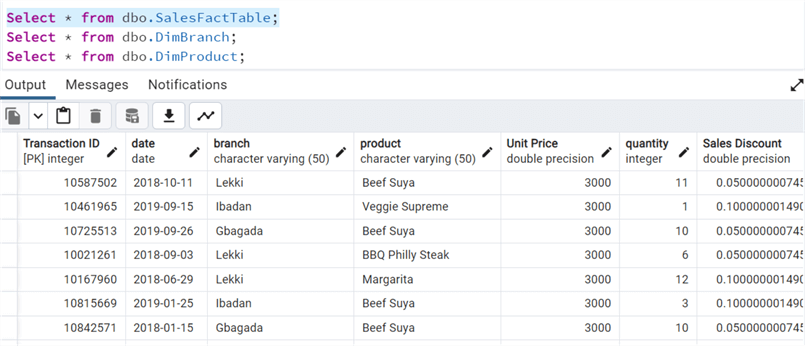
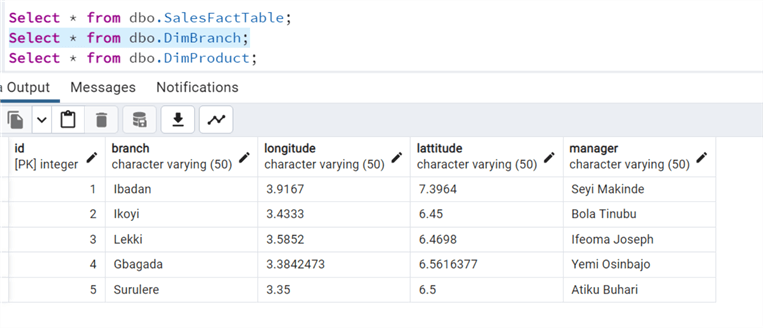
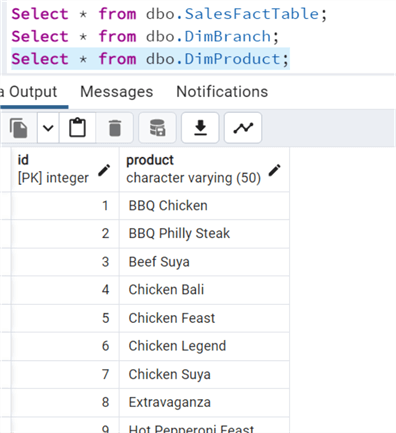
Create Calendar Table
The entity-relationship has a calendar table obtained from the dbo.SalesFactTable. We will create a calendar and a relationship with the fact table in the PostgreSQL database table.
Step 1: Determine the Maximum and Minimum Date from the Fact Table
Every calendar has a start and end date. To achieve this, we will need to pick the values from the dbo.SalesFactTable.
SELECT
MIN("date") AS min_date,
MAX("date") AS max_date
INTO
calendar_temp
FROM
dbo.SalesFactTable;
Step 2: Create a Temporary Table (Temp) and Generate a Series of Dates
We need to generate a series of dates between the maximum and minimum date and set one day between them in the temp table.
CREATE TEMP TABLE date_series AS
SELECT
generate_series(min_date::date, max_date::date, interval '1 day') AS calendar_date
FROM
calendar_temp;
Step 3: Extract the Required Column with Datatypes
We need to extract the required columns and put in the required datatypes.
Let's start by creating a Calendar table.
CREATE TABLE dbo.calendar (
calendar_date DATE primary key,
year INTEGER,
month_name TEXT,
month_number INTEGER,
quarter INTEGER,
week_number INTEGER
);
After creating the calendar table, we will insert the extracted values from the calendar_date column.
INSERT INTO dbo.calendar (calendar_date, year, month_name, month_number, quarter, week_number)
SELECT
calendar_date,
EXTRACT(year FROM calendar_date),
TO_CHAR(calendar_date, 'Month'),
EXTRACT(month FROM calendar_date),
EXTRACT(quarter FROM calendar_date),
EXTRACT(week FROM calendar_date)
FROM
date_series;
Step 4: Drop Unwanted Tables (Optional)
This step is optional. We can drop the unwanted table now that we have created the calendar table.
DROP TABLE IF EXISTS calendar_temp; DROP TABLE IF EXISTS date_series;
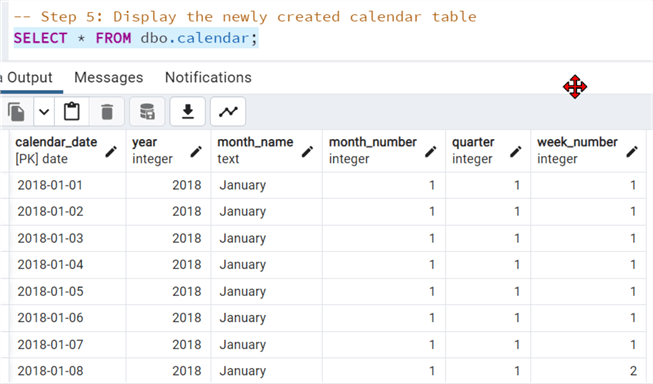
Step 5: View Calendar Table
Use SELECT All to check the table we just created.
SELECT * FROM dbo.calendar;
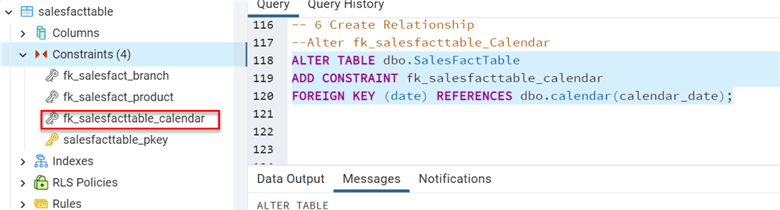
Step 6: Create a Relationship Constraint
Let's create a relationship between the dbo.SalesFactTable and the dimension calendar table.
ALTER TABLE dbo.SalesFactTable ADD CONSTRAINT fk_salesfacttable_calendar FOREIGN KEY (date) REFERENCES dbo.calendar(calendar_date);
Optimize and Improve Database Performance
Multiple techniques exist for improving database performance, but in this article, we will focus on indexing in the PostgreSQL database.
Indexing in Database
Indexing in the database is a technique used to increase the speed at which data is retrieved for specific queries.
Some of the benefits of indexing a database table include:
- Enhanced Query Performance: Indexing works more along the lines of a specialty filing system. The relational database can quickly locate relevant records because ordered structures based on columns are constructed during query execution. Much faster queries are those that involve filtering, sorting, or merging data according to the indexed columns.
- Efficient Data Retrieval: With the introduction of index databases, you do not need to search the entire table to retrieve information/rows matching a query condition. Indexes offer a more focused strategy.
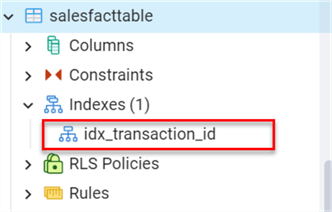
Let's create an Index on the Transaction ID of the dbo.SalesFactTable.
Use the query below to generate an index in SQL.
CREATE INDEX idx_transaction_id ON dbo.SalesFactTable ("Transaction ID");
Conclusion
In this article, we covered how to dynamically migrate multiple data tables from SQL Server to PostgreSQL database tables and discussed configuring PostgreSQL JDBC drivers for PySpark to interact with the database.
We covered best practices for data modeling and improving database performance by creating an index and how it helps improve the query speed performance of the database. All constraints and relationships were created between all tables to represent the entity-relationship of the database.
Finally, we demonstrated the creation of a calendar table in PostgreSQL. This table, which takes the maximum and minimum data from the dbo.SalesFactTable, provides a more comprehensive and accurate representation of the data.
Next Steps
- Download materials for this article
- Connecting PostgreSQL with SQLAlchemy in Python
- Connecting to SQL Database using SQLAlchemy in Python
- Connect MySQL to sqlAlchemy In python
- How to Create SQL Server Objects Programmatically with SQL Alchemy for Python
- Using Python with T-SQL






About the author
 Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience.
Temidayo Omoniyi is a Microsoft Certified Data Analyst, Microsoft Certified Trainer, Azure Data Engineer, Content Creator, and Technical writer with over 3 years of experience. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-07-10
