By: Koen Verbeeck | Updated: 2024-01-02 | Comments | Related: > Data Quality Services
Problem
Data quality is a topic that concerns most businesses, especially when it comes to verifying data. When you have user input, it's important to check that the entered data is correct. Studies show millions of dollars are spent fixing data quality issues. Not trying to fix them can cost businesses even more, as indicated by Gartner, who estimates "poor data quality to be responsible for an average of $15 million per year in losses".
How can we quickly create an effective data quality solution in an ETL tool like SSIS without spending too much time and money on development?
Solution
Real World Data Quality
A challenging area of data quality issues is address parsing and validation. Addresses all over the world can have multiple formats. Let's take the example of the Microsoft Headquarters. Its official address is "One Microsoft Way; Redmond; Washington; 98052-6399". However, someone might write this as "1 Microsoft Way, Redmond, Washington 98052-6399". Someone not from the USA might switch the order of the numbers. In Belgium, we would write the address like this: "Microsoft Way 1, 98052-6399 Redmond, Washington". These are all valid addresses, written in different formats. Failing to parse and validate addresses effectively can result in business losses such as returned packages, poor decision-making, or inefficient (and thus expensive) marketing campaigns.
Build vs. Buy - Data Quality Tools
Creating a home-grown solution for data quality is difficult since there are many edge cases — as presented in the example above —and many cultural formats to consider. Trying to tackle this yourself can lead to many hours spent developing a solution that might not even have accurate results. As a developer using Integration Services (SSIS) as an ETL tool, it's often difficult (or even impossible) to create an effective data quality solution. Out-of-the-box, SSIS has few components available to support data quality efforts. You have the profiling task, but this does not help you to check if a supplied address exists (not to mention this task is hard to automate and hasn't seen an update in a decade). There are also some fuzzy components that might help with some deduplicating or lookups. The Fuzzy Lookup might be interesting to match slightly incorrect typed words with a reference set. For example, "Beglium" can be matched with "Belgium". But again, it is not able to tell you that an address doesn't exist or give you extra information such as longitude and latitude for an existing address. Furthermore, to use the Fuzzy components you need SQL Server Enterprise edition.
T-SQL Data Validation
The same is true for trying to write a parsing script in T-SQL. The SQL language is not rich enough to tackle difficult data quality issues. For example, what if you need to parse the names of individuals? How would one write a SQL script that can parse "Koen Verbeeck", "Verbeeck Koen", "Verbeeck, Koen" and "Mr. Koen Verbeeck"? It's not impossible, as the tip Name Parsing with SQL Server Functions and T-SQL Programming shows. However, you usually have to make some assumptions about the format the names arrive in, which is not always possible, especially with manual user input.
The Data Quality Solution
Melissa Data has several data quality components available that can be integrated into SSIS packages. The biggest advantage is that you don't have to create your own homegrown data quality solution; you can immediately start working with your data, saving you valuable time and money. Let's look at how we can tackle the issue of address parsing using the Global Verify component. This component can parse addresses from around the world but can also verify if they are correct.
Parsing and Validating Addresses
We are using the following sample data:
SELECT Address = 'One Microsoft Way; Redmond; Washington; 98052-6399' UNION ALL SELECT Address = 'One Microsoft Way Redmond Washington 98052-6399' UNION ALL SELECT Address = 'One Microsoft Way Washington 98052-6399' UNION ALL SELECT Address = 'One Microsoft Way; Redmond; Washington; 98052' UNION ALL SELECT Address = 'Microsoft Way 1; Redmond; Washington; 98052' UNION ALL SELECT Address = '1 Microsoft Way; Redmond; Washington; 98052-6399' UNION ALL SELECT Address = 'Microsoft Way 1, 98052-6399 Redmond, Washington' UNION ALL SELECT Address = 'Microsoft Way; Redmond; Washington; 98052-6399' UNION ALL SELECT Address = '1600 Amphitheatre Parkway Mountain View, CA 94043, USA' UNION ALL SELECT Address = 'PO Box 682, Wilton, New Hampshire, 03086, United States' UNION ALL SELECT Address = '518 Central Way, Kirkland, WA 98033, United States';
Consider this cleaner syntax:
SELECT [Address] FROM (VALUES
('One Microsoft Way; Redmond; Washington; 98052-6399'),
('One Microsoft Way Redmond Washington 98052-6399'),
('One Microsoft Way Washington 98052-6399'),
('One Microsoft Way; Redmond; Washington; 98052'),
('Microsoft Way 1; Redmond; Washington; 98052'),
('1 Microsoft Way; Redmond; Washington; 98052-6399'),
('Microsoft Way 1, 98052-6399 Redmond, Washington'),
('Microsoft Way; Redmond; Washington; 98052-6399'),
('1600 Amphitheatre Parkway Mountain View, CA 94043, USA'),
('PO Box 682, Wilton, New Hampshire, 03086, United States'),
('518 Central Way, Kirkland, WA 98033, United States')
) AS AddressSamples([Address])
It has the Microsoft headquarters address written in a couple of different ways, the headquarters of Google, a PO box, and the address of some random shop in the vicinity of Microsoft.
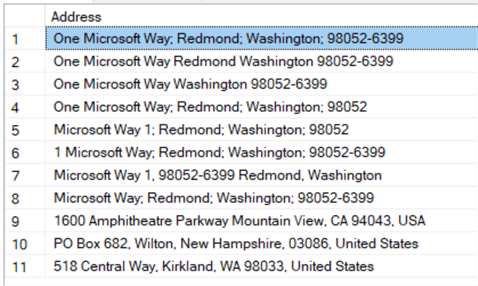
Some addresses have the country listed but spelled either as USA or as the United States. In an SSIS package, we add a data flow and a source component to read the sample data. Then we can add the Melissa Data Global Verify component. I added a multicast at the end so I could inspect the results of the transformation using a data viewer.
The component itself is easy to configure. There are multiple tabs – it can handle name and address parsing, email and phone validation all at once – but we're only interested in the address tab.
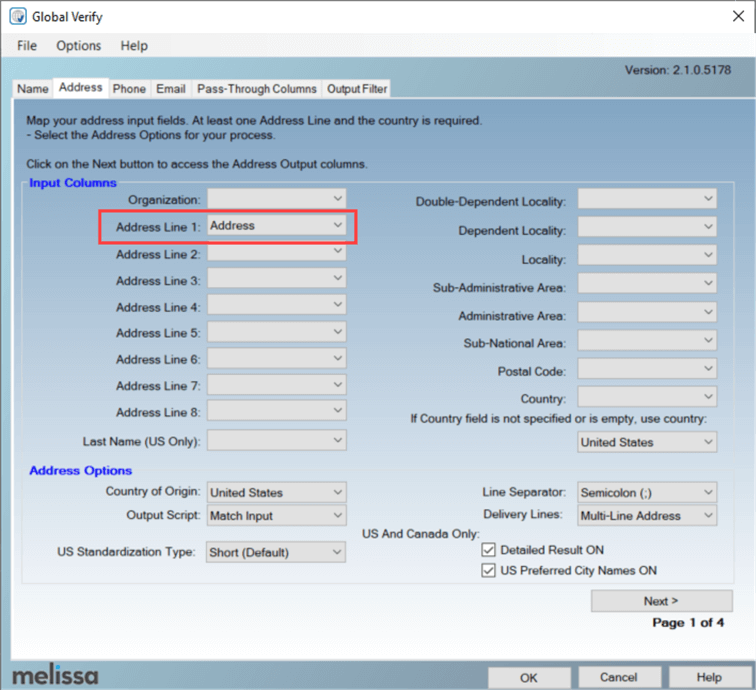
As the input column, we have a single address line. Since we don't have an extra field for the country, we specify the United States as the default. On the next screen, we can configure all of the output columns.
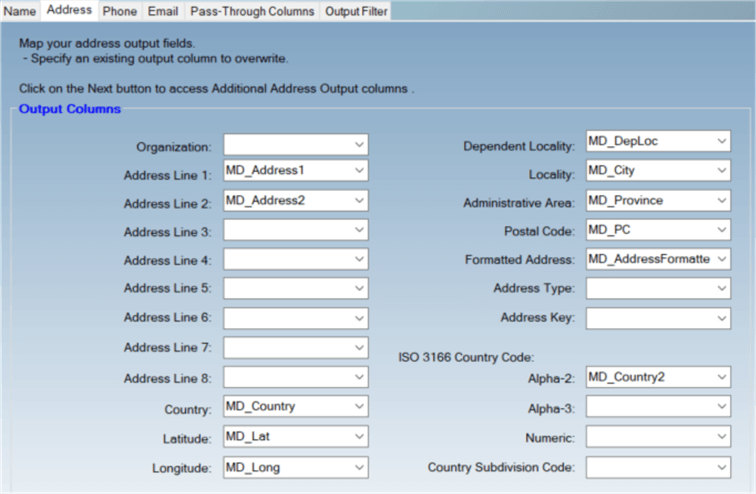
The transformation will read the address, parse it, and if it is validated, it can split the results into many different address fields. Depending on how well an address can be verified, you can add even more extra information to the output, as we can see in the next two screens:
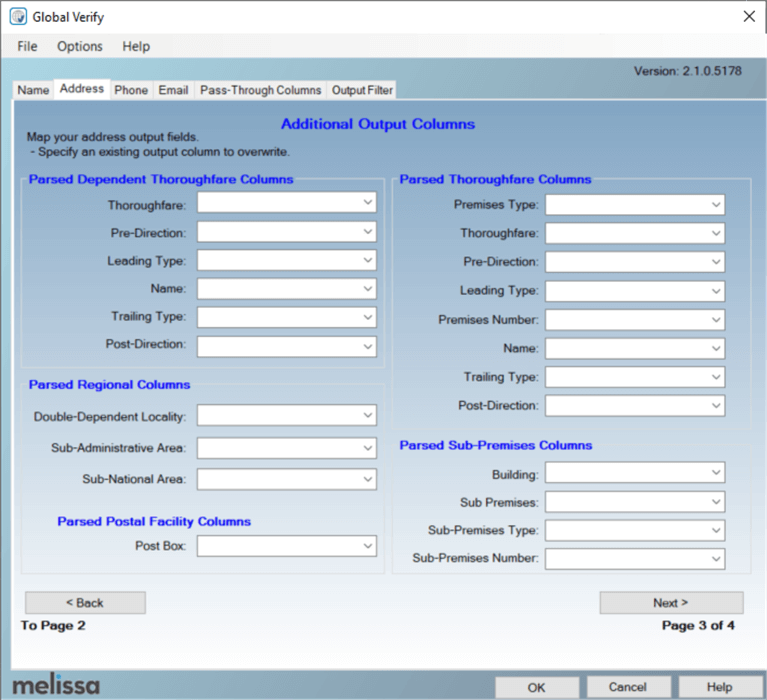
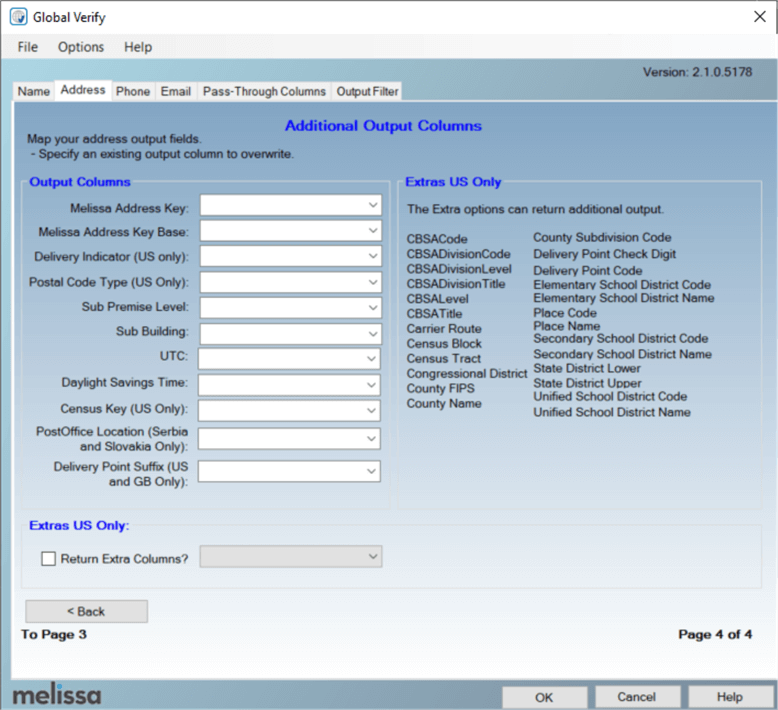
The availability of this information depends on the country you're using. The US and Canada have the most detailed info.
Each parsed address will get one or more result codes. These codes can indicate if information was changed or added or if an error occurred. There will also be a result code specifying to what precision the address could be verified. This can be the premises itself, but also the locality level or the administrative area. For example, if a house number was missing from the address, Melissa could not verify the address to the premises level but only to the street (thoroughfare). In that case, the address will be partially verified.

The result codes will be listed in a single column called MD_Results. A useful feature is the capability to create multiple outputs using the result codes. We can, for example, create an output for the fully verified addresses (which means we're 100% certain we can send mail to them); another output for partially verified addresses, which might need some manual intervention; and a final output for all the addresses that generated an error.
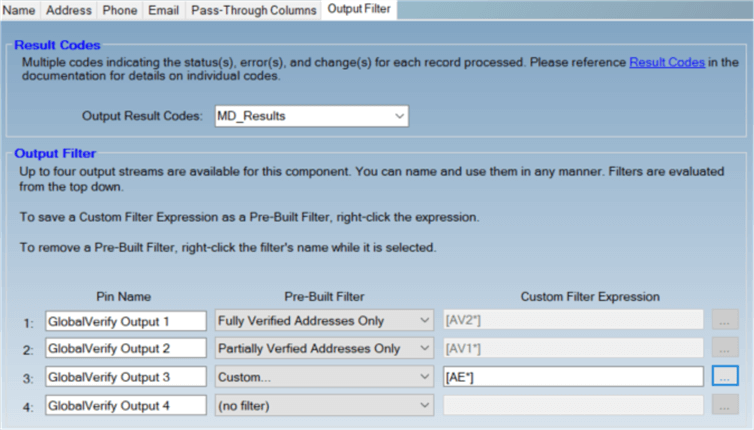
Let's run the SSIS package and see what results we get from our sample data.
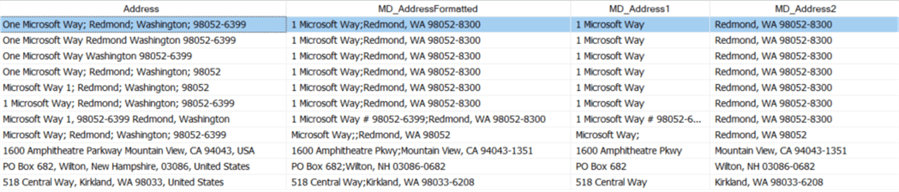
Most Microsoft headquarters addresses were parsed correctly, except the one where the postal code was written before the state (as we would do in Belgium). However, Melissa still detected the address is from the Redmond, Washington area. The address missing a house number is not fully verified. As a result, the "plus 4" part of the ZIP code is dropped.
The other addresses were parsed and verified correctly. For all other addresses, the "plus 4" part was added to the ZIP code. When we look at the additional output columns, we can see we get nicely formatted data out of the addresses.
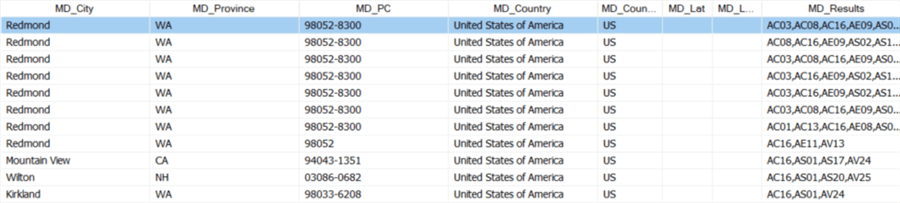
At the end, we have the MD_Results column with all the result codes. The transformation itself allows you to define only four outputs, but you can add extra if you include a conditional split and search for specific result codes yourself.
Some of the result codes returned:
- AV14: partially verified to the premises level. This is returned for most of the Microsoft addresses. I suspect this has something to do with the large Microsoft campus, which spans multiple "plus 4" parts of the ZIP code.
- AE09: an error code saying the sub-premises level is missing. This is again because of the largeness of the Microsoft campus. None of the addresses specify an exact building (there are many buildings at the headquarters).
- AC03: locality changed or added. This is when the "plus 4" of the zip code is added or changed.
- AS17: for the US only. The address is classified as not receiving mail by the USPS. A third party may deliver though. This is again for the Microsoft addresses since no building is specified. This is a very interesting result code, as it may indicate if a mailing will arrive or not. The fully verified addresses get a result code AS01, which means "valid and deliverable."
- AE11: premises number missing.
A great benefit of the Melissa Data tools is that they can return more information than can be found in the input. For example, I've parsed a couple of addresses in Belgium and asked for the longitude and latitude as well.
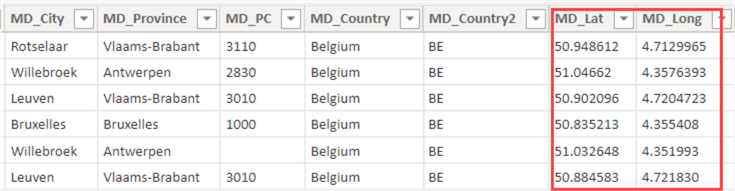
Having both these columns makes it easier to plot data on a map in Power BI.
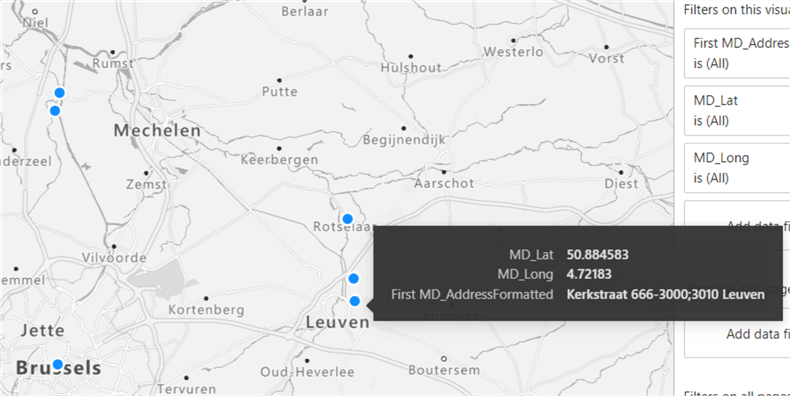
If an address cannot be fully verified, Melissa Data will return an approximate location.
Conclusion
As you can see, with minimal effort we were able to configure a data quality solution capable of parsing and validating addresses efficiently, without writing a single line of code. The SSIS data quality components by Melissa Data are easy to install and configure. Not only can they parse an address into its individual components and verify the address to the individual premises level, but they can also enrich your dataset with information about the address itself.
Having such a data quality solution will allow you to save considerably on development costs as well as the cost of bad data quality (fewer returned mailings or lost invoices, for example).
Next Steps
- More information about the Melissa Data Quality solutions for SSIS.
- Improve the Data Quality for Healthcare, Clinical and Life Sciences Projects with Melissa Informatics
- Improve Data Quality for SQL Server Reporting with Melissa Data Solutions
- There are a couple of free on-demand webinars available on data quality:
- Improve SQL Server Data Quality in SSIS
- Simplifying and Centralizing Universal Data Quality in SSIS
- Solving Issues Caused by Bad Address Data Quality
- Contact Data Quality - From Start to Finish
- Cleaning, Validating and Enhancing the SQL Server Data Warehouse Contact Dimension and its accompanying tip: Microsoft SQL Server Data Warehouse Data Quality, Cleansing, Verification and Matching
About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2024-01-02