By: Ken Simmons | Updated: 2022-09-30 | Comments (43) | Related: 1 | 2 | > Functions System
Problem
Many times people come across the SQL COALESCE function and think that it is just a more powerful form of the SQL ISNULL function. In actuality, I have found SQL COALESCE to be one of the most useful functions with the least documentation. In this tip, I will show you the basic use of SQL COALESCE and also some features you probably never knew existed.
Solution
Let's start with the documented use of SQL COALESCE. According to MSDN, COALESCE returns the first non-null expression among its arguments.
Basic SQL COALESCE Statement
For example, this wiill return the current date. It bypasses the NULL values and returns the first non-null value.
SELECT COALESCE(NULL, NULL, NULL, GETDATE())
Using COALESCE to Pivot SQL Data
If you run the following statement against the AdventureWorks database:
SELECT Name FROM HumanResources.Department WHERE (GroupName = 'Executive General and Administration')
You will come up with a standard result set such as this.
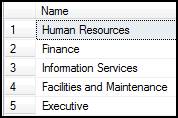
If you want to pivot the data, so it is all in one row you could run the following command.
DECLARE @DepartmentName VARCHAR(1000) SELECT @DepartmentName = COALESCE(@DepartmentName,'') + Name + ';' FROM HumanResources.Department WHERE (GroupName = 'Executive General and Administration') SELECT @DepartmentName AS DepartmentNames
This gives this result set.
Using SQL COALESCE to Execute Multiple SQL Statements
Once you can pivot data using the coalesce statement, it is now possible to run multiple SQL statements by pivoting the data and using a semicolon to separate the operations.
Let's say you want to find the values for any column in the Person schema that has the column name "Name". If you execute the following script it will give you just that.
DECLARE @SQL VARCHAR(MAX)
CREATE TABLE #TMP
(Clmn VARCHAR(500),
Val VARCHAR(50))
SELECT @SQL=COALESCE(@SQL,'')+CAST('INSERT INTO #TMP Select ''' + TABLE_SCHEMA + '.' + TABLE_NAME + '.'
+ COLUMN_NAME + ''' AS Clmn, Name FROM ' + TABLE_SCHEMA + '.[' + TABLE_NAME +
'];' AS VARCHAR(MAX))
FROM INFORMATION_SCHEMA.COLUMNS
JOIN sysobjects B ON INFORMATION_SCHEMA.COLUMNS.TABLE_NAME = B.NAME
WHERE COLUMN_NAME = 'Name'
AND xtype = 'U'
AND TABLE_SCHEMA = 'Person'
PRINT @SQL
EXEC(@SQL)
SELECT * FROM #TMP
DROP TABLE #TMP
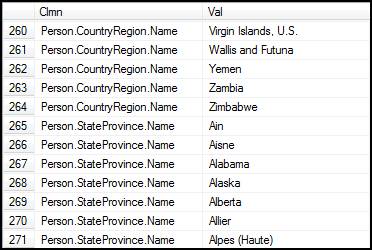
Here is the command it generated.
INSERT INTO #TMP Select 'Person.PhoneNumberType.Name' AS Clmn, Name FROM Person.[PhoneNumberType]; INSERT INTO #TMP Select 'Person.AddressType.Name' AS Clmn, Name FROM Person.[AddressType]; INSERT INTO #TMP Select 'Person.StateProvince.Name' AS Clmn, Name FROM Person.[StateProvince]; INSERT INTO #TMP Select 'Person.ContactType.Name' AS Clmn, Name FROM Person.[ContactType]; INSERT INTO #TMP Select 'Person.CountryRegion.Name' AS Clmn, Name FROM Person.[CountryRegion];
Here is the result set.
Kill Multiple SQL Sessions using SQL COALESCE
My personal favorite is being able to kill all the transactions in a database using three lines of code.
If you have ever tried to restore a database and could not obtain exclusive access, you know how useful this can be.
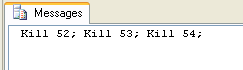
DECLARE @SQL VARCHAR(8000)
SELECT @SQL=COALESCE(@SQL,'')+'Kill '+CAST(spid AS VARCHAR(10))+ '; '
FROM sys.sysprocesses
WHERE DBID=DB_ID('AdventureWorks')
PRINT @SQL --EXEC(@SQL) Replace the print statement with exec to execute
This will give you a result set such as the following.
Next Steps
- Whenever I think I may need a cursor, I always try to find a solution using COALESCE first.
- I am sure I just scratched the surface on the many ways this function can be used. Go try and see what all you can come up with. A little innovative thinking can save several lines of code.
- See related articles:






About the author
 Ken Simmons is a database administrator, developer, SQL Server book author and Microsoft SQL Server MVP.
Ken Simmons is a database administrator, developer, SQL Server book author and Microsoft SQL Server MVP.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-09-30
