By: Rick Dobson | Updated: 2023-11-20 | Comments | Related: > Python
Problem
Please demonstrate how to migrate unstructured content from a web page to one or more SQL Server tables. Our company uses SQL Server as its primary data store, and we are beginning to use Python more for application development work. Therefore, demonstrate using Python along with BeautifulSoup to mine data from web pages. Move on to the next step of mining by reading and transforming the unstructured content in the files written by Python from web pages with T-SQL.
Solution
Over the past several years, I have been mining MSSQLTips.com to retrieve and display content at the site. This is partly because I am a regular contributor to the site, and I wanted a way of tracking my contributions. This tip is based on the thought that others may like to perform the same techniques for tracking content by their favorite authors at MSSQLTips.com and other sites. My first two tips on web page mining (Web Screen Scraping with Python to Populate SQL Server Tables | Scraping HTML Tables with Python to Populate SQL Server Tables) convinced me that scraping and using content embedded in HTML on web pages could be a challenging undertaking for a SQL Server professional with limited exposure to web page construction and no in-depth knowledge about the layout of a website. Additionally, webmasters for different websites have various options for designing and populating websites with content.
After my two initial attempts at mining web pages, I took a step back and focused on the basics of how to extract, navigate, and display content from a web page with Python and a third-party Python library known as BeautifulSoup. The third-party library is one of several that facilitate scraping web pages with HTML content. Using a tool such as BeautifulSoup substantially simplifies extracting web content in HTML elements from a site, no matter how it is designed. This is because BeautifulSoup with Python can readily navigate and filter the content on a web page, and Python lets you save the filtered content to a file for storage and additional processing by any other application, such as SQL Server.
- My first tip on the basics of Python and BeautifulSoup (Screen Scraping with Python and BeautifulSoup Code Examples) reviewed how to get Python and BeautifulSoup for free as well as how to use the software for visually examining the content embedded HTML elements on a web page without a web browser. For example, the tip examines the structure of my author page at the MSSQLTips.com site (https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/).
- My second back-to-basics tip "How to use Python and BeautifulSoup to Screen Scrape a Web Page and Store in SQL Server" demonstrates how to track and extract programmatically web page content within several different types of HTML elements, including div, table, and anchor elements. This second back-to-basics tip also presents Python code samples for navigating through and filtering the content of a page for extraction to a text file.
The current tip builds upon the four preceding tips to equip you for writing to a file filtered segments of content from a web page. Additionally, this tip illustrates how to read and process the filtered segments for inclusion in two SQL Server tables. The HTML elements are for two complementary sets of anchor tags. One set of tags points directly at all my MSSQLTips.com tips, and the other set of tags points at additional MSSQLTips.com articles that can provide helpful background information related to each of my tips.
Extracting Content to a File from a Web Page with Python and BeautifulSoup
The main purpose of the Python script in this section is to create two text files based on content in the Tips section of an author profile web page. The URL for the author profile page for the demonstration in this tip is https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/; similar profile pages exist for other contributors to MSSQLTips.com. For example, the author profile pages for the two founders of MSSQLTips.com are https://www.mssqltips.com/sqlserverauthor/38/jeremy-kadlec/ and https://www.mssqltips.com/sqlserverauthor/37/greg-robidoux/. A complete list of MSSQLTips.com contributors appears at https://www.mssqltips.com/sql-server-mssqltips-authors/. By referencing an author's profile page, you can collect information about the contributions of that author. As of the time this tip is prepared, there are about 250 contributors listed on the sql-server-mssqltips-authors page.
The two files created in the following script list all the published tips I authored (Rick Dobson) as of the time this tip was prepared. One file is for a set of hyperlinks pointing at individual tips that I wrote. The other file is for a set of related category hyperlinks for each tip I authored. Readers can refer to the category page hyperlink for a tip to obtain links for related tips from MSSQLTips.com. The role of the two files is to transfer content from the tip and category hyperlink pages to SQL Server.
There are five major segments to the Python script in this section. A row of Python line comment markers (###...) separates segments from one another. The script also includes an instance of Python block comment markers ("""…""") to facilitate the commenting out a section of code consisting of more than one line. Line and block comment markers in Python scripts operate similarly to line and block comment markers in T-SQL scripts.
- The first segment has two main parts – one for referencing libraries
and a second for creating a soup object.
- The requests and os libraries are core libraries that install with a standard Python installation. The BeautifulSoup library is an external library that you can install to facilitate working with web pages. The BeautifulSoup library can be installed for use with Python through pip, which is a package manager supported by Python.org for packages that are not part of Python core libraries.
- The soup object is created in the last line of the first segment. This object can be manipulated by other segments to extract information from a web page. In the example below, myURL points to the web page processed by the remainder of the script. The get method in the requests library is used to request data from a web server. In the example below, that data is the HTML for a web page. The BeautifulSoup function below translates the content returned by the get method to a parsed tree that facilitates reading, navigating, and extracting HTML elements via Python code.
- The second segment performs two essential functions and allows the performance
of an optional task.
- The first essential function is the assignment to the div_tag list object of the div element in the soup object with an id attribute of Tips
- The second essential function is to extract all anchor elements from the div_tag list object into another list object named Tips_div_anchor_tags. HTML denotes hyperlinks with anchor elements (often called anchor tags). As of the time this tip is prepared, there are 352 anchor elements in Tips_div_anchor_tags. Each freshly published tip adds a new pair of anchor elements to the Tips_div_anchor_tags list object
- The code for the optional task appears within block comment markers that are commented out (#"""…#"""). If you remove the comment line marker (#) preceding the beginning and ending block comment markers, the optional task will run; otherwise, the optional code will not run. The optional code iterates through all the anchor tags in Tips_div_anchor_tags, and it successively prints each anchor tag to a default output window, such as the IDLE Shell window
- The third segment shows how to perform four functions for the category anchor
tags in Tips_div_anchor_tags
- The first statement starts with the 0th anchor element and iterates through every anchor with an even index value within Tips_div_anchor_tags. The iterated elements are assigned to the category_anchors list object because these are anchor elements for category hyperlinks
- The len function in the second statement assigns the count of the category hyperlinks to category_anchor_count
- The third statement invokes the print function to display the category_anchor_count value
- The fourth statement iterates through and successively prints the list items in category_anchors
- The fourth segment performs the same kind of functions as the third segment
for the anchor elements pointing at tip hyperlinks
- The tip anchor elements have odd index values starting at 1 within Tips_div_anchor_tags. The tip anchor elements are saved in tip_anchors
- This segment computes the count of tip anchor elements and saves the result in tip_anchor_count
- The last statement successively prints the list items in the tip_anchors list object
- The main objective of the fifth segment is to save two files to a designated
path.
- The chdir method of the os library assigns a fresh current default directory (cwd). The os.getcwd returns the value of the cwd. Python reads and writes files from this directory.
- Comment lines in this segment describe and reference the Python file
management statements for writing category_anchors and tip_anchors objects,
respectively, to category_anchors.txt and tip_anchors.txt
- The anchor element values are updated with a prefix value of https://www.mssqltips.com
- Also, each anchor element in a file is ended with a new line instruction ("\n")
#Prepared by Rick Dobson for MSSQLTips.com
#reference libraries
import requests
from bs4 import BeautifulSoup
import os
#designate the target page and ready it for processing
#assign a url to myURL
myURL = "https://www.mssqltips.com/sqlserverauthor/57/rick-dobson/"
#get url content
r = requests.get(myURL)
#parse HTML code
soup = BeautifulSoup(r.content, 'html.parser')
#################################################################################
#get all the anchor tag elements in the Tips div
#find the div tag with an id attribute of Tips
div_tag = soup.find("div", id="Tips")
#find all the anchor tags in the Tips div as a list
Tips_div_anchor_tags = div_tag.find_all("a")
#Count all_anchors in the Tips_div_anchor_tags
all_anchor_count = len(Tips_div_anchor_tags)
#"""
#optionally display all extracted anchor tags in the IDLE Shell window
print ()
print ('display all Tips_div_anchor_tags')
print ()
for anchor_tag in Tips_div_anchor_tags:
print(anchor_tag["href"])
print ()
#"""
#################################################################################
#select all the category tag elements from Tips_div_anchor_tags
#count and optionally display category_anchors
category_anchors = [Tips_div_anchor_tags[i] for i in range(0, len(Tips_div_anchor_tags),2)]
#Count and display category_anchors in the Tips_div_anchor_tags
category_anchor_count = len(category_anchors)
print()
print('count of category_anchors', category_anchor_count)
print()
#Display all extracted category_anchors with the web site url
for anchor_tag in category_anchors:
print("https://www.mssqltips.com" + anchor_tag["href"])
#################################################################################
#select all the tip tag elements from Tips_div_anchor_tags
#count and optionally display category_anchors
tip_anchors = [Tips_div_anchor_tags[i] for i in range(1, len(Tips_div_anchor_tags),2)]
#Count and display category_anchors in the Tips_div_anchor_tags
tip_anchor_count = len(tip_anchors)
print()
print('count of tip_anchors', tip_anchor_count)
print()
#Display all extracted category_anchors
for anchor_tag in tip_anchors:
print("https://www.mssqltips.com" + anchor_tag["href"])
#################################################################################
# Get the current working directory
cwd = os.getcwd()
print(cwd)
# Change the current working directory
os.chdir("C:/my_py_scripts/my_py_script_outputs")
# Get the new working directory
cwd = os.getcwd()
print(cwd)
# opening a file in write mode
f = open("category_anchors.txt", "w")
# writing into file
for anchor_tag in category_anchors:
f.write("https://www.mssqltips.com" + anchor_tag["href"])
f.write("\n")
# closing file
f.close()
# opening a file in write mode
f = open("tip_anchors.txt", "w")
# writing into file
for anchor_tag in tip_anchors:
f.write("https://www.mssqltips.com" + anchor_tag["href"])
f.write("\n")
# closing file
f.close()
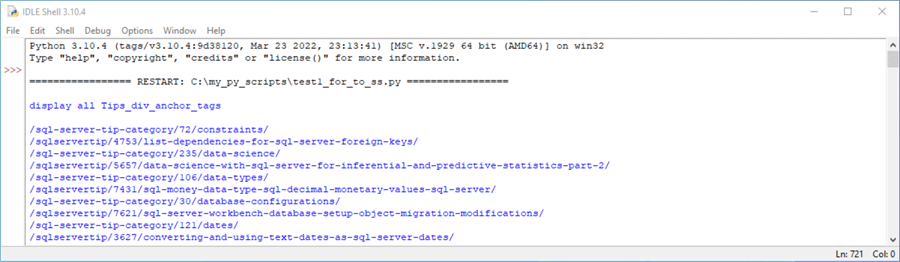
The following screenshot shows an excerpt from the Python print function in the preceding script. The screenshot is an excerpt from the IDLE Shell window.
- IDLE is an integrated development environment for Python code that serves a similar role to SQL Server Management Studio (SSMS) for T-SQL code. You can obtain IDLE from Python.org when you download and install Python from Python.org
- The Shell window for Python code serves a similar role to the Results tab for T-SQL code in SQL Server. When you run a query coded in T-SQL from within SQL Server, its output appears by default in the Results tab. When you run a Python script from an IDLE editor window, its output appears by default in the IDLE shell window
- The excerpt below shows the first ten rows returned by a print function
within a for loop in an optional code block in the second segment of the preceding
script
- The even rows starting with an index of 0 for the first row in the results set are for the first five category hyperlinks
- The odd rows in the results set are for the matching first five tip hyperlinks
The next screenshot is from a NotePad++ session displaying the first five rows of the category_anchors.txt file. This file is created in the fifth segment within the preceding script. The rows in the following screenshot correspond to the even rows in the preceding screenshot, except that each row is prefixed with https://www.mssqltips.com. The prefix is added so the hyperlinks point to the MSSQLTips.com site. The links appearing within the preceding screenshot are already within the MSSQLTips.com site.

The next screenshot is from a NotePad++ session displaying the first five rows of the tip_anchors.txt file. This file is created in the fifth segment within the preceding script. The rows in the following screenshot are derived from the odd rows in the screenshot showing the first ten hyperlinks, except that each row is prefixed with https://www.mssqltips.com. The prefix is added so the hyperlinks point to the MSSQLTips.com site. The links appearing within the screenshot for the first ten hyperlinks are already within the MSSQLTips.com site.

tip_anchors.txt and category_anchors.txt and their Matching Web Pages
As you can see from the preceding two screenshots, the current tip demonstrates the use of Python to return two files. One file contains hyperlinks for each of the tips by an author, and the other file contains hyperlinks for related tips to each tip by an author. Within each set of hyperlinks, there is an id number and a text string to help identify hyperlinks. Additionally, there is an implicit row number within each file. The row number values within each file uniquely identify each hyperlink within a file and allow the matching of hyperlinks between files.
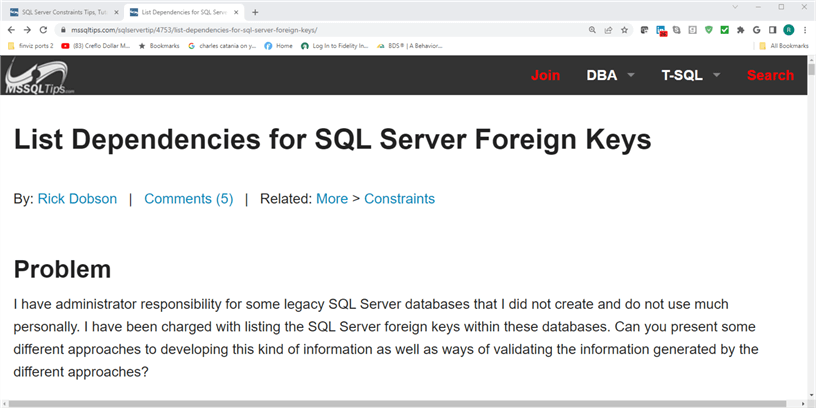
The following two screenshots show a portion of the web pages pointed at by the first hyperlink in each file. The image immediately below is an excerpt from the web page pointed at by the hyperlink in the first line of the tip_anchors.txt file. The first hyperlink in tip_anchors.txt is https://www.mssqltips.com/sqlservertip/4753/list-dependencies-for-sql-server-foreign-keys/. The text string at the end of the hyperlink represents the tip title (List Dependencies for SQL Server Foreign Keys), which shows towards the top of the web page excerpt below. The text in the hyperlink appears with dashes between words in the title. Immediately below the title, you can see three hyperlinks on the web page. Immediately below the hyperlinks is the Problem statement, which indicates an objective for the tip.
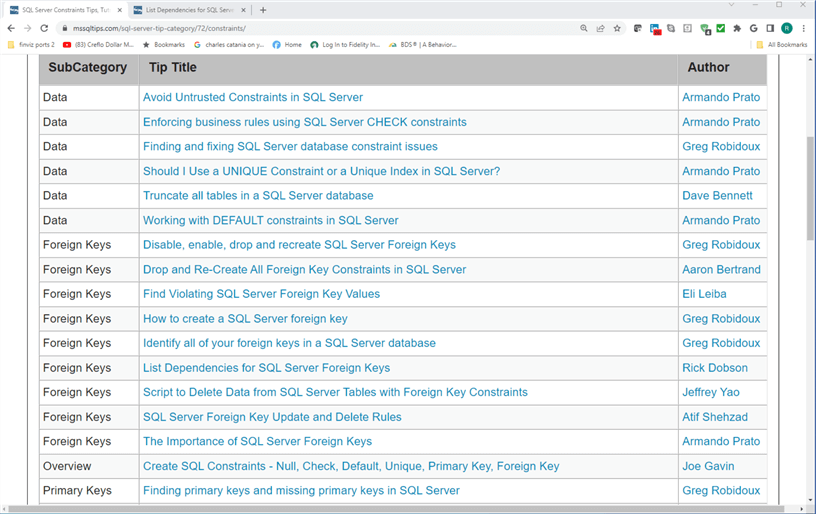
The next screenshot is an excerpt from the web page pointed at by the first hyperlink in the category_anchors.txt file. This hyperlink is https://www.mssqltips.com/sql-server-tip-category/72/constraints/. The excerpt was derived by pasting the hyperlink into a second tab within a browser window. The main part of a category web page consists of three columns for a related subcategory, a related tip title, and an author of the related tip. The following image shows subcategory values of data, foreign keys, overview, and primary keys. There are additional subcategories on the full version of the category web page. The hyperlinks in the tip title column allow you to examine related tips to the corresponding row in the tip_anchors.txt file.
Transferring tip_anchors.txt Lines and Parsing Them for Entry into a SQL Server Table
You can use a T-SQL script like the following one for parsing the contents of the tip_anchors.txt file and transferring its contents into a SQL Server table. This tip divides the overall script into eight major segments.
- The first segment starts with a comment line having the text: set-up for
processing [tip id] and tip_text. Here's a brief description of
the lines of code in the segment
- A use statement specifies a default database in which the script operates. Because of the script's reliance on a txt file for input and temp files for intermediate results sets, you can readily change the default database from HTML_from_MSSQLTips_dot_com to any other one of your preference. The final output table is named [dbo].[tip links]; this table will reside in the default database that you specify in the use statement
- Next, the first segment creates two tables named
- [dbo].[tip links]
- #temp
- The [dbo].[tip links] table will be populated with the hyperlinks as well as parsed elements from the hyperlinks in the tip_anchors.txt file
- The #temp table is respecified and reused multiple times throughout the script. The first segment creates the #temp table for use in the second and third segments
- The second segment uses a bulk insert statement to import the tip_anchors.txt file into the #temp table. A trailing select statement optionally echoes the values imported into the #temp table
- The third segment finds the position of slashes (/) in the tip_link column
values of the [dbo].[tip links] table. This portion of the script searches
for the position of four slashes trailing .com. These four slashes delimit
fields embedded in the tip_link column values. The select statement for
successive slashes is used to extract delimited values in a row's hyperlink
- The text between the first and second slashes is always sqlservertip. This text labels the hyperlink value as a tip hyperlink as opposed to a category hyperlink
- The text between the second and third slashes denotes a numeric value, which points to the tip id value for the hyperlink on the current row
- The text between the third and fourth slashes reveals a string field value for the tip pointed at by the hyperlink on the current row
- The fourth segment uses an insert into statement to transfer a results set from a select statement to the tip_link column of the [dbo].[tip links] table. This syntax is especially useful when importing a large number of rows into a table because it minimizes logging and consequently performs faster and uses less (logging) storage than other insert statements. Because the [dbo].[tip links] row_num column has its identity property set, the third segment also indirectly populates the row_num column based on the identity property setting. The fourth segment concludes with a select statement to reveal the values in the [dbo].[tip links] table as of that point in the script.
- The fifth segment re-specifies the #temp table with a create table statement.
The new specification includes two columns named row_num and [tip id].
The fifth segment populates the fresh version of the #temp table based on the
[dbo].[tip links] table
- For example, the row_num column values are derived from the row_num column values of the [dbo].[tip links] table
- The [tip id] column values are derived via a substring function where
- the expression parameter value is the tip_link column value for the current row in the [dbo].[tip links] table
- the start parameter value is a field labeled [start of [tip id]]]
- the length parameter value is the difference between the [one after end of tip id]]] field less the [start of [tip id]]] field
- The start and length parameter values are based on code in the fourth segment of this script
- The sixth segment uses an update statement to revise the [tip id] column
values in the [dbo].[tip links] table. A select statement after the update
statement displays the revised [dbo].[tip links] table
- The set statement within the update statement assigns the [tip id] column value from the #temp table to the [tip id] column value in the [dbo].[tip links] table
- The two tables are matched by their row_num column values
- The seventh segment re-specifies the #temp table with a create table statement. The new specification includes two columns named row_num and tip_text. This segment populates a fresh version of the #temp table based on the [dbo].[tip links] table
- The eighth segment uses an update statement to revise tip_text column values in the [dbo].[tip links] table. The segment ends with a select statement after the update statement to display the finally revised [dbo].[tip links] table.
-- Prepared by Rick Dobson for MSSQLTips.com
-- set-up for processing [tip id] and tip_text
use [HTML_from_MSSQLTips_dot_com]
go
-- create a fresh version of [dbo].[tip links]
drop table if exists [dbo].[tip links]
drop table if exists #temp
go
-- create a fresh [dbo].[tip links]
create table [dbo].[tip links] (
row_num int identity(1,1),
tip_link varchar(200),
[tip id] int,
tip_text varchar(150)
)
go
-- create a fresh #temp
-- and populate it with tip_anchors.txt from Python script
create table #temp(
hyperlink_text varchar (200)
)
go
------------------------------------------------------
-- bulk insert tip_anchors.txt into #temp
bulk insert #temp
from 'C:\my_py_scripts\my_py_script_outputs\tip_anchors.txt'
with
(
fieldterminator = ',',
rowterminator = '\n'
)
-- optionally echo #temp
select hyperlink_text from #temp
------------------------------------------------------
-- code to find the position of slashes in tip_link
-- within [dbo].[tip links]
-- [tip id] is between 2nd and 3rd slashes
-- tip_text is between 3rd and 4th slashes
select
row_num
,tip_link
,charindex('.com',[tip_link]) [start for .com]
,charindex('/'
,[tip_link]
,charindex('.com',[tip_link])+1) [position of 1st slash]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('.com',[tip_link])+1)+1) [position of 2nd slash]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link],charindex('.com',[tip_link])+1)+1)
+1) [position of 3rd slash]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link],charindex('.com',[tip_link])+1)+1)+1)
+1) [position of 4th slash]
from [dbo].[tip links]
------------------------------------------------------
-- insert hyperlink_text from #temp
-- into tip_link from [dbo].[tip links]
insert into [dbo].[tip links] (tip_link)
select hyperlink_text from #temp
-- optionally display fresh version of [dbo].[tip links]
select * from [dbo].[tip links]
------------------------------------------------------
-- code to create a fresh version of #temp with
-- row_num and [tip id] columns
drop table if exists #temp
-- create #temp
-- and populate it with row_num from [dbo].[tip links]
-- and computed [tip id values]
create table #temp(
row_num int,
[tip id] int
)
go
-- populates computed [tip id] column and insert in #temp
insert into #temp(row_num, [tip id])
-- use substring function to compute [tip id]
select
row_num
,substring(
tip_link
,(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('.com',[tip_link])+1)+1)+1) -- [start of [tip id]]]
,(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('.com',[tip_link])+1)+1)+1)) -- [one after end of tip id]]]
-
(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('.com',[tip_link])+1)+1)+1) -- [start of [tip id]]]
) [tip id]
from [dbo].[tip links]
------------------------------------------------------
-- update [dbo].[tip links].[tip id] with #temp.[tip id]
-- on matching row_num values between [dbo].[tip links] and #temp
update [dbo].[tip links]
set [tip id] = #temp.[tip id]
from #temp
where dbo.[tip links].row_num = #temp.row_num
-- echo dbo.[tip links] with updated [tip id] column
select * from dbo.[tip links]
-- code to create a fresh version of #temp with
-- row_num and [tip_text] columns
drop table if exists #temp
-- create #temp
-- and populate it with row_num from [dbo].[tip links]
-- and computed tip_text values
create table #temp(
row_num int,
tip_text varchar(150)
)
go
-- populate #temp for row_num and [tip_text]
-- populates computed [tip id] column and insert in #temp
insert into #temp(row_num, tip_text)
-- use substring function to compute [tip id]
select
row_num
,substring(
tip_link
,(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link],charindex('.com',[tip_link])+1)+1)+1)+1) -- [start of tip_text]
,(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('.com',[tip_link])+1)+1)+1)+1)) -- [one after end of tip_tex]
-
(charindex('/',[tip_link]
,charindex('/',[tip_link]
,charindex('/',[tip_link],charindex('.com',[tip_link])+1)+1)+1)+1) -- [start of tip_text]
) [tip_text]
from [dbo].[tip links]
-- #temp after insert into from row_num and computed [tip_text]
select * from #temp
------------------------------------------------------
-- update [dbo].[tip links].[tip_text] with #temp.[tip_text]
-- on matching row_num values between [dbo].[tip links] and #temp
update [dbo].[tip links]
set [tip_text] = #temp.tip_text
from #temp
where dbo.[tip links].row_num = #temp.row_num
-- display dbo.[tip links] with updated [tip id] column
select * from dbo.[tip links]
The following table displays five results set excerpts from the preceding script. The header section for each results set excerpt indicates the segment of the script that generates a results set.
- The first results set is generated by the second segment in the preceding script. This results set excerpt shows the first eight hyperlinks from the #temp table. The full set of hyperlink_text column values are derived from the tip_anchors.txt file
- The second results set, which comes from the third segment in the preceding script, shows the [tip links] table after it is populated by the hyperlink_text column from the #temp table. At the time of the screenshot, the [tip id] and tip_text column values are null because no parsing is implemented yet to populate these derived values that populate these columns
- The third results set returns the position of slash values in the tip_link column of the [link tips] table. This results set comes from the fourth section in the preceding script. The position values for slashes facilitate the parsing of [tip id] and tip_text column values in the [link tips] table
- The fourth results set shows a view of the [link tips] table after the population of the tip_id column. The fifth and sixth code segments achieve this outcome
- The fifth results set shows a view of the [link tips] table after the population of tip_text column. The seventh and eighth code segments achieve this outcome
Second segment results set excerpt

Third segment results set excerpt

Fourth segment results set excerpt

Sixth segment results set excerpt

Eighth segment results set excerpt

Parsing and Displaying Category Link Values
The technique in the preceding section can be adapted for parsing and displaying any set of hyperlinks in a txt file. This section presents a simpler, less elaborate approach to processing anchor tag elements on a web page. The approach is implemented for the anchor tags pointing at category pages for tip pages by an author at MSSQLTips.com. Excerpts from a sample category link page and its matching tip page appear in the "tip_anchors.txt and category_anchors.txt and their matching web pages" section.
The category anchor hyperlinks are persisted in a file named category_anchors.txt by the Python script in the "Extracting content to a file from a web page with Python and BeautifulSoup" section. The category hyperlinks appear in the same order as the tip hyperlinks. Also, each category hyperlink contains both a [cat id] value and some text naming the category (referred to as category_text in results).
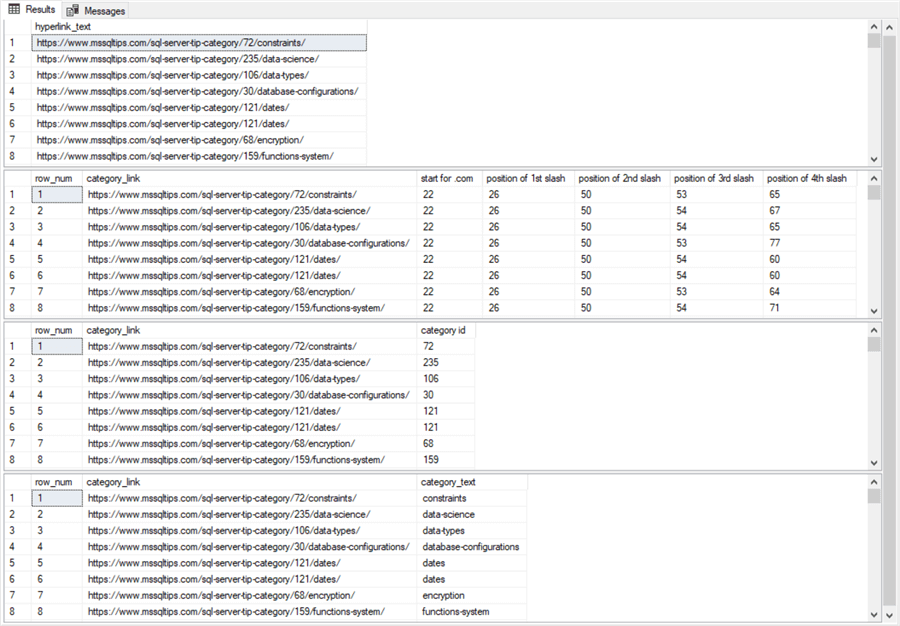
Perhaps the best place to start conveying the highlights of the new approach presented in this section is to show the results sets generated by the T-SQL script for parsing and displaying category hyperlink values. The following screenshot excerpts the first eight rows from the four results sets generated by the T-SQL script to parse and display category hyperlink values.
- The first results set excerpt displays the category hyperlink_txt column values after they are read from the category_anchors.txt file to the #temp table
- The second results set displays the positions of slashes in the category_link
column of the [category links] table
- The [category links] table can be specified with the same general design as the [tip links] table in the preceding section. This is to stress the basic similarity of the design of the approaches implemented in this section and the preceding section. However, only two of the four columns in the [category links] table are required for the approach described in this section.
- The category_link column in the [category links] table is populated based on the hyperlink_text column values from the #temp table.
- Because of an identity property setting for the row_num column in the [category links] table, the row_num column value for each new row inserted into the [category links] table increases by 1 starting at 1
- The third results set displays the category_link column values and [category id] column values from a select statement based on the [category links] table
- The fourth results set displays category_link column values and category_text column values from another select statement based on the [category links] table
The third and fourth results sets are not persisted into a SQL Server table. In addition, [category id] and category_text column values are not available from a single table as in the example from the preceding section. Instead, a separate select statement must be run for each set of column values.
The following script presents the T-SQL to implement the simplified code for returning [category id] and category_text column values embedded in the category_link column of the [category link] table. There are about 188 lines of code in the preceding tip section and just 127 lines of code in the current section. In general, the fewer the lines of code, the easier it is to follow the code in a script. By this rule, the current script is a lot easier to follow. Also, the logic in this solution is more straightforward than in the preceding section. For example, this section does not include update statements, as does the preceding section.
- The script for this section starts with a set-up section for creating the
[category links] and #temp tables. Notice that two column declarations
are commented out in the [category links]. This achieves two goals
- The fact that the two commented column declarations can be retained (by removing their preceding comment line markers) indicates the similarity between the script for this section and the script for the preceding section
- The fact that the two lines are commented out of the script for this section highlights the simplicity of the solution for this section relative to the preceding section
- Next, a bulk insert statement populates the #temp table from the category_anchors.txt file
- Then, the #temp file is inserted into the [category links] table; this process also updates indirectly the row_num column values in the [category links) table
- The next block of code shows the T-SQL for finding the position of the last four slashes in the [category link] column of the [category links) table. These position values facilitate extracting [category id] and category_text values from the [category links] table.
- The next-to-the-last select statement returns the row_num and category_link column values from the [category links] table along with the computed [category id] column values in its results set. A substring function computes the [category id] column values
- The last select statement returns the row_num and category_link column values from the [category links] table along with the computed category_text column values in its results set. A substring function computes the category_text column values
-- Prepared by Rick Dobson for MSSQLTips.com
use [HTML_from_MSSQLTips_dot_com]
go
-- create a fresh version of [dbo].[category links]
drop table if exists [dbo].[category links]
drop table if exists #temp
go
-- create [dbo].[category links]
create table [dbo].[category links] (
row_num int identity(1,1),
category_link varchar(200),
--[category id] int,
--category_text varchar(50)
)
go
-- create #temp
-- and populate it with category_anchors.txt from Python
create table #temp(
hyperlink_text varchar (200)
)
go
-- bulk insert into #temp from category_anchors.txt
bulk insert #temp
from 'C:\my_py_scripts\my_py_script_outputs\category_anchors.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
)
-- optionally echo #temp
select hyperlink_text from #temp
-- insert hyperlink_text from #temp
-- into category_link from [dbo].[category links]
insert into [dbo].[category links] (category_link)
select hyperlink_text from #temp
-- code to find the position of slashes in category_link
-- within [dbo].[category links]
-- [category id] is between 2nd and 3rd slashes
-- category_text is between 3rd and 4th slashes
select
row_num
,category_link
,charindex('.com',[category_link]) [start for .com]
--,charindex('.com'
--,[category_link])+1 [start of 2nd search]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1) [position of 1st slash]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1) [position of 2nd slash]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link],charindex('.com',[category_link])+1)+1)
+1) [position of 3rd slash]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link],charindex('.com',[category_link])+1)+1)+1)
+1) [position of 4th slash]
from [dbo].[category links]
-- substring function to extract [category id]
select
row_num
,category_link
,substring(
category_link
,(charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1) -- [start of [category id]]]
,(charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1)) -- [one after end of category id]]]
-
(charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1) -- [start of [category id]]]
) [category id]
from [dbo].[category links]
-- substring function for [category_text]
select
row_num
,category_link
,substring(
category_link
,(charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1)+1) -- [start of [category_text]]]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1)+1) -- [one after end of category_text]]]
-
(charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('/',[category_link]
,charindex('.com',[category_link])+1)+1)+1)+1) -- [start of [category_text]]]
) [category_text]
from [dbo].[category links]
Next Steps
The main thrust of this tip is to confirm that you can relatively easily extract unstructured web content from a web page with BeautifulSoup and Python. The content in this example includes a set of alternating hyperlinks for tips by an author and category pages for tips by an author. The data are unstructured because anchor tags for the hyperlinks are not in a table. Additionally, no id value for category pages links them to anchor tags for tips. Instead, the correspondence between tip anchor tags and category anchor tags is indicated by the relative position of the two tag types within an HTML div tag. BeautifulSoup and Python make it relatively easy to extract the tip and category hyperlinks into two separate txt files that have the same order so that the row order for the tip hyperlink file matches the row order for the category hyperlink file.
The second part of the tip shows how to read and parse the tip and category hyperlink files in T-SQL. In fact, two different T-SQL approaches are shown for implementing the reading and parsing of the tip hyperlink files. Each approach has its advantages and disadvantages. When extracting unstructured data from web pages, you should pick the approach that best matches your requirements and personal T-SQL programming style. Alternatively, you can modify the approaches in this tip to develop your own solution for extracting content from web pages.
For MSSQLTips.com authors and devoted MSSQLTips.com readers, one obvious next step is to build your own dataset of MSSQLTips.com tips, categories, and authors. Beyond this next step, you can adapt the approach in this tip to other websites with other kinds of data. An important point to keep in mind is that you will need to develop a strategy for gathering unstructured data from one or more web pages that allows you to build a dataset or even a whole database in SQL Server from a collection of web pages.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-11-20
